Xiaobai'den Master'a: Karar Ağacının Sınıflandırılması ve Regresyon Analizi

Karar vermek için, iç içe geçmiş bir dizi konunun dikkate alınması gerekir. Resim kaynağı: pexels.com
Karar ağacı, özellikler aracılığıyla karar kurallarını öğrenen ve hedefleri tahmin etmek için kullanılan denetimli bir makine öğrenimi modelidir. Adından da anlaşılacağı gibi, model karar vermek için bir dizi soru sorarak verileri ayrıştırır.
Aşağıdaki örnekte, belirli bir günün faaliyetlerini belirlemek için bir karar ağacı kullanılmıştır:
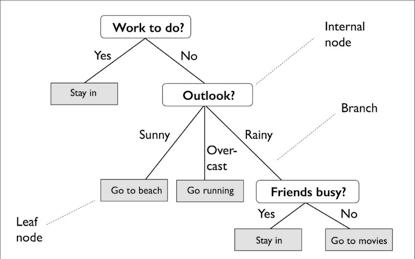
Eğitim setinin özelliklerine göre, karar ağacı modeli, örneğin sınıf etiketini çıkarmak için bir dizi soru öğrenir. Şekilde, yorumlanabilirlik önemli bir faktör ise, karar ağacı modelinin iyi bir seçim olduğu görülebilir.
Yukarıdaki şekil, bir sınıflandırma hedefine (sınıflandırma) dayalı bir karar ağacı kavramını gösterse de, hedef gerçek bir sayı ise, o da kullanılır (regresyon).
Bu eğitim, Python'un scikit-learn kütüphanesini kullanarak bir karar ağacı modelinin nasıl oluşturulacağını tartışacaktır. Bunlar şunları içerecektir:
· Karar ağaçlarının temel kavramları
· Karar ağacı öğrenme algoritmasının arkasındaki hesaplama
· Bilgi kazancı ve safsızlık önlemleri
· Sınıflandırma ağacı
· Regresyon ağacı
Hadi başlayalım!
Bu eğitim, Next Tech'in Python makine öğrenimi serisine referansla yazılmıştır. Bu seri, öğrencilerin Python aracılığıyla makine öğrenimi ve derin öğrenme algoritmalarını anlamalarına ve acemilikten ustaya geçişi gerçekleştirmelerine yol açar. Önceden yüklenmiş tüm gerekli yazılım ve kitaplıkların yanı sıra genel veri kümelerini kullanan projeleri içeren tarayıcı modu sanal alan ortamını içerir.
Portal: https://c.next.tech/2E7k6Dy

Karar ağacı, özyinelemeli bölme ile oluşturulur - kök düğümden (ana düğüm olarak da adlandırılır) başlayarak, her düğüm sol ve sağ çocuk düğümlere bölünür. Bu düğümler ayrıca diğer alt düğümlere ayrılabilir.
Örneğin, yukarıdaki şekilde, kök düğüm İş yapılacak mı? Şeklindedir ve ardından tamamlanması gereken faaliyetler olup olmadığına bağlı olarak Kalacak ve Outlook alt düğümlerine bölünmüştür. Outlook düğümü, üç alt düğüme bölünmeye devam eder.
Öyleyse, her düğümün en iyi bölünme noktası nasıl belirlenir?
Kök düğümden başlayarak, veriler maksimum bilgi kazancını (IG) üreten özelliğe bölünür (aşağıda daha ayrıntılı olarak açıklanmıştır). Yinelemeli süreçte, bölme işlemi, tüm yapraklar saflığa ulaşana kadar, yani her düğümün örnekleri aynı sınıfa ait olana kadar her çocuk düğümde tekrarlanmaya devam edecektir.
Uygulamada, çok fazla düğümü olan bir ağaç oluşabilir ve bu da aşırı uyuma neden olabilir. Bu nedenle budama genel olarak ağacın maksimum derinliği sınırlandırılarak yapılır.
Düğümü en bilgilendirici özellikte bölmek için, ilk önce ağaç öğrenme algoritması tarafından bir amaç işlevi tanımlanmalı ve optimize edilmelidir. Burada amaç, aşağıdaki gibi tanımlanan her bölünmüş noktada maksimum bilgi kazancını elde etmektir:
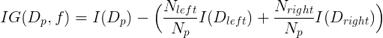
Denklemde, f, bölme gerçekleştirme özelliğidir ve Dp, Dleft ve Dright sırasıyla üst ve alt düğümlerin veri kümeleridir. I, safsızlık ölçüsüdür, Np, ana düğüm üzerindeki toplam örnek sayısıdır ve Nleft ve Nright, alt düğümdeki örneklerin sayısıdır.
Aşağıdaki örnekte, bu makale, sınıflandırma ve regresyon karar ağaçları için kullanılan safsızlık önlemlerini daha ayrıntılı olarak tartışacaktır. Ama şimdi, bilgi kazancının sadece ana düğümün safsızlığı ile çocuk düğümün safsızlığının toplamı arasındaki fark olduğunu anlayın.Çocuk düğümün safsızlığı ne kadar düşükse, bilgi kazancı o kadar büyük olur.
Yukarıdaki denklemin yalnızca ikili karar ağaçları için geçerli olduğunu, yani her bir ana düğümün iki alt düğüme bölündüğünü unutmayın. Bir karar ağacı ikiden fazla düğüm içeriyorsa, yalnızca tüm düğümlerin safsızlığının toplamı gereklidir.
Önce sınıflandırma karar ağaçlarını tartışın (sınıflandırma ağaçları da denir). Aşağıdaki örnek, makine öğrenimi alanında klasik bir veri kümesi olan Fisher iris veri kümesini kullanacaktır. Setosa, Versicolor ve Virginica olmak üzere üç farklı türden 150 iris çiçeğinin özelliklerini içerir. Bunlar, bu kitabın hedefleri olacak. Bu örnek, belirli bir iris çiçeğinin hangi kategoriye ait olduğunu tahmin etmeyi amaçlamaktadır. Petal uzunluğunu ve genişliğini (santimetre cinsinden), veri kümesinin özellikleri olarak da adlandırılan sütunlar olarak kaydedin.
Veri kümesi portalı: https://archive.ics.uci.edu/ml/datasets/iris
Önce veri kümesini içe aktarın ve özelliği x ve hedefi y olarak ayarlayın:
sklearn ithal veri kümelerinden iris = datasets.load_iris () # iris veri setini yükle X = iris.data # X matrisi atayın y = iris.target #A vektör yScikit-learn'ü maksimum 4 derinliğe sahip bir karar ağacı eğitmek için kullanın. kod aşağıdaki gibi gösterilir:
sklearn.tree'den DecisionTreeClassifier # Karar ağacı sınıflandırıcı modelini içe aktar tree = DecisionTreeClassifier (criterion = 'entropy', # Initialize ve fitclassifier max_depth = 4, random_state = 1) tree.fit (X, y)Kriterin burada "entropi" olarak ayarlandığını unutmayın. Bu standart, safsızlık ölçüsü olarak adlandırılır (yukarıda belirtilmiştir). Sınıflandırmada entropi, en yaygın safsızlık ölçüsü veya bölme kriteridir. Aşağıdaki gibi tanımlanır:
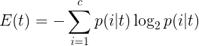
Denklemde, p (i | t), belirli bir t düğümündeki c-tipi numunenin parçasıdır. Bu nedenle, bir düğümdeki tüm örnekler aynı sınıfa aitse, entropi değeri 0'dır; türler tekbiçimli dağıtılmışsa, entropi değeri en büyüktür.
Entropiyi daha sezgisel olarak anlamak için, sınıf 1 olasılık aralığının safsızlık endeksi buraya yazılmıştır. kod aşağıdaki gibi gösterilir:
numpy'yi np olarak içe aktar matplotlib.pyplot dosyasını plt olarak içe aktar def entropi (p): return-p * np.log2 (p) - (1- p) * np.log2 (1-p) x = np.arange (0.0, 1.0, 0.01) # Sahte veri oluştur e = # Entropiyi hesapla plt.plot (x, e, label = 'entropy', color = 'r') # Kirlilik indekslerini çizin y için: plt.axhline (y = y, linewidth = 1, color = 'k', linestyle = '-') plt.xlabel ('p (i = 1)') plt.ylabel ('Kirlilik Endeksi') plt.legend () plt.show ()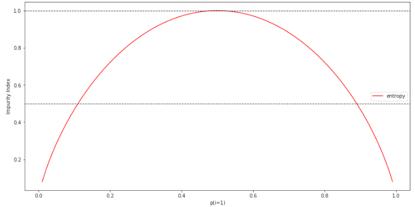
Gördüğünüz gibi p (i = 1 | t) = 1 olduğunda entropi değeri 0'dır. Tüm türler eşit olarak dağıtıldığında ve p (i = 1 | t) = 0,5 olduğunda, entropi değeri 1'dir.
Şimdi iris örneğine dönersek, bu makale eğitimli sınıflandırma ağacını görselleştirecek ve entropi değerinin her bölünmeyi nasıl belirlediğini gözlemleyecektir.
scikit-learn, kullanıcıların karar ağacını eğitimden sonra bir .dot dosyası olarak dışa aktarmalarına olanak tanıyan ve daha sonra GraphViz gibi yazılımlar kullanılarak görselleştirilebilen güzel bir özelliğe sahiptir. GraphViz'e ek olarak, pydotplus adlı bir Python kütüphanesi kullanılacaktır. GraphViz'e benzer bir işlevi vardır ve .dot veri dosyalarını karar ağacı görüntü dosyalarına dönüştürebilir.
Pydotplus ve graphviz'i kurmak için terminalde aşağıdaki komutları uygulayın:
pip3 pydotplus'ı kurun apt yüklemek graphvizAşağıdaki kod, bu örneğin karar ağacı görüntüsünü PNG formatında oluşturabilir:
pydotplus.graphviz'den import graph_from_dot_data sklearn.tree'den import export_graphviz dot_data = export_graphviz (# Nokta verisi oluştur ağaç dolu = Doğru, yuvarlak = Doğru, class_names =, feature_names =, out_file = Yok ) graph = graph_from_dot_data (dot_data) # Nokta verilerinden grafik oluştur graph.write_png ('tree.png') # PNG resmine grafik yaz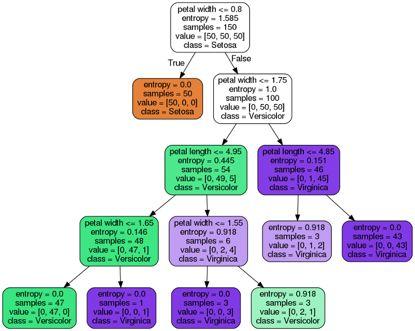
tree.png
Tree.png görüntü dosyasının bulunduğu karar ağacı grafiğinden, eğitim verilerine dayanan karar ağacının bölünme noktaları gözlemlenebilir. Kök düğümde 150 örnekle başlayın ve ardından taç yaprağı genişliğinin bölünme noktası olarak 1,75 cm veya daha az olmasına bağlı olarak her biri 50 ve 100 örnek içeren iki alt düğüme bölün. İlk bölünmeden sonra, sol alt düğümün saflığa ulaştığı ve sadece setosa sınıfının örneklerini (entropi = 0) içerdiği görülebilir. Sağ taraf daha da bölünmüş ve örnekler çok renkli ve virginica kategorilerine ayrılmıştır.
Son entropiden 4 derinliğe sahip karar ağacının çiçekleri sınıflandırmada iyi performans gösterdiği görülmektedir.
Regresyon ağacı örneği Bu makale Boston Housing veri kümesini kullanacaktır. Bu, Boston cemaatinin evleri hakkında bilgi içeren çok popüler bir başka veri kümesidir. 506 örnek ve 14 özellik vardır. Basitleştirme ve görselleştirme uğruna, burada sadece iki özellik kullanılacaktır, yani hedef olarak MEDV (ev sahibinin evinin medyan değeri, birim 1.000 $) ve özellik olarak LSTAT (düşük statülü nüfus oranı).
Veri kümesi portalı:
https://www.cs.toronto.edu/~delve/data/boston/bostonDetail.html
İlk olarak, scikit-learn'deki gerekli öznitelikleri pandalar veri çerçevesi DataFrame'e aktarın.
pandaları pd olarak içe aktar sklearn ithal veri kümelerinden boston = datasets.load_boston () # Boston Veri Kümesini Yükle df = pd.DataFrame (boston.data) # Yalnızca LSAT özelliğini kullanarak DataFrame oluşturun df.columns = df = boston.target # targetMEDV ile yeni sütun oluşturun df.head ()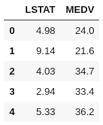
Regresyon ağacını eğitmek için scikit-learn'deki DecisionTreeRegressor aracını kullanın:
from sklearn.tree import DecisionTreeRegressor # Karar ağacı regresyon modelini içe aktar X = df.values # Matris X atayın y = df.values # y vektörünü atayın sort_idx = X.flatten (). argsort () # X ve y'yi X'in artan değerlerine göre sıralayın X = X y = y tree = DecisionTreeRegressor (criterion = 'mse', # Regresörü başlat ve sığdır max_depth = 3) tree.fit (X, y)Buradaki kriterin, sınıflandırma ağacında kullanılandan farklı olduğuna dikkat edin. Sınıflandırmada entropi, safsızlığın bir ölçüsü olarak faydalı bir kriterdir. Bununla birlikte, karar ağacı regresyon için kullanılıyorsa, sürekli değişkenler için uygun bir safsızlık ölçüsü gereklidir, bu nedenle burada safsızlık ölçüsünü tanımlamak için alt düğümlerin ağırlıklı ortalama kare hatası (MSE) kullanılır:
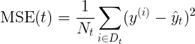
Denklemde, Nt, t düğümünün eğitim numunelerinin sayısıdır, Dt, t düğümünün eğitim alt kümesidir, y (i) gerçek hedef değerdir ve t, tahmin edilen hedef değerdir (örnek ortalama):
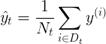
Şimdi, regresyon ağacının doğrusal uyumunun neye benzediğini görmek için MEDV ve LSTAT arasındaki ilişkiyi modelleyin:
plt.figure (figsize = (16, 8)) plt.scatter (X, y, c = 'steelblue', # Özelliklere karşı gerçek hedefi grafiklendirin edgecolor = 'beyaz', s = 70) plt.plot (X, tree.predict (X), # Plot hedefe karşı öngörülen hedef renk = 'siyah', lw = 2) plt.xlabel ('popülasyonun% düşük durumu') plt.ylabel ('1000 $ cinsinden fiyat') plt.show ()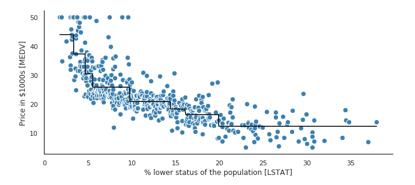
Yukarıdaki şekilden de görülebileceği gibi, derinliği 3 olan bir karar ağacı, verilerin genel eğilimini yansıtabilir.
Bu makale, karar ağaçlarının temel kavramlarını, safsızlığı en aza indirecek algoritmaları ve sınıflandırma ve regresyon için karar ağaçlarının nasıl oluşturulacağını tartışmaktadır.
Uygulamada, verilere aşırı veya yetersiz uymaktan kaçınmak için ağaç için doğru derinliği seçmek önemlidir. Karar ağaçlarının genel bir rastgele orman halinde nasıl birleştirileceğini anlamak da faydalıdır.Rastgele olmasına bağlı olarak, genellikle tek bir karar ağacından daha iyi genelleme performansına sahiptir. Bu, modelin varyansını azaltmaya yardımcı olur. Ek olarak, veri setindeki aykırı değerlere karşı çok hassas değildir ve çok fazla parametre ayarı gerektirmez.

Yorum Beğen Takip Et
Yapay zeka öğrenme ve geliştirmenin kuru mallarını paylaşalım
Tam platform yapay zeka dikey öz medya "temel okuma tekniği" ni takip etmeye hoş geldiniz