2017'de derin öğrenme optimizasyon algoritmalarının en son ilerlemesi: SGD ve Adam yöntemleri nasıl geliştirilir?
Sebastian Ruder tarafından özgün
Wang Xiaoxin ruder.io'dan derlendi
Qubit Üretildi | Genel Hesap QbitAI
Derin öğrenmenin temel amacı, güçlü genelleme yeteneği ile bir minimum bulmaktır.Modelin hızı ve güvenilirliği de bir bonus puan.
Stokastik Gradyan İniş (SGD) Yöntem, 1951'de Robbins ve Monro tarafından önerildi ve 60 yıllık bir geçmişe sahip. Mevcut derin öğrenme araştırmasında, bu yöntem çok önemlidir ve genellikle geri yayılma sürecinde kullanılır.
Son yıllarda araştırmacılar, model parametrelerini güncellemek için farklı denklemler kullanan bazı yeni optimizasyon algoritmaları önerdiler. Kingma ve Ba tarafından 2015 yılında önerildi Adam yöntemi , En yaygın kullanılan optimizasyon algoritmalarından biri olarak kabul edilebilir. Bu, makine öğrenimi çalışanlarının bakış açısından, derin öğrenme optimizasyonundaki en iyi yöntemlerin büyük ölçüde değişmediğini göstermektedir.
Ancak bu yıl önerilen ve model optimizasyonunda kullanılan yöntemleri etkileyebilecek birçok yeni yöntem var. Bu makalede Ruder, derin öğrenme optimizasyon yöntemlerinde bazı heyecan verici çalışmaları ve olası geliştirme yönlerini kendi bakış açısından tanıttı. Bu makaleyi okurken, SGD yöntemi ve Adam yöntemi gibi uyarlanabilir öğrenme hızı yöntemine aşina olun.
Geliştirilmiş Adam yöntemi
Adam gibi uyarlanabilir öğrenme oranı yöntemleri yaygın olarak kullanılsa da, birçok modern araştırma sonucu, nesne tanıma ve makine çevirisi gibi araştırma görevlerinde hala geleneksel momentum SGD yöntemlerini kullanıyor.
Wilson ve arkadaşları, son araştırmada, momentum SGD yöntemiyle karşılaştırıldığında, uyarlanabilir öğrenme hızı yönteminin farklı bir minimuma yaklaşacağını ve sonucun genellikle ideal olmadığını açıklamak için bazı nedenler verdiler. Deneyimlerden, nesne tanıma, karakter düzeyinde dil modelleme ve sözdizimi analizi gibi görevlerde, uyarlamalı öğrenme oranı yöntemiyle elde edilen minimum değerin, momentum SGD yöntemiyle elde edilen minimum değerden genellikle daha kötü olduğu öğrenilmiştir. Adam yöntemi iyi bir yakınsama mekanizmasına sahip olduğundan ve uyarlanabilir öğrenme oranı geleneksel SGD yönteminden daha iyi performans göstereceğinden, bu sezgiye aykırı görünüyor. fakat, Adam ve diğer uyarlanabilir öğrenme oranı yöntemlerinin de bazı sınırlamaları vardır.
Ayrıştırma ağırlığı zayıflaması
Bazı veri setlerinde, Adam yönteminin genelleme yeteneği, momentum SGD yönteminden daha kötüdür. Olası nedenlerden biri, Kilo kaybı . Ağırlık zayıflaması genellikle görüntü sınıflandırma problemlerinde kullanılır; yani, her parametre güncellemesinden sonra zayıflama oranı Wt, ağırlık t ile çarpılır, burada zayıflama oranı Wt 1'den biraz daha azdır:
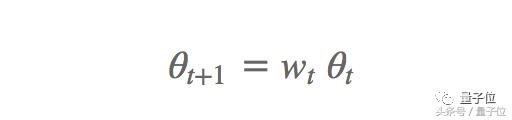
Bu, ağırlığın çok fazla büyümesini engeller. Bu nedenle, ağırlık azalması, Kayıpta uygulanan ağırlık azalma oranına (Wt) bağlı olan bir L2 düzenleme terimi olarak da anlaşılabilir:
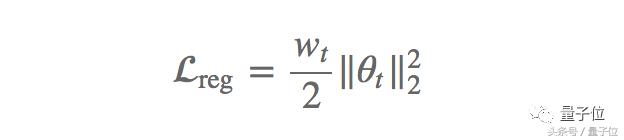
Ağırlık azaltma yöntemi genel olarak yukarıda bahsedilen düzenleme öğesi olarak kullanılabilir veya gradyanı doğrudan değiştirebilir, genellikle birçok sinir ağı kütüphanesinde çağıran işlevler vardır. Momentum ve Adam algoritmasının güncelleme denkleminde, gradyan değeri diğer zayıflatma terimleriyle çarpılarak değiştirildiğinde, ağırlık zayıflaması L2 regülasyonundan farklıdır. Bu nedenle, Loshchilov ve Hutter, 2017'de orijinal tanımla aynı olan "ayrıştırılmış ağırlık azalması" önermiş ve gradyan her parametre güncellemesinden sonra bu yöntemle güncellenmiştir.
Momentum ve ağırlık azalması ile SGD yöntemi (SGDW) gradyanı aşağıdaki şekilde günceller:
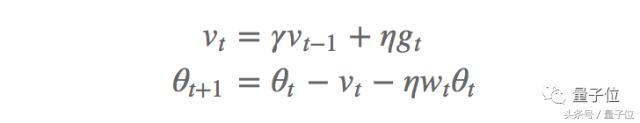
Bunlar arasında, öğrenme oranıdır ve ikinci denklemin üçüncü terimi, ayrıştırıcı ağırlık azalmasıdır. Benzer şekilde, kilo zayıflatmalı Adam yöntemini (AdamW) elde ederiz:
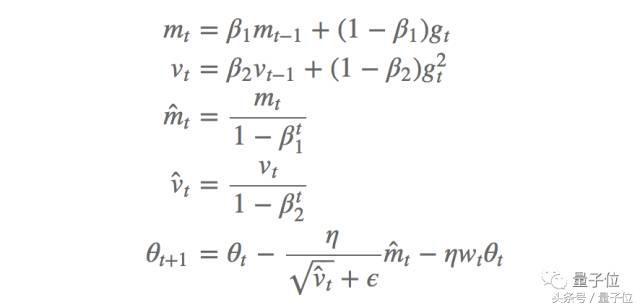
Bunlar arasında mt ve mt ilk seferdeki sapma ve sapma düzeltme tahminleri, vt ve vt ikinci seferdeki sapma ve sapma düzeltme tahminleri, 1 ve 2 karşılık gelen zayıflama oranlarıdır ve aynı ağırlık zayıflatma terimi eklenir. Yazara göre, bu yöntem Adam yönteminin genelleme yeteneğini büyük ölçüde geliştirir ve görüntü sınıflandırma veri setindeki momentum SGD yöntemine eşdeğerdir.
Ayrıca, hiperparametreler artık birbirine bağlı olmadığından, öğrenme hızının seçim sürecini, hiperparametre optimizasyonunu daha iyi gerçekleştirebilen ağırlık zayıflatma seçim sürecinden ayırır. Aynı zamanda optimize edicinin uygulamasını, daha kısa ve tekrar kullanılabilir kod oluşturmaya yardımcı olan ağırlık azalması uygulama sürecinden ayırır, fast.ai AdamW / SGDW uygulamasına (https://github.com/fastai/fastai/) bakın. çekme / 46 / dosyalar).
Sabit üstel hareketli ortalama
Son zamanlarda yapılan bazı çalışmalar (Dozat ve Manning, 2017, Laine ve Aila, 2017) deneyler yoluyla, 2 değerini düşürmenin Adam'ın yönteminde geçmiş kare gradyan üstel hareketli ortalamanın katkısını etkilediğini bulmuştur. Genel olarak konuşursak, 2'nin varsayılan değeri 0,999'dur. 0,99 veya 0,9 olarak ayarlandıktan sonra, farklı görevlerde daha iyi performans gösterir, bu da üstel bir hareketli ortalama problemi olabileceğini gösterir.
ICLR 2018, bu sorunu inceleyen ve geçmişte kare gradyanın üssel hareketli ortalamasının uyarlanabilir öğrenme olduğuna işaret eden On the Convergence of Adam and Beyond (https://openreview.net/forum?id=ryQu7f-RZ) adlı bir makaleyi gözden geçiriyor. Oran yönteminin zayıf genelleme yeteneğinin bir başka nedeni. Uyarlanabilir öğrenme hızı yönteminin özü, Adadelta, RMSprop ve Adam gibi parametreleri, geçmiş kare gradyanın üstel hareketli ortalaması aracılığıyla güncellemektir. Endeksin ortalama katkısı üzerine araştırma Bu fikir çok motive edicidir ve eğitimle öğrenme oranının aşırı derecede küçülmesini önleyebilir Bu aynı zamanda Adagrad yönteminin de önemli bir kusurudur. Bununla birlikte, gradyanın kısa süreli hafızası, diğer durumlarda bir engel haline gelir.
Adam yöntemi alt-optimal çözüme yakınsadığında, bazı küçük örnek gruplarının büyük ve etkili bir bilgi gradyanına katkıda bulunduğunu gözlemliyoruz, ancak bu nadiren oluyor. Üstel ortalamadan sonra, etkileri azaltılarak zayıf model yakınsamasıyla sonuçlanıyor . Yazar, Adam'ın yönteminde görülebilen basit bir dışbükey optimizasyon problemi veriyor.
Yazar, bu problemi çözmek için yeni bir AMSGrad algoritması önermektedir; bu algoritma, önceki üstel ortalama yerine parametreleri güncellemek için geçmişteki kare gradyanın maksimum değerini kullanır. AMSGrad yönteminin güncelleme süreci, önyargı düzeltme tahmini olmaksızın aşağıdaki gibidir:
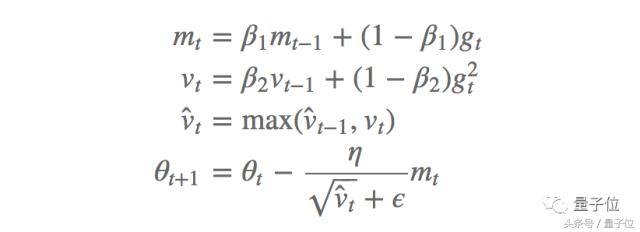
Deneyler, bu yöntemin performansının Adam'ın küçük veri kümeleri ve CIFAR-10 veri kümeleri üzerindeki yönteminden daha iyi olduğunu göstermektedir.
Öğrenme oranını ayarlayın
Çoğu durumda, model yapısını iyileştirmemiz ve ayarlamamız gerekmez, bunun yerine hiperparametreleri ayarlamamız gerekir. Dil modellemede son zamanlarda yapılan bazı araştırmalar, daha karmaşık modellerle karşılaştırıldığında, LSTM parametrelerinin ve düzenlilik parametrelerinin ayarlanmasının en gelişmiş performansı elde edebileceğini göstermektedir.
Derin öğrenme optimizasyonunda, önemli bir hiperparametre öğrenme oranı 'dır. Aslında, SGD yönteminde, iyi bir yakınsama minimumunu elde etmek için uygun bir öğrenme hızı tavlama şeması oluşturmak gerekir. Adam gibi uyarlanabilir öğrenme oranı yöntemlerinin farklı öğrenme oranlarına karşı daha sağlam olduğu düşünülebilir çünkü bu yöntemler öğrenme oranını kendileri güncelleyebilir. Bununla birlikte, bu yöntemler için bile, iyi bir öğrenme oranı ile optimal bir öğrenme oranı arasında büyük bir fark olabilir (Andrej Karpathy Verified hesabı, optimum öğrenme oranının 3e-4 olduğunu söylüyor https://twitter.com/karpathy/status / 801621764144971776).
Zhang tarafından 2017 yılında yapılan bir araştırma, öğrenme hızı tavlama şemasını ve momentum parametrelerini ayarladıktan sonra, SGD yönteminin performansının Adam'ınkiyle karşılaştırılabilir olduğunu ve yakınsama hızının daha hızlı olduğunu gösterdi. Öte yandan, Adam'ın yöntemindeki öğrenme hızının uyarlanabilirliğinin, öğrenme hızı tavlamasını taklit edebileceğini düşünebiliriz, ancak net bir tavlama şeması hala yararlıdır. Çünkü SGD yönteminde öğrenme hızı tavlamasını Adam'a eklersek makine çevirisi görevlerinde SGD yönteminden daha iyi performans gösterebilir ve daha hızlı birleşebilir.
Aslında, öğrenme hızı tavlama şeması yeni bir özellik mühendisliği gibi görünüyor, çünkü gelişmiş öğrenme hızı tavlama şemasının modelin son yakınsama performansını iyileştirebileceğini bulduk. Vaswani ve arkadaşları 2017'de ilginç bir örnek verdi. Model ayarlamada, genellikle büyük ölçekli hiperparametre optimizasyonu gereklidir.Bu makalenin yeniliği, öğrenme hızı tavlama şemasının da optimize edilecek özel odak olarak görülmesidir. Yazar Adam yöntemini kullanır, burada Adam1 = 0.9 ve varsayılan olmayan parametreler 2 = 0.98, = 10-9, öğrenme hızı için en rafine tavlama şemalarından biri olduğu söylenebilir:
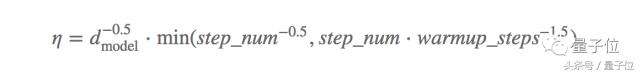
Dmodel, model parametrelerinin sayısıdır ve warmup_steps 4000'dir.
Smith ve arkadaşlarının 2017'de yaptığı bir başka makale, öğrenme oranı ve parti boyutu arasında ilginç bir ilişki olduğunu ortaya koydu. Bu iki hiperparametrenin genellikle birbirinden bağımsız olduğu düşünülür, ancak öğrenme oranının azaltılmasının parti boyutunu artırmaya eşdeğer olduğunu ve ikincisinin paralel eğitimin hızını artırabileceğini buldular. Buna karşılık olarak, öğrenme oranını artırarak ve toplu iş boyutunu ölçeklendirerek model güncellemelerinin sayısını azaltabilir ve eğitim hızını artırabiliriz. Bu keşif, büyük ölçekli derin öğrenmenin eğitim sürecini etkiler ve mevcut eğitim planı, hiperparametre ayarlamasına gerek kalmadan yeniden ayarlanabilir.
Sıcak yeniden başlatmalar
Yeniden başlatmalı SGD yöntemi
Yakın zamanda önerilen diğer bir etkili yöntem SGDR'dir Loshchilov ve Hutter, SGD yöntemini geliştirmek için öğrenme hızı tavlama sistemini değiştirmek için bir sıcak yeniden başlatma yöntemi kullanır. Her yeniden başlatmada, öğrenme hızı belirli bir değere başlatılır ve ardından kademeli olarak azaltılır. Bu yeniden başlatmanın herhangi bir zamanda gerçekleştirilebilmesi önemlidir, çünkü optimizasyon baştan başlamaz, ancak modelin önceki adımda yakınsadığı parametrelerden başlar. Anahtar, aşağıda gösterildiği gibi öğrenme oranını hızla düşürecek agresif bir kosinüs tavlama şeması yoluyla öğrenme oranını ayarlamaktır:
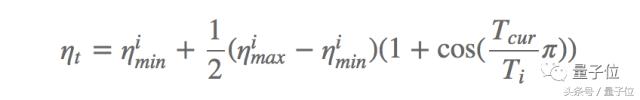
Bunlar arasında, imin ve imax, i-inci eğitim sırasında öğrenme hızının değişim aralığıdır, Tcur son yeniden başlatmadan bu yana tamamlanan yineleme sayısını temsil eder ve Ti bir sonraki yeniden başlatma için yineleme sayısını belirtir. Geleneksel öğrenme hızı tavlama şeması ile karşılaştırıldığında, sıcak yeniden başlatma yönteminin performansı (Ti = 50, Ti = 100 ve Ti = 200) Şekil 1'de gösterilmektedir.
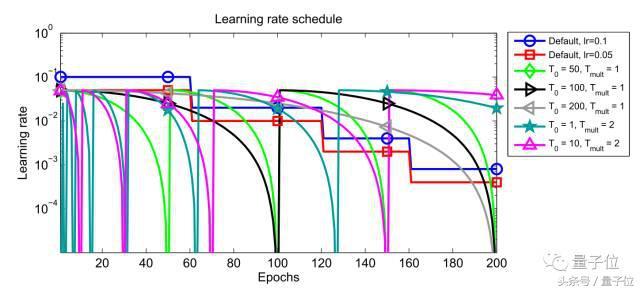
Şekil 1: Sıcak yeniden başlatma ile öğrenme hızı yönteminin performans değişimi
Yeniden başlatmanın ardından, yüksek bir başlangıç öğrenme hızı, parametreleri temelde önceden birleştirilmiş minimumdan kayıp işlevi yüzeyinin farklı alanlarına çıkarabilir. Bu aktif tavlama mekanizması, modelin yeni ve daha iyi bir çözüme hızla yakınlaşmasını sağlar. Yazar ayrıca gözlem yoluyla, sıcak yeniden başlatma kullanan stokastik gradyan iniş yönteminin, öğrenme hızı tavlama mekanizmasından 2 ila 4 kat daha az zaman gerektirdiğini ve eşdeğer veya daha iyi performans elde edebileceğini buldu.
İlk olarak Smith tarafından önerilen, sıcak yeniden başlatmayı kullanarak öğrenme hızı tavlaması, döngüsel olarak değişen öğrenme hızı olarak da adlandırılır. Fast.ai öğrencileri, sıcak yeniden başlatma ve döngüsel değişim öğrenme oranını tartışan iki başka makale daha verdiler. Adresler aşağıdaki gibidir:
https://medium.com/@bushaev/improving-the-way-we-work-with-learning-rate-5e99554f163b
Anlık görüntü entegrasyonu (Anlık görüntü toplulukları)
Anlık görüntü topluluğu, Huang tarafından yakın zamanda önerilen, tek bir modeli eğitirken bir seti birleştirmek için sıcak yeniden başlatmayı kullanan ve temelde hiçbir ek maliyeti olmayan ustaca bir yöntemdir. Bu yöntem tek bir modeli eğitebilir, daha önce görülen kosinüs tavlama sistemine göre yakınsayabilir, ardından model parametrelerini kaydedebilir ve sıcak yeniden başlatma gerçekleştirebilir ve bu adımları M kez tekrarlayabilir. Son olarak, kaydedilen tüm model anlık görüntüleri bir set oluşturur. Şekil 2'de görülebileceği gibi, hata yüzeyinde yaygın olarak kullanılan SGD optimizasyonu ile anlık görüntü entegrasyon sürecinin performansı arasındaki performans farkı.
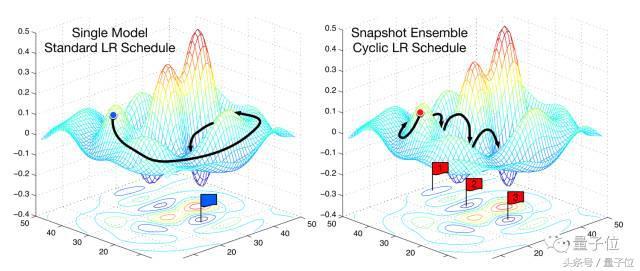
şekil 2: SGD ve anlık görüntü entegrasyonu
Genel olarak konuşursak, entegrasyonun başarısı kombinasyondaki her modelin çeşitliliğine bağlıdır. Bu nedenle, anlık görüntü entegrasyonu, kosinüs tavlama şemasının yeteneğine dayanır, böylece model, her yeniden başlatmadan sonra farklı bir yerel optimum değere yakınlaşabilir. Yazar bunun pratikte doğru olduğunu ve CIFAR-10, CIFAR-100 ve SVHN'de iyi sonuçlar elde ettiğini kanıtlıyor.
Yeniden başlatmalı Adam yöntemi
Adam'ın yönteminde başlangıçta sıcak yeniden başlatma uygulanamaz çünkü ağırlığı anormal şekilde azalır. Sabit ağırlık azalmasının ardından Loshchilov ve Hutter, 2017'de yeniden başlatmayı Adam'a kadar uzattı. Bunlar arasında, imin = 0, imax = 1, şunu elde ederiz:
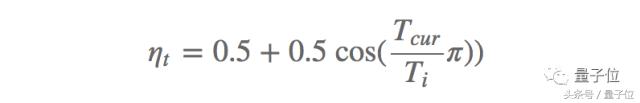
Başlangıçta daha küçük bir Ti seçmeniz (yineleme sayısı 1-10 arasındadır) ve her yeniden başlatmada 2 gibi bir Tmult faktörü ile çarpmanız önerilir.
Öğrenme optimizasyonu
Geçen yılın en ilginç makalelerinden biri Andrychowicz ve arkadaşları tarafından yazılan gradyan inişle gradyan inişle öğrenmeyi öğrenmek idi. Bu aynı zamanda reddit netizenleri tarafından seçilen "2016'nın en iyi makalesi" idi. Ana modeli eğitirken parametreleri güncellemek için LSTM optimize ediciyi eğittiler. Ne yazık ki, ayrı bir LSTM optimize ediciyi öğrenmek veya optimizasyon için önceden eğitilmiş bir LSTM optimize ediciyi kullanmak, model eğitiminin karmaşıklığını büyük ölçüde artıracaktır.
Ayrıca bu yıl, belirli bir alan dilinin model yapısını oluşturmak için LSTM'yi kullanan etkili bir "öğrenmeyi öğrenme" makalesi var. Arama süreci çok fazla kaynak gerektirse de, keşfedilen yapı mevcut yapının yerini almak için kullanılabilir. Bu arama sürecinin etkili olduğu kanıtlanmış ve dil modellemede en gelişmiş sonuçları elde etmiş ve CIFAR-10'da çok rekabetçi sonuçlar elde etmiştir.
Aynı arama stratejisi, temel sürecinin manuel olarak tanımlandığı başka herhangi bir alana da uygulanabilir, bunlardan biri derin öğrenmenin optimizasyon algoritmasıdır. Daha önce gördüğümüz gibi, optimizasyon algoritmaları bu kurala çok iyi uyuyor: hepsi geçmiş gradyanın üssel hareketli ortalamasının (momentum gibi) ve geçmiş kare gradyanın (Adadelta, RMSprop, Adam gibi) üstel hareketli ortalamasının bir kombinasyonunu kullanır.
Bello ve diğerleri, bu üstel hareketli ortalamalar gibi optimizasyon için yararlı olan ilkellerden oluşan alana özgü bir dil tanımladı. Ardından, tüm olası güncelleme kuralı alanlarından güncelleme kurallarını örnekler, modeli eğitmek için bu güncelleme kuralını kullanır ve test kümesindeki eğitimli modelin performansına göre RNN denetleyicisini günceller. İşlemin tamamı Şekil 3'te gösterilmektedir.
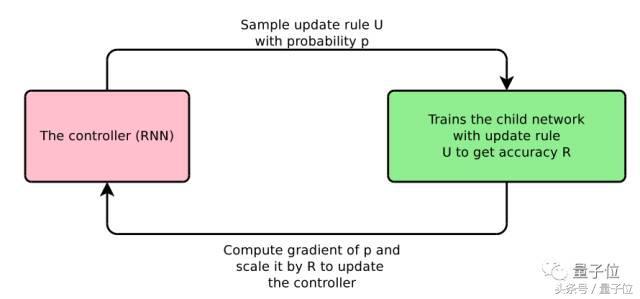
resim 3: Nöral optimize edilmiş arama
Özellikle, PowerSign ve AddSign olmak üzere iki güncelleme denklemi tanımladılar. PowerSign'ın güncelleme formülü aşağıdaki gibidir:
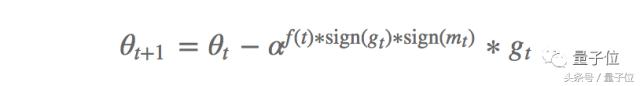
Bunlar arasında, bir hiperparametredir, genellikle e veya 2'ye ayarlanır; f (t), 1'e ayarlıdır veya bir bozunma işlevi (doğrusal, döngüsel veya azalmayı t zaman adımıyla yeniden çalıştırın) burada mt, geçmiş gradyanın hareketli ortalamasıdır değer. Genellikle, = e ayarlayın ve zayıflama yoktur. Güncellemenin, gradyan yönünün ve hareketli ortalamanın tutarlı olup olmadığına bağlı olarak gradyanı f (t) veya 1 / f (t) olarak ölçeklediğini unutmayın. Bu, momentuma benzer geçmiş gradyan ile mevcut gradyan arasındaki benzerliğin, derin öğrenme modellerini optimize etmek için anahtar bilgi olduğunu gösterir.
AddSign aşağıdaki gibi tanımlanır:
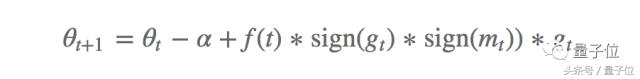
Bunlar arasında, genellikle yukarıdakine benzer şekilde 1 veya 2'ye ayarlanır, bu sefer ölçek gradyan yönünün tutarlılığına bağlı olarak + f (t) veya f (t) olarak güncellenir. Yazar, PowerSign ve AddSign'ın CIFAR-10'daki Adam, RMSprop ve SGD yöntemlerinden daha iyi performans gösterdiğini ve ImageNet sınıflandırması ve makine çevirisi gibi diğer görevlere iyi bir şekilde aktarılabileceğini belirtiyor.
Genellemeyi anlamak
Optimizasyon problemi, genelleme yeteneği ile yakından ilgilidir, çünkü minimum model yakınsaması, modelin genelleme yeteneğini belirler. Bu nedenle, optimizasyon problemlerinin ilerlemesi, bu minimum değerin genelleme yeteneğinin anlaşılmasındaki teorik ilerleme ile yakından ilgilidir ve derin öğrenmedeki genelleme yeteneği daha derinlemesine anlaşılabilir.
Bununla birlikte, derin sinir ağlarının genelleme yetenekleri hakkındaki anlayışımız hala çok basit. Son çalışmalar, yerel minimumların sayısının, parametrelerin sayısı ile üssel olarak artabileceğini göstermiştir. Mevcut derin öğrenme yapısındaki çok sayıda parametre göz önüne alındığında, bu tür modeller, özellikle rastgele girdileri tamamen hatırlayabildiklerini düşünürsek, bu şaşırtıcı görünüyor.
Keskar ve arkadaşları, minimumun keskinliğinin zayıf genelleme kabiliyetinin nedeni olduğuna inanırken, kesikli gradyan inişinin bulduğu keskin minimumların daha yüksek bir genelleme hatasına sahip olduğuna işaret ettiler. Bu sezgiseldir, çünkü genellikle bu fonksiyonun düzgün olmasını isteriz ve keskin minimumların görünümü, karşılık gelen hata yüzeyinin yüksek düzensizliğini gösterir. Bununla birlikte, son araştırmalar netliğin iyi bir gösterge olmayabileceğini göstermiştir çünkü yerel minimumların iyi genelleşebileceğini göstermektedir ve bunlar Eric Jang'ın Quora cevabında da tartışılmıştır, bağlantı aşağıdaki gibidir:
https://www.quora.com/Why-is-the-paper-%E2%80%9CUnderstanding-Deep-Learning-Requires-Rethinking-Generalization%E2%80%9D-important/answer/Eric-Jang?srid = dWc3
Bir ICLR 2018 gönderim belgesi (https://openreview.net/forum?id=r1iuQjxCZ), bir dizi ablasyon analizi ile, bir modelin aktivasyon uzayında tek bir yöne, yani tek bir birimin veya özellik haritasının aktivasyonuna bağlı olduğu gösterilmiştir. Genelleme yeteneğinin iyi bir tahminidir. Bu modelin farklı veri kümeleri ve farklı etiket hasarı dereceleri üzerinde eğitim modelleri için uygun olduğunu kanıtladılar. Ayrıca Dropout'un eklenmesinin bu sorunu çözmeye yardımcı olmadığını ve toplu normalizasyonun tek taraflı bağımlılığı engellediğini buldular.
Yukarıdaki çalışmalar hala bilmediğimiz çok fazla derin öğrenme optimizasyon bilgisi olduğunu gösterse de, yakınsama garantilerinin ve konveks optimizasyondaki birçok mevcut çalışmanın ve fikrin belirli bir dereceye kadar konveks olmayan optimizasyon problemlerine de uygulanabileceğini hatırlamak önemlidir. içinde. NIPS 2016'daki çok sayıda optimizasyon öğreticisi, bu alandaki birçok teorik çalışmaya iyi bir genel bakış sağlar.
sonuç olarak
Umarım yukarıdaki içerik, geçen yılki derin optimizasyon problemlerinde bazı ikna edici gelişmelerin iyi bir özetini sağlar. Makalede başka eksik yönler veya hatalar varsa, lütfen benimle iletişime geçin.
Makalede bahsedilen 25 belge orijinal makalenin sonundan alınabilir:
Samimi işe alım
Qubit, editörleri / muhabirleri işe alıyor ve merkezi Pekin, Zhongguancun'da bulunuyor. Yetenekli ve hevesli öğrencilerin bize katılmasını dört gözle bekliyoruz! İlgili ayrıntılar için lütfen QbitAI diyalog arayüzünde "işe alım" kelimesini yanıtlayın.
Qubit QbitAI · Toutiao İmzalama Yazarı
' ' Yapay zeka teknolojisi ve ürünlerindeki yeni eğilimleri takip edin