Açık AI küçük veri taklit öğrenme, genel AI'ya işaret eder, yumuşak dikkat, sinir ağlarının genelleme yeteneğini geliştirir

Xinzhiyuan Derlemesi

Taklit öğrenme, genellikle ayrıntılı özellik mühendisliği veya çok sayıda örnek gerektiren izole edilmiş farklı görevleri çözmek için kullanılır. Ancak bu, beklediğimizden çok uzaktır: İdeal olarak, robotlar herhangi bir görevin az sayıdaki örneğinden öğrenebilmeli ve göreve özel çalışma gerektirmeden aynı görev için hemen yeni durumlara genelleştirebilmelidir. Bu makale, araştırmacıların tek seferlik taklit öğrenme adını verdiği, bu yeteneği elde etmek için bir meta-öğrenme çerçevesi önermektedir.
Özellikle, görev kümesi büyüktür (muhtemelen sınırsızdır) ve her görevin birçok örneği vardır. Örneğin, bir görev, masadaki tüm blokları bir kuleye istiflemek olabilir, başka bir görev ise masadaki tüm blokları iki kuleye istiflemek vb. Olabilir. Bu durumda, farklı görev örnekleri, farklı başlangıç durumlarına sahip farklı blok grupları içerir. Eğitim sırasında araştırmacı, algoritmaya tüm görevlerin bir alt kümesinin bir dizi örneğini sağladı. Bir sinir ağını eğitirken, bir örneği ve mevcut durumunu girdi ve çıktı eylemleri olarak alın, böylece elde edilen durum ve eylem sırası mümkün olduğunca ikinci gösteriyle eşleşir. Test sırasında, araştırmacılar sinir ağına yeni görevin tek bir örneğinin gösterimini sağladılar ve sinir ağının yeni görevin yeni örneğinde iyi performans göstereceğini umdular. Deneyler, yumuşak dikkat kullanımının, modelin eğitim verilerinde bulunmayan koşullara ve görevlere genellemesine izin verdiğini göstermektedir. Araştırmacılar, bu modeli çok çeşitli görevler ve ortamlarda eğiterek, herhangi bir paradigmayı birden çok görevi gerçekleştirebilen sağlam bir stratejiye dönüştürebilen evrensel bir sistemin elde edilebileceğini tahmin ediyorlar.
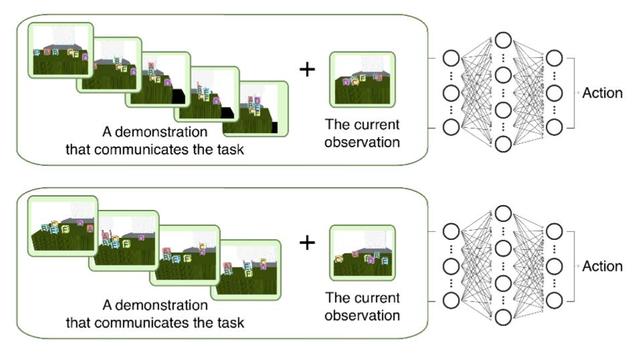
Küçük veri öğrenme stratejisi. Birden çok görevi çözmek için eğitilebilen tek bir strateji.
Sol: Özel görev stratejisi. Strateji, blokları her biri 3 yüksekliğe sahip iki kuleye istiflemek üzere eğitilmiştir; sağ taraf: ayrı özel görev stratejisi. Strateji, blokları her biri 2 yüksekliğe sahip üç kuleye istiflemek için eğitilmiştir.
Şekil 1. Geleneksel olarak, stratejiler göreve özgüdür. Örneğin, taklit veya pekiştirmeli öğrenme yoluyla, blokları 3 yüksekliğindeki bir kuleye istiflemek için bir strateji eğitilir ve ardından blokları 2 yüksekliğindeki bir kuleye istiflemek için başka bir strateji eğitilir ve bu böyle devam eder. Ve bu makale belirli bir görevi hedeflemeyen stratejilerle ilgilenmektedir Bu makale için ideal strateji, mevcut yeni görevin ne olduğunu bir örnekle anlamak ve bu yeni görevde başarıya ulaşmaktır. Açıklayıcı bir örnek olarak, her görev için tek bir örnek vermeyi umuyoruz ve bundan türetilen küçük veri stratejisi, görevin yeni durumuyla nasıl başa çıkılacağını bilebilir (örneğin, bloklar rastgele yeniden düzenlenir).
Araştırma Giriş
Araştırmacılar, bir evi temizlemek veya yemek hazırlamak gibi çeşitli karmaşık ve faydalı görevleri yerine getirebilen robotik sistemlerle ilgileniyorlar. Robotlar, uzun sistem etkileşimleri gerektirmeden yeni görevleri hızlı bir şekilde öğrenebilmelidir. Bunu başarmak için iki sorunun çözülmesi gerekir:
İlk sorun esnekliktir: robot, karmaşık aktif olmayan nesnelere nasıl yaklaşılacağını, kavrayacağını ve kaldıracağını ve bunları gerektiği gibi nasıl yerleştireceğini veya düzenleyeceğini öğrenmelidir;
İkinci sorun iletişim: mevcut görevin amacının nasıl iletileceği, böylece robot daha geniş bir başlangıç koşulları yelpazesi altında onu tekrarlayabilir.

Gösteri çok uygun bir bilgi biçimidir, bunu robotlara bu iki zorluğun üstesinden gelmeyi öğretmek için kullanabiliriz. Gösterimleri kullanarak, herhangi bir operasyonel görevi, görevi gerçekleştirmek için gerekli olan spesifik motor becerilere ipuçları sağlarken açık bir şekilde aktarabiliriz. Bunu iletişim yolu, yani doğal dil ile karşılaştırabiliriz. Dil son derece çok yönlü, etkili ve verimli olmasına rağmen, doğal dil işleme sistemleri henüz robotlardaki karmaşık görevleri doğru bir şekilde tanımlamak için dili kolayca kullanabileceğimiz seviyeye ulaşmış değil. Dil ile karşılaştırıldığında gösterimin iki temel avantajı vardır: Birincisi, dil bilgisi gerektirmez, çünkü karmaşık görevleri belirli bir dili öğrenmeyen insanlara aktarmak mümkündür; ikincisi, sistem mükemmel dil becerilerine sahip olsa bile Nasıl yüzüleceğini anlatmak gibi kelimelerle anlatılması çok zor olan birçok görev var, gösteri ve deneyim yoksa çok zor görünüyor.
Ancak şimdiye kadar taklit öğrenme, insanların büyük umutları olan yeni bir teknoloji haline gelmedi. Taklit öğrenmenin pratik uygulaması, titiz özellik mühendisliği veya çok fazla sistem etkileşim süresi gerektirir. Bu, istediğimizden çok uzaktır: İdeal olarak, belirli bir görevi robota yalnızca bir veya birkaç kez göstermek istiyoruz ve uzun sistem etkileşimi veya belirli görevlere gerek kalmadan aynı görevin yeni durumlarına hemen genelleştirilebilir. Arkaplan bilgisi.
Bu makale, küçük veri taklidi öğrenmenin ayarını tartışmaktadır. Amacı, yeni, görünmeyen bir görevle karşılaşıldığında ve görev için yalnızca bir örnek girdi alınması koşuluyla stratejinin performansını en üst düzeye çıkarmaktır. Görev paradigması alındıktan sonra strateji, iyi performans elde etmek için herhangi bir ek sistem etkileşimi gerektirmez.
Araştırmacılar, stratejileri geniş çapta dağıtılmış bir dizi görev üzerine eğitir ve potansiyel görev sayısı sınırsızdır. Her eğitim görevi için bir dizi başarılı örnek olduğu varsayılır. Eğitim stratejisinin girdisi şu şekildedir: (i) mevcut gözlemler; (ii) aynı görevin farklı örneklerini başarılı bir şekilde çözme örnekleri. Bu stratejinin çıktısı mevcut kontroldür. Aynı görev için herhangi bir çift örneğin, bir örneğin girdi, diğerinin çıktı olarak kabul edildiği sinir ağı stratejisi için denetimli bir eğitim örneği sağladığını belirtmek gerekir.
Bu modelin düzgün çalışmasını sağlamak için araştırmacılar, paradigmanın karşılık gelen durumunu ve eylem sırasını işlemek ve ayrıca ortamdaki çeşitli blok konumlarının vektör bileşenlerini işlemek için yumuşak dikkat kullandılar. Her iki girdi türü için de yumuşak dikkatin kullanılması genellemeyi mümkün kılar. Özellikle, Şekil 1'de gösterilen blok istifleme görev serisinde. Makalede önerilen sinir ağı stratejisi, herhangi bir eğitim verisinde bulunmayan yenilikçi blok istifleme görevlerinde iyi performans gösteriyor.
Çeşitli görevler ve gösteriler için eğitilebiliyorsa ve uygun şekilde genişletilebiliyorsa, bu yöntemin robota karmaşık görevleri aktarabilen ve birçok gerçek ortamda iyi performans göstermesini sağlayan bir modeli başarılı bir şekilde öğrenmesi muhtemeldir.
İki görev: hedef noktaya varma ve blok istifleme
Örnek ayar problemini göstermek için, iki özel durumu açıklayacağız: biri hedef nokta varış görevi ve diğeri blok istifleme görevidir.
-
Hedef noktaya ulaşma görevi
Hedef noktaya ulaşmak çok basit bir iştir. Her görevde, belirli bir dönüm noktasına ulaşmak için bir robotu kontrol ediyoruz ve Şekil 2'de gösterildiği gibi farklı görevler farklı tanımlayıcılarla tanımlanıyor. Bir görev turuncu alana ulaşmak, diğer görev ise yeşil üçgen alanına ulaşmaktır. Temsilci kendi iki boyutlu konumunu ve her logonun iki boyutlu konumunu alabilir. Her görevde, temsilcinin başlangıç konumu ve tüm işaretlerin konumları farklı görevlerde değiştirilebilir.
Gösteri yoksa robot hangi dönüm noktasına ulaşacağını bilemez ve görevi tamamlayamaz. Bu nedenle, bu ayar küçük veri taklidinin, yani görevleri gösteri yoluyla iletmenin özüdür. Öğrendikten sonra, temsilci gösteriden varış noktası tanımlayıcısını tanıyabilmeli ve yeni görevde aynı dönüm noktasına ulaşabilmelidir.
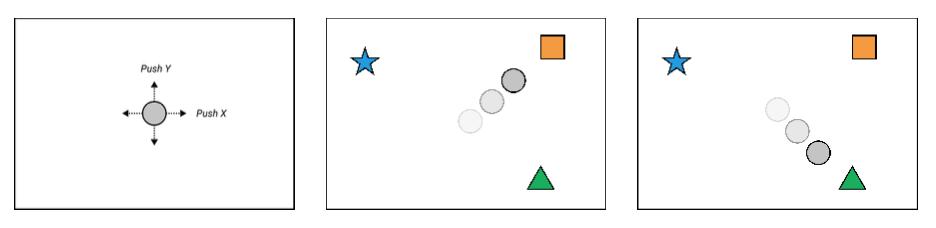
Şekil 2. Robot, iki boyutlu bir kuvvet tarafından kontrol edilen bir noktadır. Bu görev dizisi, hedef noktaya ulaşmaktır. Her görevin dönüm noktası özellikleri farklıdır ve model, gösteriye dayalı olarak takip edilecek hedefi bulmalıdır. (Solda) robotu gösterir; (ortada) görev turuncu kutuya ulaşmaktır; (sağda) görev yeşil üçgene ulaşmaktır.
-
İstifleme görevini engelle
Şimdi, farklı görevlerin birleşik bir yapıyı paylaşabilmesi için daha gelişmiş operasyonel beceriler gerektiren bir dizi daha zorlu görevi ele alıyoruz, bu da önemli görünmeyen görevlerin genellemesini incelememize olanak tanıyor. Blok istifleme görevleri serisinde amaç, çeşitli sayıda küp bloğunu kullanıcı tanımlı bir yapıya istiflemek için bir 7-DOF Getirme robot kolunu kontrol etmektir. Her yapı, farklı yükseklikteki kulelerde düzenlenmiş bloklardan oluşur ve Şekil 3'te gösterildiği gibi ghij veya ab cd ef gh gibi bir karakter dizisi ile tanımlanabilir. Her yapı farklı bir göreve karşılık gelir. Tipik bir görevde, armatüre göre bir dizi obje pozisyonunu (x, y, z) ve ayrıca armatürün açılması veya kapanması hakkındaki bilgileri gözlemleyin. Nesnelerin sayısı farklı görevlerde sürekli değişebilir.

Başlangıç durumu. Bloklar rastgele masaya yerleştirildi.

Her biri 2 yüksekliğe sahip 4 kuleye istifleme işlemi. Bunlar arasında A bloğu B bloğuna, C bloğu D bloğuna, E bloğu F bloğuna ve G bloğu H bloğuna yerleştirilmiştir. Görev, ab cd ef gh olarak tanımlanır.

Yüksekliği 4 olan bir kuleye istifleme işlemi. G bloğu H bloğuna, H bloğu I bloğuna ve I bloğu J bloğuna yerleştirilir. Görev, ghij olarak tanımlanır.
Şekil 3. Görev, blokları farklı düzenlere istiflemek için bir Getirme robot kolunu kontrol etmektir. Tüm süreç binlerce zaman adımı gerektirir. Bir aşamayı, bir bloğu diğerinin üzerine yığmanın tek bir işlemi olarak tanımlıyoruz. Yukarıda gösterilen ilk görev 4 aşamalı iken ikinci görev 3 aşamalıdır.
algoritma
Sinir ağı stratejilerini eğitmek için, sıralı karar problemlerinde strateji öğrenmek için herhangi bir algoritmayı kullanabiliriz. Örneğin, eğitim görevleri sırasında ödüller elde edilebilirse, stratejileri optimize etmek için pekiştirmeli öğrenmeyi kullanabiliriz. Değiştirilmesi gereken tek şey, her aşamanın başlangıcından önce rastgele seçilen gösterici kısıtlama stratejisidir. Bu makalede, davranışsal klonlama ve DAGGER gibi taklit öğrenme algoritmalarına odaklanacağız (Ross vd., 2011) Bu algoritmaların ödül işlevini belirtmek yerine sadece gösterilmesi gerekir. Bu daha büyük ölçeklenebilirlik potansiyeline sahiptir çünkü bir görevi göstermek, iyi tasarlanmış bir ödül işlevini belirlemekten daha kolaydır (Ng ve diğerleri, 1999).
İlk önce her görev için bir dizi gösteri topluyoruz ve yörünge alanında daha geniş bir kapsama sahip olmak için eyleme gürültü ekliyoruz. Her eğitim yinelemesinde, görev listesini (değiştirilerek) örnekleriz. Her örnekleme görevi için, gösterimi ve küçük bir gözlem davranışları grubunu örnekleriz. Mevcut gözlemlere ve gösterilere göre, strateji, davranışın sürekli veya kesikli olmasına göre istenen davranışı geri yüklemek için l2 veya çapraz entropi kaybını en aza indirerek eğitilir. Tüm deneylerde, 0,001 öğrenme oranıyla optimizasyon için Adamax (KingmaBa, 2014) kullanıyoruz.
Mimari
Prensipte sinir ağları davranışı ayarlamak ve gösterilerden ve saha gözlemlerinden haritalamayı öğrenmek için kullanılabilir, ancak uygun bir mimari kullanmanın önemli olduğunu gördük. Blok nesnelerin istifleme mimarisi ile ilgili çalışmamız, bu makalenin ana katkılarından biridir ve gelecekte daha karmaşık küçük veri simülasyon öğrenimini temsil ettiğine inanıyoruz. Hedef noktaya ulaşma işi daha basit olsa da yapı seçiminin de çok önemli olduğunu gördük, aşağıdaki seçenekleri değerlendiriyoruz.
-
Hedef noktasına ulaşma görev yapısı
Bu soru için üç mimariyi ele alıyoruz
a) Sıradan LSTM: İlk mimari 512 gizli birim içeren basit bir LSTM'dir (Hochreiter ve Schmidhuber, 1997). Gösteri yörüngesini okur, ardından çıkışı mevcut duruma bağlanır ve eylemler oluşturmak için çok katmanlı algılayıcıya (MLP) beslenir.
b. Dikkatli LSTM: Bu yapıda, LSTM gösterim dizisinden farklı yer işaretlerinin ağırlıklarını çıkarır. Ardından, test senaryosundaki ağırlığı uygular ve mevcut durumdaki dönüm noktası konumu için ağırlıklı bir kombinasyon oluşturur. Ardından, bu iki boyutlu çıktıyı yapın ve eylemi oluşturmak için MLP'ye beslemek için aracının mevcut konumuna bağlayın.
c. Özenli son durum: Bu mimari, tüm gösteri yörüngesine bakmaz, sadece gösterinin son durumuna bakar (görevi iletmek için yeterlidir) ve işaretler için ağırlık oluşturur. Sonra tıpkı önceki mimari gibi çalışır.
Lütfen bu üç mimarinin belirli hedef noktalara ulaşmada giderek daha fazla uzmanlaştığını ve bu da ifade etme ve genelleme arasında potansiyel bir değiş tokuşa işaret ettiğini unutmayın. Bunu doğru tartmaya çalışacağız.
-
İstifleme görev mimarisini engelle
Blok istifleme görevleri için, strateji yapısı aşağıdaki özelliklere sahip olmalıdır:
Farklı blok sayılarına sahip görev örneklerine uygulanması kolay olmalıdır.
Aynı görevin farklı permütasyonlarına doğal olarak genelleme yapmak mümkün olmalıdır. Örneğin, strateji yalnızca abcd görevi hakkında eğitim alsa bile, görev dcba üzerinde iyi çalışmalıdır.
Farklı uzunluklardaki gösterileri barındırabilmelidir.
Önerilen mimarimiz üç modül içerir: gösteri ağı, içerik ağı ve manipülasyon ağı.
a. Gösteri ağı
Şekil 4'te gösterildiği gibi, gösteri ağı, tanıtım yörüngesini girdi olarak alır ve stratejide kullanılmak üzere gösteri yerleştirmeleri oluşturur. Gömme boyutu, gösterinin uzunluğu ve ortamdaki blok sayısı ile doğrusal olarak artar.
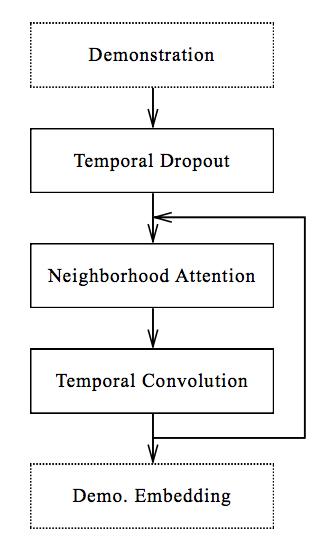
Şekil 4 Gösteri ağı
b. Bağlam ağı
Bağlamsal ağ, modelimizin özüdür. Şekil 5'te gösterildiği gibi, gösteri ağı tarafından oluşturulan mevcut durumu ve yerleştirmeyi işler ve boyutu gösterinin uzunluğuna veya ortamdaki blok sayısına bağlı olmayan bağlamsal gömme çıktılarını verir. Bu nedenle, yalnızca manipülasyon ağı tarafından kullanılacak ilgili bilgilerin toplanması zorunludur.
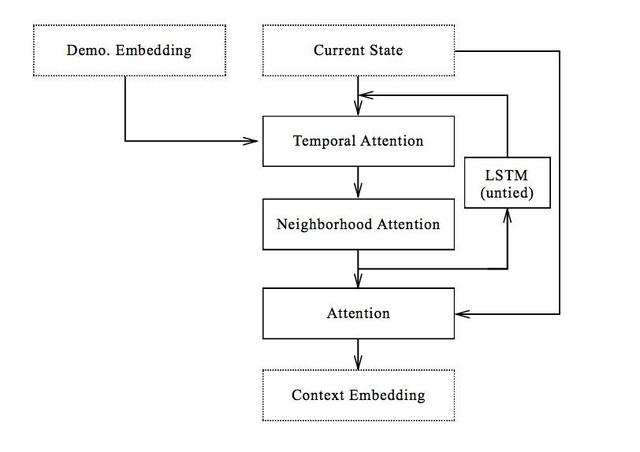
Şekil 5 Bağlam ağı
c. Ağı yönetin
Ağı manipüle etmek en basit bileşendir. Şekil 6'da gösterildiği gibi, kaynak bilgisini ve hedef blok bilgisini çıkardıktan sonra, mevcut aşamadaki blokları istiflemek için gereken eylemleri hesaplamak için basit bir MLP ağı kullanılır. Bu iş bölümü, modüler eğitim olasılığını ortaya çıkarır: manipülasyon ağı, gösteri hakkında veya ikiden fazla blok hakkında bilgi edinmeye gerek kalmadan bu basit süreci tamamlamak için eğitilebilir. Bu olasılığı gelecekteki çalışmalarda keşfedeceğiz.
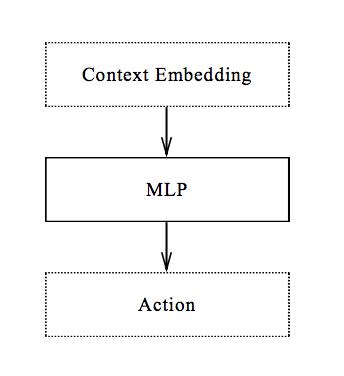
Şekil 6 Ağı yönetin
Deney
-
Hedef noktaya ulaşma görevi
Küçük veri taklidi öğrenme çerçevesinin altında yatan temel kavramları göstermek için, deneyler için daha önce açıklanan basit 2D hedef nokta varış görevini kullandık. Hedef sayısının 2 ile 10 arasında değiştiği, artan zorluk derecesine sahip birden fazla görev setini dikkate alıyoruz. Hedefin konumu ve nokta robotun başlangıç konumunun rastgele olduğu eğitim için her görev grubundan 10.000 yörünge topluyoruz. Gösterileri verimli bir şekilde oluşturmak için sabit kodlanmış uzman stratejileri kullanıyoruz. Hesaplanan eylemleri çevreye uygulamadan önce rahatsız ederek yörüngenin gürültüsünü artırıyoruz ve sinir ağı stratejilerini eğitmek için basit davranış klonları kullanıyoruz. Eğitim stratejisi yeni bir senaryoda değerlendirilir ve eğitimde hiç görünmeyen yeni bir gösteri izine göre ayarlanır.
Daha önce açıklanan üç mimarinin performansını değerlendiriyoruz. LSTM tabanlı mimari için, eğitim sırasında 0.1 olasılıkla aktivasyonu temizleyerek tamamen bağlı katmana deaktivasyon (Srivastava ve diğerleri, 2014) uyguluyoruz.
Sonuç, Şekil 7'de gösterilmektedir. Mimari daha özel hale geldikçe daha iyi genelleme performansı elde ettiğimizi gözlemledik. Bu basit görev için, tüm gösterimin ayarlanması genelleme performansına zarar verecek gibi görünmektedir, net bir şartname olmasa bile, son durumdaki ayarlama en iyi sonucu verir. Bu mantıksız değildir, çünkü nihai durum tüm görevi yansıtmak için yeterlidir.
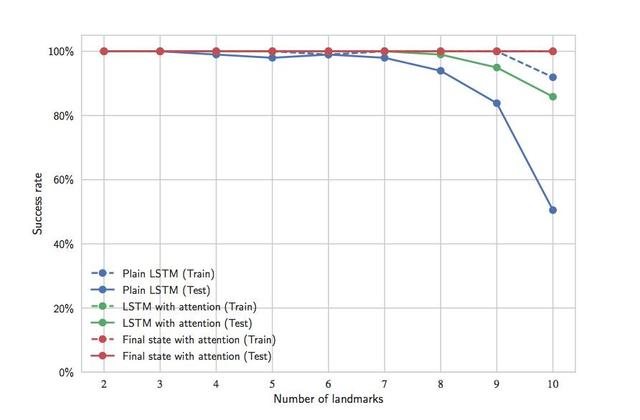
Şekil 7 Hedef noktanın göreve ulaşması için farklı mimarilerin başarı oranı. "Eğitim" eğrisi, ağ gösteriyi "izledikten" sonraki başarı oranını gösterir Eğitim süreci sırasında, strateji başlangıç durumunda çalışır, "test" eğrisi yeni durumdaki başarı oranını gösterir. Tüm dikkat temelli mimariler mükemmel eğitim başarı oranlarına ulaşmıştır ve eğriler kısmen örtüşmektedir.
-
İstifleme görevini engelle
Blok istifleme görevinde, aşağıdaki mimarilerin performansını karşılaştırdık:
DAGGER: Daha önce açıklanan mimariyi kullandık ve stratejiyi eğitmek için DAGGER'ı kullandık.
BC: Daha önce açıklanan mimariyi kullanıyoruz, ancak stratejiyi eğitmek için davranışsal klonlamayı kullanıyoruz.
Son durum: Bu mimari, tüm gösteri yörüngesi yerine son durumda kendi kendini düzenler. Blok yığınlama görev sınıfındaki son durum, bu görevin doğasını tam olarak yansıtır, bu nedenle ek bilgi gerekmez. Bununla birlikte, görev çözümünün ara aşamalarının bilgilerini içeren eksiksiz yörünge, en iyi stratejiyi eğitmeyi kolaylaştırabilir, çünkü ara adımları parametrelerine kaydetmeye gerek kalmadan doğrudan gösteri öğrenmeye dayalı olabilir. Bu, ödül tasarımının gelişmiş öğrenmede öğrenme etkisini önemli ölçüde etkileme şekli ile ilgilidir. İki strateji arasındaki karşılaştırma bize bu varsayımın makul olup olmadığını söyleyecektir. Bu stratejiyi eğitmek için DAGGER kullanıyoruz.
Anlık Görüntü: Bu mimari, gösteri yörüngesindeki her aşamanın son karesi dahil olmak üzere yörüngenin "anlık görüntüsüne" dayanır. Bu, test sırasında gösterilen bir bileşenin farklı aşamalarının elde edilebileceğini varsayar, bu diğer ayarlama stratejilerinden daha avantajlıdır ve bu nedenle tüm yörüngeye dayalı ayarlamalardan daha iyi performans göstermesi gerekir. Bu aynı zamanda, gösteri açıkça birkaç alana bölünmüşse, tüm yörünge ayarlamasına dayalı stratejinin eşit derecede iyi performans gösterip gösteremeyeceğini yargılamaya atıfta bulunabilir. Benzer şekilde, bu stratejiyi eğitmek için DAGGER kullanıyoruz.

Şekil 8, farklı mimarilerin performansını göstermektedir. Eğitim ve test görevlerinin sonuçları ayrı ayrı listelenir ve görevler, tamamlanması gereken aşama sayısına göre gruplandırılır. Bunun nedeni, tamamlanması için daha fazla aşama gerektiren görevlerin daha zor olmasıdır. Başarı oranını 100 farklı kombinasyonda hesaplamak için açgözlü bir strateji kullanıyoruz ve bunların her biri eğitimde görülmemiş farklı bir gösterime dayanıyor. Aynı gruptaki başarı oranlarının ortalamasını kaydediyoruz. Eğitim görevinde 8 aşamalı bir görev olmadığını ve test görevinde sadece 1 veya 3 basamaklı bir görev olmadığını, bu nedenle bu görevlere karşılık gelen öğeler göz ardı edildiğini unutmayın.
özet
Bu makalede, tek bir başarıyla tamamlanmış görev gösterimini yeni bir senaryoda aynı görevi tamamlamak için etkili bir strateji olarak yorumlayan basit bir model gösteriyoruz. Bu yaklaşımın etkinliğini iki tür görev aracılığıyla gösteriyoruz: hedef noktaya varma ve blok istifleme. Bu çerçeveyi, ayrı bir bilişsel modüle ihtiyaç duymadan daha fazla uçtan-uca öğrenmeyi mümkün kılacak olan grafiksel verilerin sunumuna genişletmeyi planlıyoruz. Ayrıca, tek bir sunumun görev hedefindeki belirsizliği ortadan kaldıramaması sorunundan kaçınmak için bu stratejiyi çoklu sunumlarda kendi kendini düzenlemeye yönelik olarak uygulamayı umuyoruz. Ek olarak, en önemlisi, çok sayıda ve çok sayıda görevi tamamlayabilen bir robot simülasyonu öğrenme sistemini gerçekleştirmede bu yöntemin potansiyelini keşfetmek için yöntemimizi genişletilmiş ve daha geniş bir görev yelpazesine uygulamayı umuyoruz.
Kağıt indirme: https://arxiv.org/pdf/1703.07326.pdf

27 Mart'ta Xinzhiyuan Açık Kaynak Ekolojik Yapay Zeka Teknolojisi Zirvesi ve Xinzhiyuan 2017 Girişimcilik Yarışması Ödül Töreni görkemli bir şekilde düzenlendi. "BAT" dahil olmak üzere Çin'in ana akım AI şirketleri ve 600'den fazla sektör eliti 2017 Çin'e ortak katkıda bulunmak için bir araya geldi Yapay zekanın gelişimi güçlü bir darbe aldı.