Özel Derin öğrenmeyi anlamak için bir makale (öğrenme kaynakları ile)


Şekil 1. Derin öğrenme haritası
Önsöz
Derin öğrenme kavramı 1940-1960 yıllarında sibernetiğe kadar izlenebilir ve daha sonra 1980-1990'da bağlantısallığa dönüşebilir. Üçüncü gelişme dalgası 2006'daki yapay sinir ağıydı. (Yapay sinir ağı) genişledi ve günümüzde çok popüler olan derin öğrenmeye dönüştü (Şekil 2). Aslında, derin öğrenmenin yükselişi ve gelişimi çok doğaldır.İnsanlar klasik makine öğrenimi yöntemlerini uyguladıklarında, belirli problemler veya veriler hakkında hatırı sayılır bir anlayışa sahip olmaları ve problemleri iyi bir şekilde çözmek için bunlardan özellikleri manuel olarak çıkarmaları gerekir. Özellikler çok karmaşık ve zaman alıcıdır. Bu nedenle, verilerden özellikleri otomatik olarak öğrenebilen yöntemler, büyük bir geliştirme potansiyeline sahiptir.Bu yöntem türü aynı zamanda Temsil öğrenme olarak adlandırılan bir yöntem türüdür.
Daha sonra araştırmacılar, derin düzey temsil öğrenme modelinin basit özelliklerden daha karmaşık özellikleri çıkarabildiğini ve son sınıflandırma ve ayrımcılığa daha elverişli olduğunu ve böylece bir derin öğrenme çerçevesi geliştirdiğini buldular. Tabii ki, derin öğrenmenin gelişimi, BP, bilgi işlem donanımı ve veri ölçeği gibi algoritmaların geliştirilmesinden de ayrılamaz. Derin öğrenme, klasik sığ öğrenmeye (SVM, LR, vb.) Karşılık gelen bir makine öğrenimi çerçevesi olarak anlaşılabilir ve makine öğrenimi geliştirmenin ikinci ana aşaması olarak düşünülebilir. Şu anda derin öğrenme yapay zeka alanında çok önemli bir rol oynuyor.Yapay zekanın gelişiminin derin öğrenmenin gelişmesinden kaynaklandığı bile söylenebilir.Aralarındaki ayrılmaz ilişki nedeniyle profesyonel olmayanlar sıklıkla derin öğrenmeden bahsediyor. Yapay zeka, temsil öğrenimi, makine öğrenimi ve diğer kavramlar birbirine karışıyor.
Ayrıca son yıllarda yapay zeka ve internetin hızla gelişmesi nedeniyle arkasındaki teknolojiler de akademisyenler ve endüstri personeli tarafından büyük beğeni toplarken, güçlü gücü ve düşük eşiği nedeniyle derin öğrenme en çok ilgi gören alan oldu. Bu makale; modeller, teknolojiler, optimizasyon yöntemleri, yaygın olarak kullanılan çerçeve platformları, uygulamalar ve örnekler gibi çeşitli yönlerden okuyuculara derin öğrenmeyi tanıtmaya, derin öğrenmenin gücünü açıklamaya ve makalenin sonunda okuyuculara bazı derin öğrenme kaynakları önermeye adanmıştır.

Şekil 2. Sinir ağının gelişim geçmişi
Derin öğrenme nedir?
Önsözde de belirtildiği gibi, derin öğrenme, makine öğreniminin bir çerçevesi ve yapay zekanın temel teknolojilerinden biridir.Yapay zeka, temsil öğrenimi ve makine öğrenimi ile ilişkisi Şekil 3'te görülebilir. Yani makine öğrenimi, yapay zekanın gerçekleşmesinin bir parçasıdır. Bu yöntem ve temsil öğrenimi bir makine öğrenimi çerçevesidir, derin öğrenme, temsil öğrenmesine dahildir.

Şekil 3. Derin öğrenme konumlandırma (resim kaynağı: Ian Goodfellow ve diğerleri. Derin öğrenme.)
Derin öğrenme modeli, girdi verilerinden özellikleri otomatik olarak öğrenebilir ve eğitim için kullanabilir.Modelin sığ yapısı basit öznitelikleri çıkarır ve derin yapı sığ yapıdan elde edilen özelliklere göre daha soyut öznitelikler çıkarır. Derin öğrenmenin geleneksel makinelerden farkı budur. Genel temsil öğrenme modellerinin öğrenme ve öğrenme yöntemleri. Şekil 4, farklı makine öğrenimi yöntemlerinin öğrenme yöntemlerini göstermektedir.

Şekil 4. Derin öğrenme özelliği öğrenme süreci (resim kaynağı: Ian Goodfellow ve diğerleri. Derin öğrenme.)
Peki, derin öğrenmenin derinliği nedir? Bu problem için şu anda iki ana görüş bulunmaktadır: İlk görüş, derin öğrenmenin derinliğinin hesaplama grafiğinin uzunluğu, yani model girdiyi çıktıyla eşleştirdiğinde hesaplamanın yol uzunluğuyla belirlendiğidir. Bu görüş için, hesaplama biriminin nasıl tanımlanacağı çok önemlidir ve şu anda hesaplama biriminin birleşik bir tanımı yoktur; ikinci görüş, derin öğrenmenin derinliğinin girdi ve çıktı arasındaki kavramsal ilişki grafiğinin derinliği tarafından belirlendiğidir. Yani, tanımlanan modelin yapısal derinliği, ancak yapısal derinlik genellikle hesaplanan derinlikle tutarsızdır. Yukarıdaki iki bakış açısı, derin öğrenmeyi anlamak için iki perspektif sağlar.Bunları model yapısının derinliği veya hesaplama derinliği olarak anlayabiliriz.Yazar, bunun derin öğrenmenin doğasını anlamada hiçbir etkisi olmadığına inanmaktadır.
Ortak modeller
Derin öğrenmenin bir makine öğrenimi çerçevesi olduğu defalarca dile getirilmiştir, peki bu çerçevedeki belirli modeller nelerdir? İşte herkes için bazı yaygın derin öğrenme modelleri.
MLP:
MLP (Çok Katmanlı algılayıcı), giriş katmanı, orta katman ve çıktı katmanı dahil olmak üzere, temel olarak birden çok nöron katmanından oluşan bir sinir ağından oluşan, Feedforward derin ağı (Feedforward derin ağı) olarak da adlandırılan tipik bir derin öğrenme modelidir (Şekil 5). , Katmanlar tam olarak bağlıdır. Giriş katmanı dışında, diğer katmanlardaki her nöron bir aktivasyon işlevi içerir. Bu nedenle, MLP, girişi çıktıya eşleyen bir işlev olarak kabul edilebilir. Bu işlev, çok katmanlı ürün işlemlerini ve Hesaplamayı etkinleştirin. MLP, ileriye doğru yayılma yoluyla nihai kayıp işlevi değerini hesaplar ve ardından geri yayılma algoritması (BP) boyunca eğimi hesaplar ve model parametrelerini optimize etmek için degrade inişini kullanır. MLP'nin ortaya çıkışı, algılayıcının XOR işlevini öğrenememesi sorununu çözer ve insanların sinir ağlarına olan güvenini yeniden kazanmasını sağlar.

DBN ve DBM:
DBN (Derin İnanç Ağı) da daha önce önerilen klasik bir derin öğrenme modelidir. DBN, RBM (Sınırlandırılmış Boltzmann Makinesi) modeline dayanır.Daha spesifik olarak, DBN modeli birden fazla RBM yapısı ve bir BP katmanından oluşuyor olarak görülebilir.Eğitim süreci ayrıca her RBM yapısını kademeli olarak önden arkaya eğitmektir. Her bir RBM'nin gizli katmanı, genel ağı optimize etmek için optimize edilmiştir. DBN'nin yapısında sadece son iki katmanın yönsüz olduğu ve diğer katmanların yönlülüğüne sahip olması DBN'yi sonraki DBM'den ayıran önemli bir özelliktir.
DBM (Deep Boltzmann makinesi) modeli de RBM'ye dayalı derin bir modeldir.RBM'den farkı, birden çok gizli katmana sahip olmasıdır (RBM'nin yalnızca bir gizli katmanı vardır). DBM eğitim yöntemi ayrıca tüm ağ yapısını birden çok RBM olarak kabul eder ve ardından genel modeli optimize etmek için her bir RBM'yi tek tek önden arkaya eğitir. DBM modelinde, bitişik katmanlar arasındaki tüm bağlantılar yönsüzdür. DBN ve DBM modellerinde katmanlar arasında düğümler arasında bağlantı yoktur ve düğümler birbirinden bağımsızdır.

Şekil 6. DBN ve DBM modellerinin şeması (Hinton ve diğerleri 2006)
CNN:
CNN (evrişimli sinir ağı), 1998'de Yann LeCun ve diğerleri tarafından resmi olarak önerilen ileri bir yapay sinir ağı modelidir. Tipik ağ yapısı, evrişimli katman, havuzlama katmanı ve tamamen bağlı katmanı içerir. Aşağıdaki şekil (Şekil 7) tipik bir CNN yapısını (LeNet-5) göstermektedir. Giriş olarak bir resim (eğitim örneği) verildiğinde, giriş resimleri birden fazla evrişim operatörü aracılığıyla sırayla taranır ve tarama sonuçları geçer Özellik haritasını elde etmek için aktivasyon işlevi etkinleştirilir ve daha sonra havuzlama operatörü, özellik haritasını alt örneklemek için kullanılır ve çıktı sonucu, bir sonraki katmanın girişi olarak kullanılır.Tüm evrişim ve havuzlama katmanlarından sonra, tamamen bağlı sinir ağı daha fazlası için kullanılır Nihai sonuç, çıktı katmanı aracılığıyla çıktıdır.
CNN modeli, modelin gücünü kaybetmeden daha verimli bir şekilde eğitilebilmesi için ağırlık paylaşımı yoluyla model parametrelerinin sayısını büyük ölçüde azaltan ara evrişim sürecini vurgular. CNN modeli çok esnektir.Yapısı, makul koşullar altında keyfi olarak tasarlanabilir.Örneğin, çoklu evrişimli katmanlardan sonra bir havuz katmanı eklenebilir.Bu esneklik nedeniyle, CNN çeşitli görevlerde yaygın olarak kullanılmaktadır. AlexNet, GoogLeNet, VGGNet ve ResNet gibi etki, daha sonra tanıtılacak gibi çok önemlidir.
Elbette, bu esneklik CNN yapısının kendisini bir tür hiperparametre yapar, bu da belirli bir görev için kullanılan modelin optimal model olup olmadığını garanti etmeyi zorlaştırır. Gerçek uygulamalarda CNN, resimler gibi bazı grid verilerini işlemek için daha çok kullanılır ve bu tür verilerin evrişim süreci nispeten daha büyük bir rol oynayabilir. Elbette CNN, görüntü tanıma, doğal dil işleme, video analizi, ilaç madenciliği ve oyunlar dahil olmak üzere birçok türde görevi tamamlayabilir.

Şekil 7. Tipik CNN yapısı ve operasyon süreci (Yann LeCun ve diğerleri 1998)
RNN:
RNN (Tekrarlayan sinir ağı), sıra verilerini işlemek için kullanılan bir tür sinir ağı modelidir. Tipik bir RNN modeli genellikle giriş, gizli ve çıkış olmak üzere üç tip nörondan oluşur.Giriş ünitesi yalnızca gizli üniteye bağlanır ve gizli ünite çıkışa, önceki gizli üniteye ve sonraki gizli üniteye bağlanır.Çıkış ünitesi yalnızca gizli üniteye bağlanır. Gizli birimlerden gelen girdileri kabul edin. RNN eğitim sürecinde, genellikle üç tür parametrenin öğrenilmesi ve optimize edilmesi gerekir; bunlar, gizli katmana eşlenen girdinin ağırlığı, gizli katman birimleri arasındaki dönüşüm ağırlığı ve çıktıya eşlenen gizli katmanın ağırlığı.
Şekil (Şekil 8) tipik bir RNN yapısı ve hesaplama sürecidir. RNN hesaplama sürecinde sekans verisinin ön kısmındaki bilgiler gizli ünite aracılığıyla arka kısma aktarılır, bu nedenle ikinci kısımdaki hesaplama sürecinde ön kısımdaki bilgiler de dikkate alınarak sekansın farklı kısımları arasındaki bağımlılığı simüle eder. ilişki. Açıktır ki, RNN modeli sıralı veriler, özellikle içeriğe duyarlı diziler için daha uygundur, bu da RNN'yi duyarlılık analizi, görüntü açıklama ve makine çevirisinde yaygın olarak kullanılır hale getirir. Farklı görevlerde RNN'nin yapısının farklı olduğunu belirtmekte fayda var.Örneğin RNN, görüntü açıklama sahnelerinde bire çok bir yapı iken, duygu analizi sahnelerinde çoka bir yapıdır (Şekil 9) .

Şekil 8. RNN yapısı ve hesaplama süreci (Ian Goodfellow \ vurgu {ve diğerleri} \ vurgu {Derin öğrenme}.)
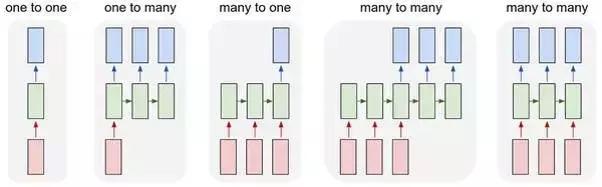
Şekil 9. Farklı uygulama senaryolarında RNN'nin yapısı. Soldan sağa, görüntü sınıflandırması, görüntü açıklama, duygu analizi, makine çevirisi ve video sınıflandırmasına karşılık gelir.
LSTM:
LSTM (Uzun kısa süreli bellek) modeli esasen bir RNN modelidir. Onunla RNN arasındaki fark, hücre durumu kavramını tanıtması ve bir geçit yoluyla hücre durumuna ekleme veya ekleme yapabilmesidir. Bilginin silinmesi Ek olarak, LSTM, LSTM'nin uzun menzilli bilgileri etkili bir şekilde ezberleyemeyen RNN'nin zayıflığının üstesinden gelmesine izin veren kapılar boyunca kapalı bir döngü oluşturabilir (Şekil 10). Şekil 10'da gösterildiği gibi, giriş, giriş geçidi, unutma geçidi, durum, çıkış geçidi, çıkış ve diğer bileşenleri içeren ortak bir LSTM birimidir.
LSTM modelindeki sözde geçit aslında bir işlev işlemidir Örneğin, tüm girdiler ağırlıklı bir ürün işlemine tabi tutulduktan sonra giriş kapısı bir sigmoid işlev işlemi olabilir. Bir dizi veri örneği için, mevcut giriş düğümü, önceki düğümün gizli katman çıktı bilgilerini sentezler ve birden çok farklı kapı işleminden sonra ve aynı zamanda önceki düğümün hücre durumu bilgisiyle birlikte geçerli düğümün gizli katman çıktı bilgisi olarak çıktı verir. Geçerli düğümün hücre durum bilgisi çıktısı olarak kapsamlı çıktı gerçekleştirin (Şekil 11). LSTM özel bir RNN modeli olduğundan, LSTM aynı zamanda duygu analizi, görüntü açıklama vb. Gibi RNN'nin uygulanabildiği birçok senaryoya da uygulanabilir. Elbette, LSTM'nin farklı görevlerde farklı performans gösteren birçok çeşidi vardır ve bu da uygulama sırasında biraz anlayış gerektirir.

Şekil 10. LSTM yapısının şematik diyagramı (Ian Goodfellow ve diğerleri. Derin öğrenme.)

Şekil 11. LSTM veri akışının şematik diyagramı (ağdan resim)
Derin otomatik kodlayıcı:
Autoencoder, giriş katmanı ve çıktı katmanı aynı anlamı temsil eden ve aynı sayıda nörona sahip bir sinir ağıdır. Otomatik kodlayıcının öğrenme süreci, girdiyi kodlama ve ardından çıktı olarak girdiyi çözme ve yeniden yapılandırma sürecidir.Giriş kodlaması tarafından oluşturulan ara gösterim, girdinin boyutsallığını azaltmaya benzer, bu nedenle otomatik kodlayıcı genellikle özellik çıkarma, gürültü azaltma vb. İçin kullanılır.
Sıradan otomatik kodlayıcı, genellikle ortada yalnızca bir gizli katman bulunan bir ağ modelini ifade ederken, derin otomatik kodlayıcı, ortada birden çok gizli katman bulunan bir ağ modelidir. Derin otomatik kodlayıcı eğitimi, DBM eğitimine benzer, her iki katman arasında ön eğitim için RBM'yi kullanır ve son olarak BP aracılığıyla parametreleri ayarlar. Benzer şekilde, derin otomatik kodlayıcının farklı görevlere karşılık gelen birçok çeşidi (seyrek otomatik kodlayıcı, denoise otomatik kodlayıcı, vb.) Vardır.

Şekil 12. Derin otomatik kodlayıcı yapı şeması
Derin ağın optimizasyon yöntemi
Önceki örnekler daha yaygın derin öğrenme modellerinden bazılarıdır, peki bu modeller nasıl optimize edilir? Bu bölüm, daha yaygın olarak kullanılan derin ağ optimizasyon yöntemlerinden bazılarını tanıtacaktır.
SGD:
SGD (Stokastik Gradyan İniş), makine öğrenmesinde en sık kullanılan optimizasyon yöntemlerinden biri olan stokastik gradyan iniş algoritmasıdır. SGD'nin çalışma prensibi gradyan inişidir, yani parametreler belirli bir adımla (öğrenme oranı) parametre gradyanının yönü boyunca ayarlanır, ancak SGD'de parametreler gradyan inişi yoluyla rastgele seçilen bir örnek için bir kez güncellenir. SGD'nin gerçek uygulamasında, öğrenme hızı, ağırlık zayıflama katsayısı, momentum ve öğrenme oranı zayıflama katsayısı dahil olmak üzere ayarlanabilen birçok parametre vardır.Bu parametreleri ayarlayarak, model daha hızlı bir oranda yakınlaşabilir. Ve fazla takmak kolay değil. SGD parametre güncelleme işlemi aşağıdaki gibidir:
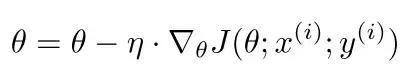
Bunlar arasında, parametreyi temsil eder, öğrenme oranını temsil eder, J (function) optimizasyon amaç fonksiyonunu temsil eder ve J () ila arasındaki gradyan rastgele seçilen bir örnektir

Yukarıda hesaplanmıştır. SGD'nin avantajı, genellikle daha iyi bir optimizasyon etkisine sahip olmasıdır, ancak SGD'nin parametrelerinin (öğrenme oranı) ayarlanması zordur, yakınsama hızı yavaştır ve yerel optimuma yakınsamanın kolaydır ve eyer noktasında sıkışmış olabilir.
Adagrad:
Adagrad'ın optimizasyon süreci de gradyanlara dayanmaktadır.Optimizasyon yöntemi her parametre için tek tek farklı öğrenme oranlarına uyum sağlayabilir. Seyrek özellikler için daha büyük bir öğrenme oranıyla güncelleme ve seyrek olmayan özellikler için daha küçük bir öğrenme oranı kullanın. Güncelleme. Bu uyarlanabilir süreç, mevcut öğrenme oranını normalleştirmek için kümülatif gradyan kullanılarak elde edilir.Parametrelerin optimize edilmesi süreci aşağıdaki gibidir:

onların arasında,

Önceki t yinelemeleri sırasında parametresinin gradyanının karelerinin toplamını temsil eder ve den, paydanın 0 olmasını önlemek için çok küçük bir değerdir. Adagrad'ın avantajı, seyrek gradyanlarla başa çıkmak için uygun olmasıdır.Dezavantajı, küresel bir öğrenme oranı ayarlamanın hala gerekli olması ve hesaplama miktarını artıran ve öğrenme hızı çok hızlı azaltan parametre gradyan dizisinin kare toplamının hesaplanması gerektiğidir.
Adadelta:
Adadelta, Adagrad yönteminin bir uzantısıdır. Daha önce belirtildiği gibi, Adagrad'da, kümülatif gradyan büyümesi, öğrenme oranının çok hızlı düşmesine neden olacaktır.Adadelta bu sorunu çözmüş göründü. Spesifik uygulama, önceki parametre dizisinde bir pencere açmak, yalnızca parametre gradyanlarını pencerede toplamak ve Adagrad'daki karelerin toplamını karelerin ortalamasıyla değiştirmektir. Parametre güncelleme işlemi aşağıdaki gibidir:

onların arasında

Penceredeki g-kare gradyanı ortalamak anlamına gelir. Adadelta, uyarlanabilir öğrenme hızının avantajlarına sahiptir ve optimizasyon hızı daha hızlıdır, ancak eğitimin sonraki aşamalarında daha belirgin bir seğirme olacaktır.
RMSprop:
RMSprop optimizasyon yöntemi, özünde özel bir Adadelta durumu olarak kabul edilebilir.

Kısmen g ile değiştirilen kök ortalama kare (RMS), RMSprop olur ve parametreler güncellenir:

onların arasında,

G'nin ortalama karesini temsil eder. RMSprop'un etkisi, sabit olmayan hedefler için daha uygun olan Adagrad ve Adadelta arasındadır, ancak RMSprop hala genel öğrenme hızı parametresine bağlıdır.
Adam:
Adam (Adaptive Moment Estimation) aynı zamanda bir parametre öğrenme hızı uyarlama yöntemidir. Esas olarak her parametrenin öğrenme oranını gradyanın birinci ve ikinci momentlerine göre ayarlar. Spesifik parametre güncelleme yöntemi aşağıdaki gibidir:

Bunlar arasında, gradyanın birinci ve ikinci momentleri sırasıyla yaklaşık olarak tahmin edilir ve toplam, sırasıyla düzeltmedir, böylece

Anın tahmini yaklaşık olarak tarafsızdır. Özünde Adam, ek momentuma sahip bir tür RMSprop'dur, bu nedenle seyrek özelliklere ve durağan olmayan hedeflere sahip verileri işlemek için uygundur.
Adamax:
Adamax, Adam'ın bir çeşididir.Öğrenme oranını normalleştirmek için kümülatif gradyanı ve önceki gradyandaki maksimum değeri kullanarak öğrenme hızı sınırında bazı değişiklikler yaptı. Bu tür kısıtlamalar hesaplamada nispeten basittir.
Nadam:
Nadam aynı zamanda Adem'in bir çeşididir ve değişimi Nesterov momentum teriminde yatmaktadır. Genel olarak konuşursak, Nadam'ın etkisi RMSprop ve Adam'dan daha iyidir, ancak hesaplamada daha karmaşıktır.
Derin ağlarda yaygın olarak kullanılan teknikler
Pratik uygulamalarda, derin öğrenme modellerinin, veri miktarı yeterince büyük olmadığında aşırı uyarlanması çok kolaydır.Bu nedenle, ciddi aşırı uyumu azaltmak ve hatta önlemek için eğitim sürecini kontrol etmek için bazı teknikler ve teknikler gereklidir. Peki, yaygın olarak kullanılan benzer teknolojiler nelerdir? Daha sonra, model eğitimini daha da optimize etmek için bazı daha yararlı teknikler tanıtacağız.
BP algoritması:
BP (Backpropagation) algoritması aslında sadece sinir ağı modellerini eğitmenin bir yöntemidir. Esas olarak, parametrelere göre amaç fonksiyonunun türevini elde etmek için zincir türetme kuralını kullanır.Türev işlemi, çıktı katmanından çıktı katmanına ters olarak geçer. Türetilmiş türev, modeli optimize etmek üzere parametreleri güncellemek için önceki bölümde tanıtılan optimizasyon algoritmasını kullanır. Modeli optimize etmek için BP algoritmasını uygulama sürecinde, genellikle gradyan kaybolması, yerel optimizasyon ve gradyan istikrarsızlığı gibi problemler vardır.Bu problemler, yavaş model yakınsamasına ve azaltılmış genelleme kabiliyetine yol açacaktır. Elbette, bu sorunların ortaya çıkması, modelde seçilen aktivasyon fonksiyonu ile de ilgilidir, bu nedenle aktivasyon fonksiyonunun makul bir şekilde seçilmesi, yukarıdaki problemleri bir dereceye kadar zayıflatacaktır. Şu anda, en yaygın olarak kullanılan aktivasyon fonksiyonları temel olarak sigmoid, tanh, ReLu, PReLu, RReLU, ELU, softmax, vb. İçerir. Aktivasyon fonksiyonunun spesifik probleme göre seçilmesi, BP algoritmasının verimli bir şekilde yürütülmesine yardımcı olur.
Bırakmak:
Daha önce de bahsedildiği gibi, derin öğrenme modelinin fazla takılması çok kolaydır.Başlıca nedeni, derin öğrenme modelinin çok karmaşık olması ve çok sayıda parametresi olmasıdır.Örneklem büyüklüğü yeterli olmadığında modelin genelleme yeteneğini sağlamak zordur. . Bu nedenle, aşırı uydurmayı önlemek için bir yöntem olan bırakma önerilmiştir.Terk etmede ana fikir, modelin karmaşıklığını azaltmak için eğitim sürecinde bazı nöronları rastgele etkisiz hale getirmektir.Tabii ki, bu süreç BP'nin yürütülmesini etkilemez. Dropout'un özel yürütme süreci şekilde gösterilmiştir (Şekil 13) Aynı ağın bırakmayı kullanmadan önce ve sonra sınıflandırma etkisini karşılaştırarak, MNIST, CIFAR-10, CIFAR-100, ImageNet, TIMIT, vb. Daha iyi sonuçlar.

Şekil 13. Bırakma sürecinin şematik diyagramı (Nitish Srivastava ve diğerleri 2014)
Toplu Normalleştirme:
Derin öğrenme ağlarının eğitim sürecindeki büyük bir problem, veriler her katmandan akarken parametreler değiştikçe veri dağılımının da değişmesidir.Bu fenomen genellikle dahili ortak değişken kayması olarak adlandırılır. Modelin çok yavaş eğitimine ve parametre başlatma için daha yüksek gereksinimlere yol açacaktır. Batch Normalization'ın ortaya çıkışı, bu sorunu büyük ölçüde çözmüştür.İşlevinin prensibi, her katmanın girişine doğrudan bir normalizasyon katmanı eklemek ve önce girişi normalize etmek ve ardından onu aktivasyon fonksiyonuna geçirmektir. Toplu Normalleştirme işleminden sonra, eğitim hızını hızlandırmak ve başlatma gereksinimlerini azaltmak için daha büyük bir öğrenme oranı kullanılabilir. Derin ağı eğitmek için Toplu Normalizasyona katılma süreci şekilde gösterilmektedir (Şekil 14). Sergey Ioffe ve diğerleri, deneyler aracılığıyla Batch Normalization'a eklenen ağın ImageNet veri kümesinde daha iyi performans gösterdiğini buldu.

Şekil 14. Batch Normalization'a katılan ağın eğitim süreci (Sergey Ioffe ve diğerleri 2015)
Erken durma:
Erken durdurma aynı zamanda derin öğrenme modellerinin gerçek uygulamasında aşırı uyumu önleyen bir teknolojidir.Bu teknoloji, temel olarak eğitim dönemlerinin sayısını kontrol ederek aşırı uyumu önler, yani doğrulama kaybı artık sürekli olarak düşmediğinde eğitimi otomatik olarak durdurur. . Aslında, erken durdurma parametrik olmayan regresyon, hızlandırma vb. Gibi birçok makine öğrenimi problemine uygulanabilir. Ek olarak, erken durdurma da bir düzenlileştirme biçimi olarak görülebilir.
Düzenlilik:
Burada bahsedilen düzenleme, yukarıda bahsedilen Bırakma ve erken durdurma hariç olmak üzere, dar anlamda L1 ve L2 gibi kontrol ağırlıklarının düzenlenmesini ifade eder. Ağın ağırlık parametrelerine L1 veya L2 düzenlileştirme terimlerinin eklenmesi de aşırı uyumu önlemek için yaygın olarak kullanılan bir yöntemdir.L1 / L2 düzenleme yöntemi makine öğreniminde yaygın olarak kullanılmaktadır ve burada tekrar etmeyeceğim.
Derin öğrenme için ortak uygulama platformları ve çerçeveleri
Derin öğrenme modelinin karmaşıklığı nedeniyle, makine donanımı ve platformunda belirli gereksinimleri vardır.İyi bir uygulama platformu, modelin eğitimini daha etkili hale getirebilir. Peki, derin öğrenme için daha popüler ve kullanışlı platformlar ve çerçeveler hangileridir? İşte daha yaygın olarak kullanılan derin öğrenme platformlarından bazıları ve bunların avantajları ve dezavantajları.
Caffe:
Caffe, Berkeley'deki California Üniversitesi Vizyon ve Öğrenme Merkezi tarafından 2013 yılında geliştirilen ve sürdürülen bir makine öğrenimi kitaplığıdır. Evrişimli sinir ağlarının çok iyi bir uygulamasına sahiptir ( Caffe C / C ++ temel alınarak geliştirilmiştir, bu nedenle model hesaplama hızı nispeten hızlıdır, ancak Caffe metin ve sıra verilerinin işlenmesi için uygun değildir, yani RNN uygulamasında büyük sınırlamalar vardır ve avantajları ve dezavantajları basit olabilir. Özet aşağıdaki gibidir:
avantaj: Görüntü işleme için uygun; kararlı sürüm ve hızlı hesaplama hızı
Dezavantajları: RNN uygulamaları için uygun değildir; ölçeklendirilemez; büyük ağlarda kullanılması uygun değildir; C / C ++ programlama zordur ve yeterince özlü değildir; neredeyse artık güncellenmemektedir
Theano / Tensorflow:
Hem Theano hem de Tensorflow, nispeten düşük seviyeli makine öğrenimi kitaplıklarıdır ve her ikisi de sembolik hesaplama çerçeveleridir. Her ikisi de evrişimli sinir ağlarına, tekrarlayan sinir ağlarına ve Bayesian ağlarına dayalı uygulamalar için uygundur. Her ikisi de Python arayüzleri sağlar. C ++ arayüzü sağlayın. Theano, Montreal Institute of Technology'nin LISA laboratuvarı tarafından 2008 yılında geliştirilmiş ve bakımı yapılmıştır ( Sayısal optimizasyon için çok uygundur ve işlev gradyanlarının otomatik hesaplanmasını destekler, ancak birden fazla GPU'yu desteklemez. Uygulamalar. Tensorflow, Google Brain ekibi tarafından geliştirilmiştir ve şu anda açık kaynaklı olup, Google Brain ekibi ve birçok kullanıcı (https://www.tensorflow.org) tarafından sürdürülmektedir.
Tensorflow, önceden tanımlanmış veri akış grafikleri aracılığıyla tensörler üzerinde sayısal hesaplamalar yaparak sinir ağı modellerinin tasarımını çok kolaylaştırır. Theano ile karşılaştırıldığında Tensorflow, dağıtılmış bilgi işlem ve çoklu GPU uygulamalarını destekler. Şimdilik, Tensorflow, derin öğrenme modellerinin uygulanmasında en yaygın kullanılan kitaplıktır.
Keras:
Keras, Theano ve Tensorflow'a (https://keras.io/) dayalı, kapsamlı bir derin öğrenme kitaplığıdır. Google'da bir yazılım mühendisi olan Francois Chollet tarafından geliştirilmiştir ve açık kaynak kodlu olarak kullanıcılar tarafından ortaklaşa sürdürülmektedir. Keras'ın çok sezgisel bir API'si vardır ve kullanımı çok özlüdür.Genel olarak, bir sinir ağı modeli yalnızca birkaç satır kodla oluşturulabilir. Şu anda Keras, kullanıcıların ağ katmanını alttan özelleştirmesini destekleyen ve önceki sürümün esneklik eksikliğini büyük ölçüde telafi eden 2.0 sürümünü yayınladı.
Meşale / PyTorch:
Torch, evrişimli sinir ağlarını çok iyi destekleyebilen Lua diline dayalı olarak geliştirilmiş bir hesaplama çerçevesidir ( Torch'daki ağın tanımı, yeni katman türlerinin genişlemesini desteklememesine neden olan katmanlar şeklinde gerçekleştirilir, ancak yeni katmanların tanımlanması nispeten kolaydır. Torch, LuaJIT üzerinde çalışır ve nispeten hızlıdır, ancak Lua şu anda ana akım bir programlama dili değildir. Ayrıca Facebook'un Ocak 2017'de PyTorch'un kaynak kodu olan Torch'un Python API'sini duyurduğunu da belirtmekte fayda var. PyTorch, kullanıcıların değişken uzunlukta girdi ve çıktıları işlemesi için uygun olan dinamik hesaplama grafiklerini destekler.Ayrıca, python tabanlı kütüphane Torch'un entegrasyon esnekliğini büyük ölçüde artıracaktır.
Lazanya:
Lasagne, Theano ( tabanlı bir hesaplama çerçevesidir. Kapsüllenmesi Keras kadar iyi değildir, ancak kodu ve temelini oluşturan Theano / Tensorflow daha özlüdür. Lazanya'nın yarı kapsüllenmiş özelliği, kullanım rahatlığını ve özelleştirme esnekliğini dengeler.
DL4J:
DL4J (Deeplearning4j), Java tabanlı bir derin öğrenme kitaplığıdır (https://deeplearning4j.org/). 2014 yılında Skymind tarafından piyasaya sürüldü ve açık kaynak sağlandı. İçerdiği derin öğrenme kütüphanesi ticari uygulamalar için açık kaynaklı bir kütüphanedir.Java tabanlı olduğu için Hadoop ve Spark gibi büyük veri işleme platformları ile entegre edilebilir. DL4J, temel doğrusal cebir hesaplamalarını gerçekleştirmek için ND4J'ye güvenir ve hesaplama hızı daha hızlıdır.Aynı zamanda, otomatik olarak paralel hale getirilebilir, bu nedenle pratik problemleri hızlı bir şekilde çözmek için çok uygundur.
MxNet:
MxNet, birden çok dilde geliştirilmiş bir derin öğrenme kitaplığıdır ( ve çoklu dil arayüzleri sağlar. MxNet tarafından desteklenen diller arasında Python, R, C ++, Julia, Matlab, vb. Bulunur ve C ++, Python, Julia, Matlab, JavaScript, R ve diğer arayüzleri sağlar. MxNet, Pedro Domingos ve Washington Üniversitesi'ndeki araştırma ekibi tarafından geliştirilen ve sürdürülen hızlı ve esnek bir öğrenme kitaplığıdır. Şu anda MxNet, Amazon Bulut Hizmetleri tarafından benimsenmiştir.
CNTK:
CNTK, Microsoft'un C ++ tabanlı geliştirilmiş açık kaynaklı derin öğrenme çerçevesidir ( ancak bir Python arayüzü sağlar. CNTK, basit dağıtım ve daha hızlı hesaplama hızı ile karakterize edilir, ancak ARM mimarisini desteklemez. CNTK'nın öğrenme kitaplığı ileri beslemeli DNN, evrişimli sinir ağı ve tekrarlayan sinir ağını içerir.
Neon:
Neon, Nervana ( tarafından geliştirilen Python tabanlı bir derin öğrenme kitaplığıdır. Öğrenme kütüphanesi, evrişimli sinir ağları, tekrarlayan sinir ağları, LSTM ve Autoencoder gibi uygulamaları destekler ve şu anda açık kaynaklıdır. Bazı testlerde Neon'un Caffe, Torch ve Tensorflow'dan daha iyi performans gösterdiğine dair raporlar var.
Derin öğrenme ağı örneği
Önceki girişle birlikte, okuyucular derin öğrenmeye dair daha ayrıntılı bir anlayışa sahipler, öyleyse derin öğrenme ağı pratik uygulamalarda nasıl tasarlanıyor? Bu bölümde, sinir ağı tasarımının bazı tekniklerini deneyimleyebileceğimiz, çok iyi uygulama efektlerine sahip birkaç derin öğrenme ağını tanıtıyoruz.
LeNet:
LeNet, ilk olarak Yann LeCun ve arkadaşları tarafından önerilen evrişimli bir sinir ağıdır.CNN'yi tanıttığımızda bu ağdan daha önce bahsetmiştik (Şekil 7). LeNet ağında C1, S2, C3, S4, C5, F6 ve OUTPUT katmanları olan toplam 7 katman vardır (giriş katmanı hariç). C1, C3 evrişimli katmanlar, S2 ve S4 aşağı örnekleme katmanlarıdır ve C5, F6 Tamamen bağlantılı bir katmandır. Ağın girişi 32 X 32'lik bir resimdir, C16 özellik haritası içerir, C316 özellik haritası içerir, tamamen bağlı iki katmandaki nöron sayısı sırasıyla 120 ve 84'tür ve son çıktı katmanı 10 içerir Bir nöron on kategoriye karşılık gelir. Bu ağın eğitim sürecinde toplam yaklaşık 12.000 parametreyi optimize etmesi gerekiyor ve el yazısı rakam tanıma (MNIST veri seti) görevinde geleneksel makine öğrenimi yöntemlerinden çok daha iyi. Bu ağın önerisi, evrişimsel katman ile örnekleme katmanını (daha sonra havuz katmanı) dönüşümlü olarak birbirine bağlamak ve son olarak bağlantıyı tamamen bağlı katmanı genişletmek olan evrişimli sinir ağlarının uygulamasına bir örnek sağlar. Uygulama, bu ağ yapısının birçok görevde iyi performansa sahip olduğunu kanıtlamıştır.
AlexNet:
AlexNet, Alex ve Hinton tarafından ILSVRC2012 yarışmasına katılmak için kullanılan evrişimli sinir ağıdır. Bu ağın, büyük veri kümeleri üzerinde daha derin bir CNN uygulamasının öncü çalışması olduğu söylenebilir. Sonraki birçok uygulama bu ağ temelinde geliştirilir. Gel. AlexNet, 5 evrişimli katmandan ve 3 tam bağlantılı katmandan oluşur. Havuzlama işlemi, birinci, ikinci ve beşinci evrişimli katmanlardan sonra eklenir (Şekil 15). Her katmandaki nöron sayısı 253440, 186624, 64896, 64896, 43264, 4096, 4096 ve 1000, dahil edilen toplam parametreler 60 milyona ulaştı. Ağın eğitim seti, ImageNet'ten 1000 kategori içeren 1.4 milyon yüksek çözünürlüklü görüntüdür; bunların 50.000'i doğrulama seti olarak ve 150.000'i test seti olarak kullanılmıştır. Ağı eğitme sürecinde aktivasyon işlevi olarak ReLu kullanıldı ve görüntü verileri yatay çevirme yöntemleriyle güçlendirildi.Aşırı uydurmayı önlemek için ağ ayrıca bırakma teknolojisini kullandı ve ağın benimsenen toplu gradyan optimizasyonu Azaltın ve ivme ve ağırlık azalması ekleyin. Tüm eğitim süreci iki GTX 580 GPU'da 5-6 gün sürdü. Nihai sonuç, ağın ILSVRC2012 rekabetinde en iyi sonuçları elde etmesidir ve diğer yöntemlerden çok uzaktır.

Şekil 15. AlexNet'in ağ yapısı (Alex Krizhevsky ve diğerleri 2012)
ZF Net:
ZF Net, Zeiler ve Fergus tarafından ILSVRC2013 yarışmasında AlexNet'e dayalı olarak önerilen bir ağdır. Aslında, ağ AlexNet'te sadece bazı değişiklikler ve ayarlamalar yaptı, bu nedenle ikisi arasındaki ağ yapısı çok farklı değil (Şekil 16). Ana değişiklik, ZF Net'teki ilk evrişim katmanının daha küçük bir evrişim çekirdeği kullanması ve evrişim adım boyutunu orijinalin yarısına düşürmesidir.Bu değişiklik, ilk iki katmanda daha fazla görüntü özelliği bilgisini tutar. ZF Net'in nihai performansı AlexNet'ten daha iyiydi ve hata oranı 1,7 puan düştü. Ek olarak, ZF Net'in yazarları, evrişimli katmanın özelliklerini görselleştirmek için bir yöntem önerdiler.

Şekil 16. ZF Net'in ağ yapısı (Matthew D. Zeiler et al. 2013)
VGG Net:
VGG Net, ILSVRC2014 yarışmasında çok iyi performans gösteren bir evrişimli sinir ağı modelidir.Karakteristik küçük bir evrişim çekirdeği ve daha derin bir evrişim seviyesidir. Ağ toplam 19 katmana, 16 evrişimli katmana ve 3 evrişimli katmana sahiptir.Tüm evrişimli çekirdeklerin boyutu 3'tür ve çoklu evrişimli katmanlar üst üste bindirilerek havuz katmanına yerleştirilir (Şekil 17; E). ZF Net ile karşılaştırıldığında, ağ sınıflandırma hata oranı% 9 düşmüş ve sınıflandırma etkisi önemli ölçüde iyileştirilmiştir. VGG Net'in ortaya çıkışı büyük önem taşımaktadır.İnsanlara etkin tasarım ve CNN kullanımı için bir yön sağlar, yani daha basit ve daha derin seviyeler, derin seviyeli özelliklerin madenciliği için daha elverişlidir.

Şekil 17. VGG Net'in ağ yapısı (Karen Simonyan ve diğerleri 2014)
GooLeNet:
GooLeNet aynı zamanda ILSVRC2014 yarışmasında ortaya çıkan ve bu yarışmada en iyi sonuçları elde eden evrişimli sinir ağı modelidir. GooLeNet, 21'i evrişimli katman ve 1 softmax çıktı katmanı olmak üzere toplam 22 katmanla VGG Net'ten daha derin bir seviyeye sahiptir (Şekil 18). Ağda birden çok (9) Başlangıç (ağdaki ağ) modülünün kullanıldığını, yani ağın katmanlar arasında sıralı olarak yığılmadığını, ancak birçok paralel bağlantıya sahip olduğunu ve Modelin sonunda tamamen bağlantılı bir katman uygulanmaz. Inception modülünün kullanımı, daha fazla özellik bilgisinin toplanmasına izin verir, tam bağlı katmanı kaldırır ve çok sayıda parametreyi azaltır, bu da belirli bir dereceye kadar fazla uydurma olasılığını azaltır. GooLeNet'in nihai sınıflandırma sonucu, VGG Net'inkinden% 0,6 daha yüksektir. GooLeNet'in önemi, gelecekte CNN ağ yapısının tasarımı için büyük bir ilham kaynağı olan katmanlar arasında yeni bir paralel bağlantı yolu sağlamasıdır.

Şekil 18. GooLeNet ağ topolojisi (Christian Szegedy ve diğerleri 2015)
ResNet:
ResNet, ILSVRC2015 yarışmasının şampiyon modelidir.Microsoft Research Asia'dan araştırmacılar tarafından önerilmiştir. Ağda 152 katman derinliği, 151 evrişimli katman ve 1 softmax çıktı katmanı vardır. Kalıntılar her iki katmanda eklenir (Şekil 19 ). Bu ağ modeli, sınıflandırma hata oranını% 3,6'ya düşürür ve önemi, artık sinir ağı olan yeni bir ağ yapısı önermektir. Artık sinir ağı önerisi, derin ağın belirli bir dereceye kadar eğitilememesi sorununu çözer ve gelecekteki uygulamalar için çok iyi bir iyileştirme yönü sağlar.

Şekil 19. ResNet ağ topolojisi (Kaiming He et al. 2015)
Derin öğrenme uygulamaları
Bilgisayar görüşü:
Bilgisayarla görme, derin öğrenme uygulamaları için en popüler alanlardan biridir.Yukarıda bahsedilen çeşitli ağ yapılarının tümü, bilgisayarla görme alanındaki görüntü sınıflandırma problemine uygulanır. CNN modeli genellikle bu tür problemleri çözmek için seçilir. Bununla birlikte, bilgisayar görüşü alanında başka birçok sorun vardır ve CNN modelini basitçe uygulamanın etkisi genellikle iyi değildir, örneğin görüntü açıklama, görüntü oluşturma ve diğer sorunlar.Özel problem türleri için daha fazla model tasarlamak gerekir.
Şu anda, bilgisayar görüşü alanındaki sınır araştırmalarındaki en popüler konular şunlardır:
ILSVRC yarışmasının görevine benzer şekilde, farklı görüntü türlerini ayıran görüntü sınıflandırması;
Görüntüdeki farklı nesneleri çerçevelemek için görüntü algılama;
Görüntüdeki farklı nesnelerin sınırlarını gösteren görüntü bölütleme;
Resim açıklama, yani resme bakıp konuşun ve metindeki karşılık gelen resmi tanımlayın;
Görüntü oluşturma, metin açıklamalarına dayalı görüntüler oluşturmaktır;
Geçici görüntüdeki nesnelerin nasıl hareket edeceğini tahmin eden video tahmini.
Konuşma tanıma:
Konuşma tanımanın amacı, ses bilgisini metne dönüştürmektir.Bu görev, insan-bilgisayar etkileşiminin temelidir. Bu görev için, geleneksel çözümler genellikle Gizli Markov Modelleri, Gauss Karışım Modelleri, vb. Gibi konuşma dizilerini modellemek için dizi modellerine dayanır. Bu geleneksel yöntemler, yüksek kelime tanıma hata oranlarına sahiptir. Konuşma tanıma süreci genellikle konuşma özelliği çıkarma ve akustik modellemeyi içerir.Araştırmacılar, konuşma özelliklerini çıkarmak için CNN kullanmanın kelime tanıma hata oranını büyük ölçüde azaltabileceğini (% 6-% 10) bulmuşlardır (Ossama Abdel-Hamid et al. 2014) , Akustik modelleme için CNN kullanımı da daha güçlü uyarlanabilirliğe sahiptir. Daha sonra araştırmacılar, daha derin evrişimli sinir ağlarının daha iyi performansa sahip olduğunu ve kod çözme arama aşamasında CNN, RNN ve LSTM'nin birlikte kullanılmasının konuşma tanımanın doğruluğunu daha da artıracağını buldular. Şu anda IBM Watson Research Center, ResNet'i birden çok LSTM ile birleştirmenin konuşma tanımanın kelime hatası oranını% 5,5'e düşüreceğini bildiriyor. Aslında Appleın Siri'si, Microsoftun Cortana ve HKUSTın konuşma tanıma teknolojisi en son teknolojiyi kullanıyor.
Doğal dil işleme:
Doğal dil işleme, aşağıdakiler dahil çeşitli özel uygulamaları kapsar:
Cümle metni verildiğinde konuşma parçası etiketleme, cümledeki her kelimenin konuşma bölümünü işaretler;
Sözdizimsel çözümleme, cümle metninin dilbilgisini çözümleme;
2014Nal KalchbrennerNal Kalchbrenner et al. 2014Baotian HuCNNChenxi ZhuLSTM2014ACLDevlin
Balazs HidasiRNN2014GoogleMLPSpotifyCNN
transfer learning
Figure 20Task A, B, C ABCDeepMindAndrei A. Rusu et al. 2016Pong, Labyrinth AtariRBMCNNPascal VOC2007Caltech101
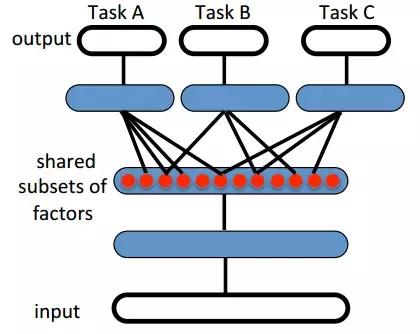
Figure 20. Yoshua Bengio et al. 2014
reinforcement learningDeepMindAlphaGoDQNDQN
generative adversarial network, GAN2014Ian GoodfellowGDGDGDDGGGANCNNDCGANLSTMGANFang Zhao et al. 2016autoencoderGANAlireza Makhzani et al. 2015RNNC-RNN-GANOlof Mogren et al. 2016GAN
github
https://github.com/endymecy/awesome-deeplearning-resources
papershttps://github.com/zhangqianhui/AdversarialNetsPapers
Ian GoodfellowDeep learninghttps://github.com/HFTrader/DeepLearningBook
LISA
https://github.com/lisa-lab/DeepLearningTutorials
Udacity
https://github.com/udacity/deep-learning
https://github.com/chasingbob/deep-learning-resources
awesomehttps://github.com/ChristosChristofidis/awesome-deep-learning
https://github.com/XuanHeIIIS/awesome-public-datasets
CS231n
Richard SocherNLPCS224d
Sergey LevineCS294
Nando de Freitas
https://www.cs.ox.ac.uk/people/nando.defreitas/machinelearning/
LeCun
Hinton
https://www.coursera.org/learn/neural-networks
https://www.youtube.com/playlistlist=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH
/
ICLR, NIPS, ICML, CVPR, ICCV, ECCV, ACL
JMLR, MLJ, Neural Computation, JAIR, Artificial Intelligence
. Ian Goodfellow et al. Deep learning. 2016
. Yoshua Bengio et al. Representation Learning: A Review and New Perspectives. 2014
. Yann LeCun et al. Gradient-based learning applied to document recognition. 1998
. Alex Krizhevsky et al. ImageNet Classification with Deep Convolutional Neural Networks. 2012
. Matthew D Zeiler et al. Visualizing and Understanding Convolutional Networks. 2013
. Nitish Srivastava et al. Dropout: A Simple Way to Prevent Neural Networks from overfitting. 2014
. Sergey Ioffe et al. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. 2015
. . 2016
. . 2015
. Understanding LSTM Networks. colah's blog
Yazar:
Daha heyecan verici kuru ürün içeriği için lütfen Tsinghua-Qingdao Veri Bilimi Enstitüsü "Datapai THU" nun resmi kamu platformunu araştırın ve takip edin