AI hakimiyeti çağı çok uzak değil! StarCraft'ın en iyi profesyonel oyuncusu 1:10 AlphaStar'ı yendi

Xin Zhiyuan Rehberi DeepMind tarafından iki yıl boyunca inşa edilen AlphaStar, dünyanın en güçlü profesyonel StarCraft oyuncularından birini 5'e 0 skorla kararlı bir şekilde mağlup etti ve insanlığın en zor oyununu, bir başka kilometre taşını kırdı!
AlphaStar çıktı!
DeepMind AlphaGo'yu piyasaya sürdükten hemen sonra, iki yaşındaki AlphaStar'ı tarih sahnesine çıkardı ve StarCraft 2'deki en iyi profesyonel oyuncuları yenmek için ilk AI'yı yarattı.
DeepMind dün gece 19 Aralık'ta yapılan bir dizi test karşılaşmasının videosunu yayınladı.Ekip arkadaşı Dario "TLO" Wunsch ile başarılı bir benchmark testinden sonra AlphaStar 5-0 puan aldı. , Dünyanın en güçlü profesyonel StarCraft oyuncularından birini kararlı bir şekilde yendi.
AI, Atari, Mario, Thor Arena ve Dota 2 gibi video oyunlarında büyük başarılar elde etmesine rağmen, şimdiye kadar AI hala StarCraft'ın karmaşıklığıyla başa çıkmak için mücadele ediyor.
"StarCraft 2", Blizzard Entertainment tarafından üretildi. Hikaye, zengin çok seviyeli oynanışa sahip kurgusal bir bilim kurgu dünyasında geçiyor ve insan zekasına meydan okumak için tasarlandı. Yüksek karmaşıklığı ve stratejisi nedeniyle bu oyun tarihin en büyük ve en başarılı oyunlarından biri haline geldi.Oyuncular 20 yılı aşkın süredir e-spor yarışmalarında yarışıyorlar.
Bu sefer AI, en iyi oyuncuları yendi ve insan zekasının son savaş alanını gerçekten kırdı!
10 video AlphaStar'ın büyük katliamına ve özel katliamına, insan oyuncuların yerinde Jedi karşı saldırısına tanık oldu
Oyundan önce, DeepMind iki insan profesyonel oyuncuyu bir araya getirdi ve her oyuncu beş tur boyunca AlphaStar'a karşı oynadı. Sonra sahnede insanlar yüzünü kurtaran yapay zeka ile final oyununu oynadı, gelin birlikte bakalım.
Bu nihai 1V1 savaşında kullanılan harita Catalyst LE'dir ve oyun sürümü 4.6.2'dir.

AlphaStar'a karşı yarışan insan oyuncular TLO ile MaNa .
TLO, Hollanda takımı "Team Liquid" e ait aktif bir Alman profesyonel oyuncu Dario Wünsch. 2018 WSC Pisti'nde 44. sırada yer aldı. TLO, tüm gücüyle Twitch'te canlı yayın yaptığı için oyuncular arasında iyi bilinir.

Bir diğer yarışmacı, Polonya kozu olarak bilinen 25 yaşındaki aktif profesyonel oyuncu "MaNa". MaNa, Protoss'a alıştı.Şimdi tamamlanan IEM Köln yarışında MaNa, grup aşamasında Koreli oyuncu Jaedong'u 2: 1 mağlup etti.
MaNa şu anda 2018 WSC Circuit'te 13. sırada , Geçen yıl WCS Austin'de ikincilik ve ayrıca WCS 2015'in üçüncü sezonunda ikinci oldu. Daha önce, MaNa Dreamhack 2012 Yaz Şampiyonasını kazandı.

Sırada 10 oyunun videosundan önemli anlar ve olay yerindeki heyecan verici dövüşler var.
1. Tur: 7 dakika, AlphaStar en iyi insan oyuncuları bitiriyor
Başlangıçta, insan oyuncu bir çiftçiyi yapay zekanın evinde ileri geri araştırmaya göndermeye yöneltti.

2 dakika 50 saniyede, insan oyuncular ilk taciz dalgasını başlatmak için 2 yüksek seviyeli kilise gönderdi ve AlphaStar keskin nişancı ve onları yok etmek için bazı güçlü adamlar gönderdi.
Daha sonra, insan oyuncular taciz etmeye devam etti ve aynı zamanda AI da karşı saldırıya başladı ve ana üsse saldırmak için bir izleyici gönderdi.
Farkında olmadan, AI zaten 6 izleyici biriktirdi ve insan oyuncu tabanına doğru adım attı.
İki taraf GANK'ın ilk dalgasını başlattı, ancak LTO aileyi saldırıya direnmeye gönderdi. Ancak, AI tedarik askerleri savaş alanına çoktan ulaştı. LTO güçsüzdür.

2. Tur: İnsan oyuncular oldukça agresif, AI adım adım, doğru hesaplama
Yine de, iki taraf erken aşamada savaşmaya devam etti.Yaklaşık 6 dakika, AlphaStar LTO'ya saldırmak için 10 izci göndermede başı çekti ve insan oyuncular başarıyla savundu.
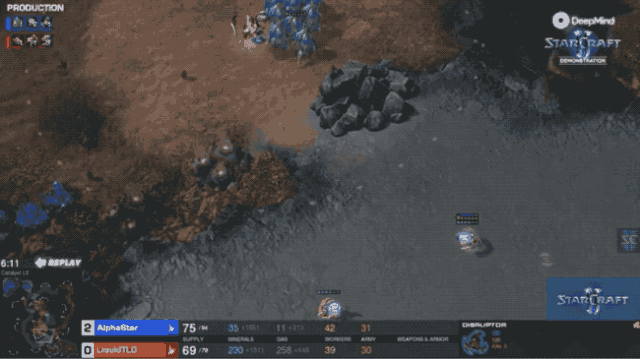
Bu dönemde AlphaStar, gaz toplamayı azaltmak için bir strateji geliştirdi.

Bundan sonra, hem insan oyuncular hem de AI'lar ekonomilerini geliştirdiler, silahlar yaptılar ve sahada dolambaçlı bir şekilde savaştılar.
Saat 14: 00'de kazanan nokta belirdi: Bir insan oyuncu yapay zekayı kovalıyor gibi görünüyordu, ancak diğer iki birlik kaynağı tarafından aniden kesildi ve vahşice öldürüldü.

İnsan oyuncular iyileşemedi ve AlphaStar tekrar kazandı.
Tur3-5: AlphaStar askerleri şehre yaklaştı, etrafı sarıldı ve hayatın her kesiminden bastırıldı, neredeyse işkence yapıyor
Sonraki video, başka bir üst düzey insan oyuncu MaNa'nın savaşı.
Kaydedilen videodaki üç istismar sahnesine bir göz atalım.

Çiftçileri boğarak yürümek.

Hızlıca bir dalgayı itin.

Üç yollu kuşatma ve bastırma, kanyonda yenilgi.
Yerinde yarışma: Jedi'da insan oyuncular karşı saldırı yapar ve tüm yapay zekayı öldürür
Yapay zeka çok güçlü olduğu için insanların gücünü kanıtlaması gerekebilir. Son olarak, profesyonel oyuncu MaNa, AlphaStar ile gerçek zamanlı olarak yarıştı.
Videoyla karşılaştırıldığında, insan oyuncular bu sefer daha muhafazakar bir strateji benimsedi, ekonomiyi geliştirmeyi ve "asker toplayıp at satın almayı" seçerken, AlphaStar kışkırtmada başı çekti.

Ayrıca, taciz dolambaçlı bir şekilde devam etti ve üssün etrafındaki ve yolu araştıran çiftçiler de vurularak öldürüldü.
Muhafazakar oyun temelinde, MaNa belirli miktarda asker biriktirdi ve AlphaStar'ın birliklerinin yuvadan çıktığını anladığında hemen bir saldırı başlattı. Aynı zamanda, çok sağlam, iki hatlı bir alt üs kurmayı da unutmadık.
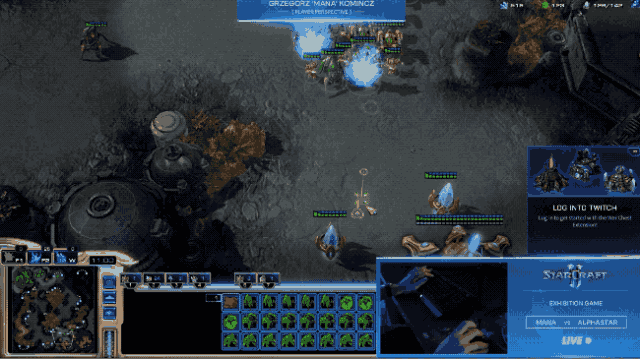
Şu anda, AlphaStar'ın birlikleri zamanında kurtarma alanına geri dönmedi ve MaNa bu fırsatı doğrudan alt üssü sökmek için kullandı.

Az önce geri dönen AlphaStar Kolordusu ile yüzleşen MaNa, şiddetle hareket etti ve kuvvetlerini doğrudan püskürttü, ancak sonuç Huanglong'a doğrudan bir saldırı oldu.
en sonunda, İnsanlar savaştı ve yapay zekayı yendi .
Dünyanın her yerinden yargıçlar bir anda sakin olmadılar ve yorum alanı çoktan patladı - insanlığın zaferi için tezahürat yaptı - bu aynı zamanda insanlığın son yüzünü yeniden canlandırmak için de olabilir.
AlphaStar İyileştirme Kaydı: Her temsilci 16 TPU kullanır
AlphaStar'ın davranışı, orijinal oyun arayüzünden girdi verilerini (birim listesi ve öznitelikleri) alan ve oyun içi işlemleri oluşturan bir dizi talimat veren derin bir sinir ağı tarafından oluşturulur. Daha spesifik olarak, sinir ağı mimarisi, bir LSTM çekirdeğini, bir otoregresif strateji başlığını bir işaretçi ağıyla ve merkezi bir değer taban çizgisini birleştirerek birime bir transformatör ana hattı uygular.
DeepMind, bu gelişmiş modelin, uzun vadeli sıra modelleme ve geniş çıktı alanları (çeviri, dil modelleme ve görsel temsil gibi) içeren makine öğrenimi araştırmalarındaki diğer birçok zorluğun çözülmesine yardımcı olacağına inanıyor.
AlphaStar ayrıca yeni bir çoklu aracı öğrenme algoritması kullanır. Sinir ağı başlangıçta Blizzard tarafından yayınlanan anonim bir insan oyununda denetimli öğrenimle eğitildi. Bu, AlphaStar'ın, oyuncular tarafından StarCraft merdiveninde kullanılan temel mikro ve makro stratejileri taklit etmesini sağlar. Bu orijinal ajan, oyunların% 95'inde yerleşik "elit" AI seviyesini yendi - insan oyuncular için altın seviye.

Daha sonra bunları çok aracılı bir pekiştirmeli öğrenme süreci oluşturmak için kullanın. Sürekli bir ittifak oluşturulur ve ittifakın temsilcileri - rakipler - tıpkı insanların StarCraft merdiveninde oyun oynaması gibi birbirleriyle oyun oynarlar.
Yeni rakipler, mevcut rakiplerden dallanarak ittifaka dinamik olarak eklenir; daha sonra her ajan, diğer rakiplerle oyundan öğrenir. Bu yeni eğitim şekli, kitleye dayalı yoğun öğrenme kavramını daha da ileriye taşıyacak ve "StarCraft" oyununun devasa stratejik alanını sürekli olarak keşfetme sürecini oluştururken, her yarışmacının en güçlü stratejinin önünde iyi performans göstermesini sağlayacaktır. Ve önceki stratejileri nasıl yeneceğinizi unutmayacaksınız.

Ligin gelişmesi ve yeni rakiplerin ortaya çıkmasıyla birlikte, önceki stratejileri yenebilecek yeni yüzleşme stratejileri ortaya çıktı. Bazı yeni rakipler, yalnızca önceki stratejinin iyileştirilmesi olan bir strateji uyguladığında, diğerleri yeni yapım siparişlerini, birim kombinasyonlarını ve mikro yönetim planlarını içeren yeni bir strateji keşfeder.
Örneğin, AlphaStar Alliance'ın ilk günlerinde, çok hızlı hızlı molalar için foton toplarının veya karanlık tapınakların kullanılması gibi bazı "neşeli" stratejiler oyuncular tarafından tercih ediliyordu. Eğitim ilerledikçe, bu maceracı stratejiler terk edildi ve başka stratejiler ortaya çıktı: örneğin, daha fazla işçi ile bir üssü aşırı genişleterek ekonomik güç kazanmak veya rakibin işçilerini ve ekonomisini yok etmek için iki kahini feda etmek. Bu süreç, oyuncuların StarCraft'ın piyasaya sürülmesinden sonraki yıllarda yeni stratejiler keşfettikleri ve daha önce tercih edilen yöntemleri yenebildikleri sürece benzer.

İttifakın çeşitliliğini teşvik etmek için, her bir temsilcinin kendi öğrenme hedefleri vardır: örneğin, temsilcinin hedefi, hangi rakiplerin yenileceği ve temsilcinin nasıl performans gösterdiğini etkileyen diğer tüm iç motivasyonlar olmalıdır. Bir temsilci belirli bir rakibi yenme amacına sahip olabilirken, başka bir temsilci tüm rakip dağıtımını yenmek zorunda kalabilir, ancak bu daha özel oyun birimleri oluşturarak başarılır. Bu öğrenme hedefleri, eğitim süreci sırasında ayarlanmıştır.

En iyi sonuç, sistemin ana unsurlarını manuel olarak oluşturmak, oyunun kurallarına önemli kısıtlamalar getirmek, sisteme insanüstü yetenekler kazandırmak veya oyunu basitleştirilmiş bir haritada oynamak olabilir. Bu iyileştirmelerle bile, hiçbir sistem profesyonel oyuncuların becerilerini karşılayamaz. Buna karşılık AlphaStar, StarCraft 2'de eksiksiz bir oyun oynadı ve kullandığı derin sinir ağı, denetimli öğrenme ve pekiştirmeli öğrenme yoluyla doğrudan orijinal oyun verilerinden eğitildi.

AlphaStar'ı eğitmek için DeepMind, StarCraft 2'nin binlerce paralel örneğinden bilgi edinmek için çok sayıda aracıyı destekleyen oldukça ölçeklenebilir dağıtılmış bir eğitim kurulumu oluşturmak için Google'ın TPU'nun v3 sürümünü kullanıyor. AlphaStar Ligi 14 gün boyunca koştu ve her ajan 16 TPU kullandı. Eğitim süresi boyunca, her temsilci 200 yıllık gerçek zamanlı StarCraft oyunu deneyimledi. Son AlphaStar ajanı, tek bir masaüstü GPU üzerinde çalışan Allianceın Nash dağıtımından - diğer bir deyişle keşfedilen en etkili strateji kombinasyonundan oluşur.
Ek olarak, bu çalışmanın makalesi yakında yayınlanacaktır.
AlphaStar gerçek savaş becerileri analizi
AlphaStar'ın eğitim sürecinden bahsettikten sonra, asıl savaş sürecini analiz edelim.
TLO ve MaNa gibi profesyonel StarCraft oyuncuları, ortalama olarak dakikada yüzlerce işlem (APM) yapabilir. Bu, her birimi bağımsız olarak kontrol eden ve her zaman binlerce, hatta on binlerce APM'yi koruyan mevcut robotların çoğundan çok daha azdır.
TLO ve MaNa ile yapılan maçlarda, AlphaStar'ın ortalama APM'si yaklaşık 280'dir ve bu, profesyonel oyunculardan çok daha düşüktür, ancak hareketleri daha hassas olabilir.
Düşük APM'nin nedenlerinden biri, AlphaStar'ın eğitime başlamak için oynatmayı kullanması ve böylece insanların oyun oynama şeklini taklit etmesidir. Ek olarak, AlphaStar'ın yanıtı, gözlem ve eylem arasında ortalama 350 ms'lik bir gecikmeye sahiptir.

TLO ve MaNa'ya karşı oynanan oyun sırasında AlphaStar, orijinal arayüz üzerinden StarCraft 2 motoruna bağlanır, bu da kamerayı hareket ettirmeden harita üzerinde kendi niteliklerini ve rakiplerinin görünür birimlerini doğrudan gözlemleyebileceği anlamına gelir.
Bunun aksine, insan oyuncular "dikkat ekonomisini" açıkça yönetmeli ve kameranın nereye odaklanacağına karar vermelidir.

Bununla birlikte, AlphaStar oyununun analizi, örtük bir dikkat odağını yönettiğini gösteriyor. Ortalama olarak aracı, MaNa veya TLO'nun çalışmasına benzer şekilde dakikada yaklaşık 30 kez "içeriği değiştirir".
Ayrıca oyundan sonra DeepMind, AlphaStar'ın ikinci versiyonunu da geliştirdi. İnsan oyuncular gibi, AlphaStar'ın bu sürümü kamerayı ne zaman ve nereye hareket ettireceğini seçecek.Algısı ekrandaki bilgilerle sınırlıdır ve eylem yeri de görünür alanıyla sınırlıdır.
DeepMind, biri ham arayüz kullanan ve diğeri AlphaStar League ile savaşmak için kamerayı kontrol etmeyi öğrenmesi gereken iki yeni ajan eğitti.
Her temsilci başlangıçta insan verilerinden denetimli öğrenimle eğitilir ve ardından pekiştirmeli öğrenme sürecine uygun olarak eğitilir. Kamera arayüzünü kullanan AlphaStar versiyonu, DeepMind dahili sıralamasında 7000 MMR'ı aşarak neredeyse ham arayüz kadar güçlüdür.
Sergi oyununda MaNa, AlphaStar'ın prototip versiyonunu yalnızca 7 gün eğitilmiş kamera arayüzü ile yendi.
Bu sonuçlar, AlphaStar'ın MaNa ve TLO ile başarısının aslında hızlı operasyonlar, daha hızlı yanıt süreleri veya ham arayüzden ziyade üstün makro ve mikro stratejik kararlardan kaynaklandığını gösteriyor.
İnsanlar 20 yıldır meydan okudu, AI'nın StarCraft'ı yakalamada beş büyük zorluğu var
Oyunun kuralları, oyuncuların üç farklı uzaylı "ırkından" birini -Zerg, Protoss veya Terran'dan birini seçmeleri gerektiğini şart koşuyor, bunların hepsi kendi özelliklerine ve yeteneklerine sahip (profesyonel oyuncular yalnızca bir ırka odaklanma eğiliminde olsa da). Her oyuncu bazı çalışma birimleriyle başlar ve daha fazla birim ve yapı inşa etmek ve yeni teknolojiler oluşturmak için temel kaynakları toplar. Bunlar da oyuncuların diğer kaynakları elde etmesine, daha karmaşık üsler ve yapılar inşa etmesine ve yeni yetenekler geliştirmesine olanak tanır. Rakibi alt etmek için kullanılır.
Oyunun zorluğu, oyuncuların kazanmak için makroekonomik yönetim ve mikro-bireysel kontrol arasında dikkatli bir denge sağlaması gerektiğidir.
Kısa vadeli ve uzun vadeli hedefleri dengelemek ve beklenmedik durumlara uyum sağlama ihtiyacı, genellikle kırılgan ve esnek olmayan sistemler için büyük bir zorluk teşkil eder. Bu sorunu çözmek için, AI araştırmasındaki çeşitli zorlukların aşılması gerekir, bunlar arasında:
Oyun Teorisi: "StarCraft", en iyi stratejiye sahip olmayan, taş-kağıt-makas gibi bir oyundur. Bu nedenle, AI sürecinin stratejik bilginin ön saflarını sürekli olarak keşfetmesi ve genişletmesi gerekir.
Eksik bilgi: Oyuncuların tüm bilgileri görebildiği satranç veya Go'nun aksine, önemli bilgiler yıldızlararası oyunculardan gizlidir ve "keşif" yoluyla aktif olarak keşfedilmelidir.
Uzun vadeli planlama: Pek çok gerçek dünya sorunu gibi, nedensellik de anında oluşmaz. Oyunun herhangi bir yerde tamamlanması da bir saat sürebilir, bu da oyunun erken safhalarında alınan eylemlerin uzun süre işe yaramayacağı anlamına gelir.
gerçek zaman: Oyuncuların sonraki eylemler arasında değiştiği geleneksel masa oyunlarının aksine, "StarCraft" oyuncuları zaman içinde sürekli olarak eylemler gerçekleştirmelidir.
Büyük ölçekli etkinlik alanı: Olası bir kombinasyon alanı oluşturmak için yüzlerce farklı birim ve bina aynı anda gerçek zamanlı olarak kontrol edilmelidir.
StarCraft'ın yapay zeka araştırmaları için "büyük bir zorluk" haline gelmesinin nedeni tam da bu büyük zorluklardır. BroodWar API'nin 2009'da piyasaya sürülmesinden bu yana, AIIDE StarCraft AI yarışması, CIG StarCraft yarışması, öğrenci StarCraft AI yarışması ve "StarCraft 2" AI merdiven yarışması dahil "StarCraft" ve "StarCraft 2" arasındaki yarışmalar devam etmektedir. .
DeepMind, şimdiye kadarki en büyük anonim oyun tekrarlarını içeren PySC2 adlı bir dizi açık kaynak aracı piyasaya sürmek için 2016 ve 2017'de Blizzard ile işbirliği yaptı.
Şimdi, iki yıllık inşaatın ardından, AlphaGo'dan sonra, DeepMind tarafından henüz piyasaya sürülen AlphaStar hızlı bir ilerleme kaydetti.