CIF: Nöron entegrasyonuna dayalı yeni bir konuşma tanıma mekanizması

Yazar | Otomasyon Enstitüsü, Çin Bilimler Akademisi
Editör | Jia Wei
Klasik dikkat konuşma tanıma modelinin çevrimiçi tanımayı, sınır konumlandırmayı vb. Desteklemediği sorununu çözmek için Çin Bilimler Akademisi Otomasyon Enstitüsü'nden Dr. Linhao Dong ve araştırmacı Xu Bo, nabız sinir ağında entegre dağıtım fikrini sürdürdü ve düşük karmaşıklık ve monotonluk önerdi. Tutarlı sıra dönüştürme mekanizması - Sürekli Tümleştir ve Ateşle (CIF). CIF tabanlı model yalnızca çevrimiçi tanımayı, sınır konumunu ve akustik Gömme çıkarımını etkin bir şekilde desteklemekle kalmaz, aynı zamanda iki Çin kıyaslama konuşma tanıma setinde (HKUST, AISHELL-2) SOTA performansı oluşturur. İlgili sonuçlar ICASSP 2020 tarafından Sözlü bildiri olarak kabul edildi.

Tez başlığı: CIF: Uçtan Uca Konuşma Tanıma için Sürekli Entegrasyon ve Ateşleme
Kağıt adresi: https://arxiv.org/pdf/1905.11235.pdf
Dikkat mekanizmasına dayalı uçtan uca model, konuşma tanıma teknolojisinin gelişimini derinden etkiliyor. Bununla birlikte, klasik dikkat tanıma modeli, "konuşma kodlamasından sonra tüm cümleye dikkat etme" özelliği nedeniyle çevrimiçi (akış) tanımayı destekleyememe ve ses sınırı zaman damgaları sağlayamama gibi sorunlarla karşı karşıyadır.
Çin Bilimler Akademisi Otomasyon Enstitüsü'nden Dr. Linhao Dong ve Araştırmacı Xu Bo, darbeli sinir ağında entegrasyon ve dağıtım fikrini sürdürdüler ve düşük karmaşıklıklı, tekdüze ve tutarlı bir dizi dönüştürme mekanizması önerdiler - Sürekli Bütünleştir ve Ateşle (Sürekli Entegre ve Ateş, CIF). CIF, birbiri ardına gelen akustik bilgileri sıralı olarak entegre edecektir Entegre bilginin miktarı tanımlama eşiğine ulaştığında, entegre bilgi sonraki tanımlama için serbest bırakılacaktır. Onun ve dikkat modeli arasındaki hizalama morfolojisi karşılaştırması aşağıdaki Şekil 1'de gösterilmektedir.
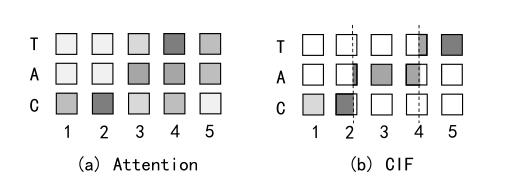
Şekil 1. CIF mekanizması ile dikkat mekanizması arasındaki uyum karşılaştırması
Codec çerçevesine Sürekli Tümleşik Dağıtım (CIF) uygulanır. Her kodlama anında, CIF kodlanmış akustik kodlama temsilini ve buna karşılık gelen ağırlığını alır (içerilen bilgi miktarını karakterize eder). Bundan sonra, CIF sürekli olarak ağırlıkları biriktirir ve akustik kodlama temsilini (ağırlıklı toplama şeklinde) entegre eder.
Birikmiş ağırlık eşiğe ulaştığında, akustik bir sınırın bulunduğu anlamına gelir. Şu anda, CIF, entegre dağıtım modelinin işleme fikrini simüle eder ve mevcut kodlama zamanındaki bilgileri iki bölüme ayırır (Şekil 1'in sağ resminde gösterildiği gibi):
Bir parça, mevcut etiketin akustik bilgilerinin entegrasyonunu tamamlamak için kullanılır (ağırlıklar tam bir dağıtım oluşturabilir).
Diğer kısım, bir sonraki etiketin akustik bilgilerini entegre etmek için kullanılır.
CIF daha sonra ilgili etiketi hemen tahmin etmek için entegre mevcut akustik bilgiyi (Akustik Gömme) kod çözücüye gönderir. Yukarıdaki işlem, kodlanan dizinin sonuna kadar gerçekleştirilir. Sadece bu değil, makale aynı zamanda CIF modelinin performansını daha da iyileştirmek için düzenlileştirme stratejileri ve miktar kaybı gibi bir dizi destekleyici strateji önermektedir.
Araştırma çalışması, CIF modelinin, farklı dilleri ve farklı konuşma türlerini kapsayan çoklu konuşma tanıma karşılaştırma veri kümeleri üzerindeki performansını doğruladı.
Şekil 2'de gösterildiği gibi, Librispeech İngilizce okuma veri setinde, kullanılan çıktı etiketleri net akustik sınırları olmayan alt kelime birimleri olmasına rağmen, CIF tabanlı model hala% 2,86 oranında rekabetçi bir kelime hata oranı elde etmiştir.
Şekil 3'te gösterildiği gibi, Çin okuma veri seti AISHELL-2'de, çıktı etiketleri arasındaki akustik sınır daha net olduğundan, CIF tabanlı model, Chain modelinin performansını önemli ölçüde aşan olağanüstü bir performans elde etti ve bir durum yarattı. son teknoloji kelime hata oranı sonuçları.
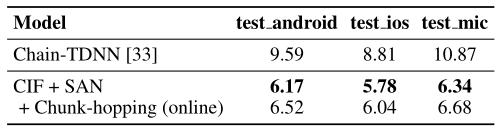
Şekil 4'te gösterildiği gibi, Çin telefon veri seti HKBTÜ'de konuşmada birçok gayri resmi sözlü fenomen olmasına ve veri seti nispeten küçük olmasına rağmen, CIF tabanlı model hala iyi bir genelleme göstererek 23.09 % Son teknoloji ürünü kelime hata oranı sonuçları.
CIF modeli yalnızca yüksek doğrulukta dizi dönüştürme sonuçları sağlamakla kalmaz, aynı zamanda konuşma tanımadaki en önemli telaffuz sınırını doğru bir şekilde bulabilir ve çeşitli bilgi modellerini entegre etmek için konuşma tanıma için yeni bir yol ve yol sağlar. CIF, genişletilebilen ve diğer dizi dönüştürme görevlerine uygulanabilen süreklilik fikrini entegre edecek ve dağıtacaktır.
Bu makalenin çalışmasının araştırma ekibinin 10.000 saatlik büyük ölçekli eğitim verilerinin konuşma tanıma alanında olduğu ve ayrıca ekibin CTC ve Transformer gibi mevcut ana modellerinin mevcut sonuçlarını aştığı bildirildi. Büyük ölçekli uygulamalar için büyük potansiyel.
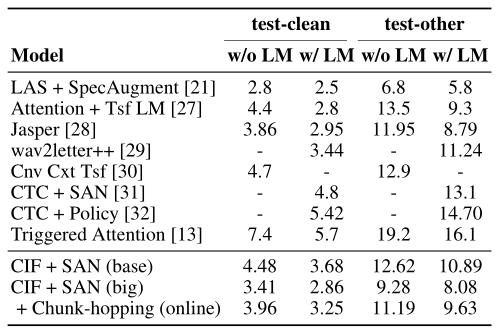
Şekil 2. Librispeech İngilizce okuma veri setinde CIF modeli ile yayınlanmış model arasındaki kelime hata oranlarının karşılaştırılması
Şekil 3. CIF modeli ile Çin okuma veri seti AISHELL-2'de yayınlanan model arasındaki kelime hata oranının karşılaştırılması

Şekil 4. CIF modeli ile Çin telefon veri seti HKUST'ta yayınlanan model arasındaki kelime hata oranının karşılaştırılması