Veri yapısı bu kadar basit mi? // Algoritmalar hakkındaki ilk kitabım

Unsplash'tan
Veri yapısı nedir
Verilerin sırasını ve konumunu belirleyin
Veriler bilgisayarın belleğinde saklanır. Bellek, bir sıra halinde düzenlenmiş kutulara benzeyen sağdaki şekilde gösterildiği gibidir ve bir kutu bir veriyi depolar.

Veriler bellekte depolandığında, verilerin sırasını ve konumunu belirleyen "veri yapısı" dır.
Telefon rehberinin veri yapısı
Örnek : yukarıdan aşağıya sırayla ekleyin
Basit bir örnek verin. Bir telefon rehberimiz olduğunu varsayalım - şu anda birçok kişi telefon numaralarını cep telefonlarında saklasa da burada bir kağıt telefon rehberi kullanmayı düşünüyoruz - ne zaman yeni bir telefon numarası alsak, yukarıdan aşağıya basın Bunları bulundukları sırayla telefon defterine kaydedin.

Şu anda "Zhang Wei" yi aramak istediğimizi varsayalım, ancak veriler edinme sırasına göre düzenlendiği için Zhang Wei'nin numarasının nerede olduğunu bilmiyoruz ve yalnızca üstten tek tek bakabiliyoruz (ancak yine de " "Arkadan arama" veya "rastgele arama", ancak verimlilik "yukarıdan aşağıya arama" dan daha yüksek değildir). Telefon rehberinde çok fazla numara yoksa, bunları hızlı bir şekilde bulabilirsiniz, ancak 500 numara kaydederseniz, onları bulmak kolay olmayacaktır.
Örnek : Adların alfabetik sırasına göre düzenleyin
Ardından, kişi adlarını fonetik sıraya göre düzenlemeye çalışın. Veriler sözlük sırasına göre düzenlendiği için bir "yapıya" sahiptirler.
Kişileri bu şekilde sıralamak, hedef kişiyi bulmayı kolaylaştırır. Verilerin yaklaşık konumu, ismin pinyin baş harflerinden anlaşılabilir.
Peki, alfabetik sıraya göre düzenlenmiş bu telefon defterine veri nasıl eklenir? Yeni bir arkadaşımız "Ke Jinbo" ile tanıştığımızı ve onun telefon numarasını aldığımızı ve numarayı telefon defterine kaydetmeyi planladığımızı varsayalım. Veriler, adların fonetik sırasına göre düzenlendiğinden, Ke Jinbo, Han Hongyu ve Li Xi arasında yazılmalıdır, ancak yukarıdaki tabloyu doldurmak için yer yoktur, bu nedenle Li Xi'yi ve aşağıdaki verileri hareket ettirmeniz gerekir 1 Kürek çekmek.
Bu noktada aşağıdan yukarıya "bu satırın içeriğini bir sonraki satıra yaz ve sonra bu satırın içeriğini sil" işlemini gerçekleştirmemiz gerekiyor. Toplam 500 veri varsa ve bir işlem 10 saniye sürüyorsa bu çalışma 1 saatte tamamlanamaz.
İki yöntemin avantajları ve dezavantajları
Genel olarak, veriler edinim sırasına göre düzenlenmişse, verileri eklemek çok basit olsa da, yalnızca veriyi sonuna eklemeniz gerekir, ancak sorgulamak daha zahmetlidir; pinyin sırasına göre düzenlenmişse, sorgu nispeten basit olmasına rağmen, Ancak veri eklerken daha zahmetli olacaktır.
Bu iki yöntemin kendi avantajları ve dezavantajları olmasına rağmen, özel seçim yine de telefon rehberinin kullanımına bağlıdır. Telefon rehberi tamamlandıktan sonra yeni numara eklenmezse, ikincisi daha uygundur; sık sık yeni numaralar eklemeniz gerekiyorsa, ancak tekrar kontrol etmeniz gerekmiyorsa, ilkini seçmelisiniz.
Satın alma sırasını pinyin siparişi ile birleştirmeye ne dersiniz?
İkisinin avantajlarını birleştiren yeni bir düzenleme yöntemini de düşünebiliriz. Yani, tablo L, tablo M, tablo N, vb. Gibi farklı pinyin baş harflerini depolamak için farklı tablolar kullanmak ve ardından aynı tablodaki verileri elde etme sırasına göre düzenlemek.


Bu şekilde, yeni veri eklerken, verileri doğrudan ilgili tablonun sonuna ekleyebilir ve verileri sorgularken yalnızca ilgili tabloyu bulmanız gerekir.
Her tabloda depolanan veriler hala düzensiz olduğundan, sorgulama sırasında tablonun başından başlamak gerekir, ancak yine de tüm telefon rehberini sorgulamaktan çok daha kolaydır.
Bellek kullanımını iyileştirmek için doğru veri yapısını seçin
Veri yapısı fikri, telefon rehberi oluştururkenki ile aynıdır. Verileri hafızaya kaydederken, kullanım amacına göre uygun bir veri yapısının seçilmesi hafıza kullanımını geliştirebilir.
Bu makale 7 veri yapısını açıklayacaktır. Başlangıçta belirtildiği gibi, veriler bellekte doğrusal olarak düzenlenir, ancak bir "ağaca" benzer karmaşık bir yapı oluşturmak için işaretçiler gibi sahne öğelerini de kullanabiliriz.
1. Bağlantılı liste
Bağlantılı liste, verilerin doğrusal olarak düzenlendiği veri yapılarından biridir. Bağlantılı listede veri eklemek ve silmek daha uygundur, ancak erişim zaman alıcıdır.

Bu, bağlantılı listenin kavramsal diyagramıdır. Mavi, Sarı ve Kırmızı üç dizi, bağlantılı listede veri olarak saklanır. Her verinin, sonraki verinin hafıza adresini gösteren bir "işaretçisi" vardır.

Bağlantılı listede, veriler genellikle dağınık bir şekilde bellekte saklanır ve sürekli bir alanda depolanması gerekmez.

Veriler ayrı olarak depolandığından, verilere erişmek istiyorsanız, yalnızca ilk verilerden başlayabilir ve tek tek erişmek için işaretçiyi takip edebilirsiniz (bu sıralı erişimdir). Örneğin, Red'in verilerini bulmak istiyorsanız, Blue'dan erişmeye başlamalısınız.

Bundan sonra, Kırmızıyı bulabilmemiz için önce Sarıyı geçmek zorundayız.

Veri eklemek istiyorsanız, işaretçileri yalnızca konum eklemeden önce ve sonra değiştirmeniz gerekir ki bu çok basittir. Örneğin, Mavi ve Sarı arasına Yeşil ekleyin.
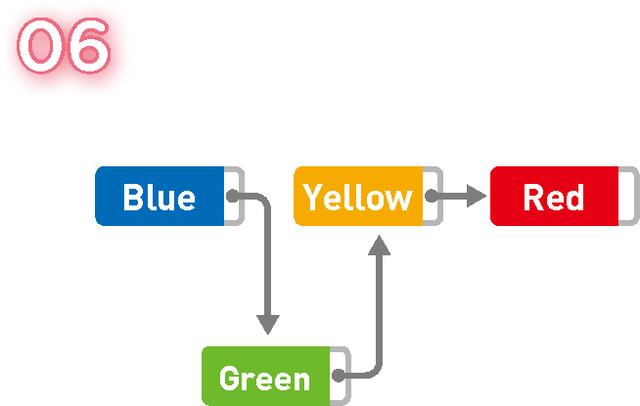
Mavinin işaretçisinin konumunu Yeşil olarak değiştirin ve ardından Yeşil'in işaretçisini Sarı olarak işaretleyin ve veriler eklenir.

Sarı silme gibi işaretçi değiştirildiği sürece aynı durum veri silme için de geçerlidir.

Şu anda, yalnızca Yeşil işaretçinin gösterdiği konumu Sarıdan Kırmızıya değiştirmeniz gerekir ve silme işlemi tamamlanır. Yellow'un kendisi hala bellekte saklansa da, bu verilere herhangi bir yerden erişilemez, bu nedenle kasıtlı olarak silmeye gerek yoktur. Gelecekte Yellow'un bulunduğu depolama alanını kullanmanız gerektiğinde, yeni verilerle üzerine yazın.
Yorum
Bağlantılı listenin çalışması için gereken çalışma süresi nedir? Burada bağlantılı listedeki veri miktarını n olarak kaydediyoruz. Verilere erişirken, bağlantılı listenin başından arama yapmamız gerekir (doğrusal arama) Hedef veri bağlantılı listenin sonunda ise, gerekli zaman O (n) 'dur.
Ek olarak, veri eklemenin yalnızca iki işaretçinin noktalarını değiştirmesi gerekir, bu nedenle harcanan zamanın n ile ilgisi yoktur. Veri eklenecek yere ulaşılmışsa, ekleme işlemi yalnızca O (1) süresi alır. Ayrıca verileri silmek yalnızca O (1) zaman alır.
Referans: 3-1 doğrusal arama
Ek
Yukarıda açıklanan bağlantılı liste, en temel bağlantılı liste türüdür. Ek olarak, genişletilmesi kolay birkaç bağlantılı liste vardır.
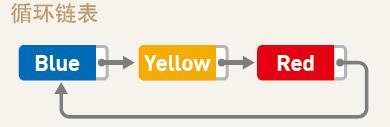
Yukarıda bahsedilen bağlantılı listenin sonunda bir işaretçi olmamasına rağmen, bağlantılı listenin sonunda bir işaretçi kullanabilir ve bağlantılı listenin başındaki veriye işaret ederek bağlantılı listeyi bir halkaya çevirebiliriz. Bu, "döngüsel bağlantılı liste" olarak da adlandırılan "döngüsel bağlantılı liste" dir. Dairesel bağlantılı listenin baş ve kuyruk kavramı yoktur. Bu tür bağlantılı liste genellikle en son verilerin sabit bir miktarını kaydetmek istediğinizde kullanılır.
Ek olarak, yukarıdaki bağlantılı listedeki her verinin sadece bir işaretçisi vardır, ancak işaretçileri ikiye ayarlayabilir ve sırasıyla ön ve arka veriyi göstermelerine izin verebiliriz Bu bir "çift bağlantılı liste" dir. Bu tür bir bağlantılı listeyi kullanarak, verileri sadece önden arkaya değil, aynı zamanda arkadan öne de geçirebilirsiniz, bu da çok uygundur.
Bununla birlikte, çift bağlantılı listelerin iki dezavantajı vardır: Birincisi, işaretçilerin sayısındaki artışın depolama alanı gereksinimlerini artırması; diğeri, veri eklerken ve silerken daha fazla işaretleyicinin değiştirilmesi gerekmesidir.

2. Dizi
Dizi ayrıca verilerin doğrusal olarak düzenlendiği bir veri yapısıdır. Önceki bölümdeki bağlantılı listeden farklı olarak, dizide verilere erişim çok basittir, veri eklemek ve silmek daha fazla zaman alır. Bu, isimlerin Pinyin sırasına göre düzenlendiği telefon defterine benzer.

Bu, dizinin kavramsal diyagramıdır. Mavi, Sarı ve Kırmızı, bir dizide veri olarak saklanır.

Veriler, belleğin sürekli alanında sıralı olarak saklanır.

Veriler sürekli bir alanda depolandığından, her verinin bellek adresi (bellekteki konum) dizi alt simge tarafından hesaplanabilir ve hedef verilere doğrudan erişebiliriz (buna "rastgele erişim" denir) ).

Örneğin, şimdi Red'i ziyaret etmek istiyoruz. Bir işaretçi kullanırsanız, yalnızca baştan arama yapabilirsiniz, ancak dizide, Red'e doğrudan erişmek için yalnızca a belirtmeniz gerekir.

Bununla birlikte, herhangi bir konumda veri eklemek veya silmek isterseniz, dizinin işleyişi bağlantılı listeden çok daha karmaşıktır. Burada Green'i ikinci konuma eklemeye çalışıyoruz.

Öncelikle dizinin sonunda artırılması gereken depolama alanını sağlayın.

Yeni verilere yer açmak için mevcut verilerin birer birer taşınması gerekir. Önce Red'i geri çek.

Sonra Sarıyı geri hareket ettirin.

Son olarak, serbest pozisyonda Green yazın.

Veri ekleme işlemi tamamlandı.

Tersine, Green'i silmek isterseniz ...
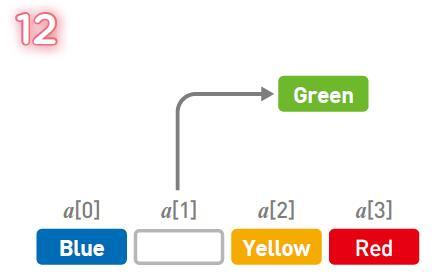
Önce hedef verileri silin (bu durumda Yeşil).

Ardından aşağıdaki verileri tek tek kaydırın. Önce Sarıyı ileri doğru hareket ettirin.

Sıradaki hareket Kırmızı.

Son olarak fazla boşluğu silin. Bu şekilde Green silindi.
Yorum
Dizi işlemlerinde harcanan çalışma süresini açıklamak için burada. Dizide n veri olduğunu varsayarsak, verilere erişilirken rastgele erişim kullanıldığından (bellek adresi alt simge aracılığıyla hesaplanabilir), gerekli çalışma süresi yalnızca sabit O (1) 'dir.
Ancak diğer yandan diziye yeni veri eklemek istediğinizde veriyi tek tek hedef konumun arkasına taşımanız gerekir. Bu nedenle, dizinin başına veri eklerseniz, O (n) süresi alır. Silme işlemi aynıdır.
Ek
Bağlı listelerde ve dizilerde, veriler bir sütunda doğrusal olarak düzenlenir. Bağlantılı bir listedeki verilere erişmek daha karmaşıktır ve veri eklemek ve silmek nispeten basittir; bir dizideki verilere erişmek nispeten basittir, ancak veri eklemek ve silmek daha karmaşıktır.
Hangi işlemin daha sık olduğuna göre hangi veri yapısının kullanılacağına karar verebiliriz.

3. Yığın
Yığın aynı zamanda verinin doğrusal olarak düzenlendiği bir veri yapısıdır, ancak bu yapıda sadece yeni eklenen verilere ulaşabiliyoruz. Yığın kitap yığını gibidir.Yeni bir kitap aldığımızda, onu yığının en üstüne koyarız.Bir kitap aldığımızda, sadece en iyi yeni kitapla başlayabiliriz.

Bu, yığının kavramsal diyagramıdır. Artık yığında yalnızca Mavi veri saklanıyor.

Ardından, Yeşil veri yığına eklenir.

Ardından, Kırmızı verisi yığına aktarılır.

Yığından veri getirilirken, en üstten, yani en son verilerden getirilir. Buradan çıkarılan Red.

Yığın işlemi tekrar yapılırsa, Yeşil renk alınacaktır.
Yorum
Yığın gibi en son eklenen veriler önce çıkarılır, yani Last InFirst Out veya kısaca LIFO dediğimiz "son giren ilk çıkar" yapısı.
Bağlantılı listeler ve diziler gibi, yığındaki veriler de doğrusal olarak düzenlenir, ancak yığında, veri ekleme ve silme işlemleri yalnızca bir uçta gerçekleştirilebilir ve verilere erişim yalnızca en önemli verilere erişebilir. Ortadaki verilere erişmek istediğinizde, hedef verileri fırlatarak yığının en üstüne taşımalısınız.
Uygulama örneği
Yığının yalnızca bir uçta çalıştırılabilmesi sakıncalı görünebilir, ancak yalnızca en son verilere erişmeniz gerektiğinde onu kullanmak daha uygundur.
Örneğin, bir karakter dizisindeki (AB (C (DE) F) (G ((H) IJ) K)) parantezlerin şu şekilde işlenmesi şart koşulmuştur: Önce soldan karakterleri okuyun ve Yığın, sağ parantezi okuyun ve yığının en üstünde sol parantezi açın. Şu anda, sol parantez şu anda okunan sağ parantezle eşleşiyor. Bu şekilde, eşleştirilmiş parantezlerin belirli konumunu bilebiliriz.
Ek olarak, önce derinlik arama algoritması genellikle en son verileri aday köşe noktaları olarak seçer. Yığın, aday köşelerin yönetiminde kullanılabilir.
4. Sıra
Daha önce bahsedilen veri yapısıyla aynı şekilde, kuyruktaki veriler de doğrusal olarak düzenlenir. Yığına biraz benzer olsa da, kuyruğa veri ekleme ve silme işlemleri her iki uçta da gerçekleştirilir. Tıpkı "queue" adı gibi, onu bir insan grubu olarak anlamak daha kolaydır. Kuyrukta işlem her zaman ilk yerden başlar ve geri gider ve yeni gelenler yalnızca kuyruğun sonunda olabilir.

Bu, kuyruğun kavramsal diyagramıdır. Artık kuyrukta yalnızca Mavi veri var.
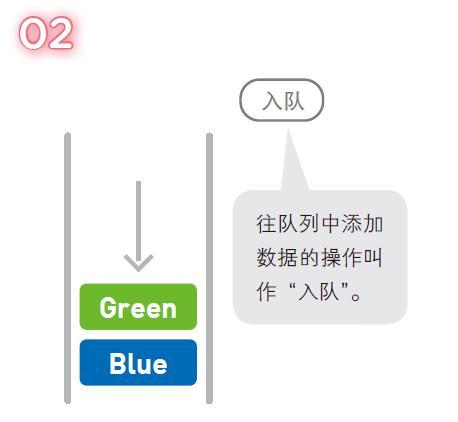
Ardından, Yeşil veri kuyruğa eklenir.

Hemen ardından Red verileri de ekibe katıldı.

Kuyruktan veri alırken (silerken), en alttan, yani kuyruktaki en eski verilerden başlar. Buradan çıkarılan Blue.

Başka bir kuyruktan çıkarma işlemi gerçekleştirirseniz, Yeşil renk alınacaktır.
Yorum
Kuyruk gibi en gelişmiş veriler ilk önce getirilir, yani First InFirst Out veya kısaca FIFO olarak adlandırdığımız "ilk giren ilk çıkar" yapısı.
Yığına benzer şekilde, kuyrukta manipüle edilebilecek verilerin konumu konusunda belirli kısıtlamalar vardır. Yığın içerisinde veri toplama ve silme işlemleri aynı uçta, kuyruktayken her iki uçta da gerçekleştirilir. Sıra ayrıca ortada bulunan verilere doğrudan erişemez ve kuyruktan çıkarma işlemi aracılığıyla hedef veriler ilk sırada olduktan sonra erişilmesi gerekir.
Uygulama örneği
"İlk gelen veriler önce işlenir" çok yaygın bir fikirdir, bu nedenle kuyrukların uygulama aralığı çok geniştir. Örneğin, en geniş arama algoritması genellikle bir sonraki tepe noktası olarak arama adaylarından en erken verileri seçer. Bu durumda kuyruk, aday köşelerin yönetimi için kullanılabilir.
5. Hash tablosu
Karma tablonun veri yapısında, "karma işlevi" kullanımı veri sorgusunun verimliliğini önemli ölçüde artırabilir.

Karma tablo, anahtarlardan ve değerlerden oluşan verileri depolar. Örneğin, her bir kişinin cinsiyetini veri olarak saklıyoruz, anahtar isim ve değer karşılık gelen cinsiyettir.

Hash tablosu ile karşılaştırmak için önce bu verileri bir dizide saklıyoruz.

Burada, verileri depolamak için 6 kutu (yani 6 uzunluklu bir dizi) hazırlanmıştır. Ally'nin cinsiyetini sorgulamamız gerektiğini varsayalım, Ally'nin verilerinin hangi kutuda saklandığını bilmediğimiz için, sadece baştan sorgulayabiliriz. Bu işleme "doğrusal arama" denir.
İpucu: Genel olarak konuşursak, anahtarı verilerin tanımlayıcısı ve değeri de verilerin içeriği olarak ele alabiliriz.

Kutu 0'da saklanan anahtar Ally değil Joe'dur.

Kutu 1'deki Ally değil.

Benzer şekilde, ne 2. kutu ne de 3. kutu Ally'dir.

4 numaralı kutuyu bulduğumda, içindeki verilerin anahtarının Ally olduğunu buldum. Anahtara karşılık gelen değeri çıkardığımızda, Ally'nin cinsiyetinin kadın (F) olduğunu biliyoruz.

Daha fazla veri, doğrusal arama daha uzun sürer. Görülebileceği gibi: veri sorgusu nispeten zaman aldığından, burada veri depolamak için bir dizi kullanmak uygun değildir.

Bu sorunu çözmek için karma tablolar kullanın. Önce diziyi hazırlayın, bu sefer verileri depolamak için 5 kutudan oluşan bir dizi kullanıyoruz.

Joe'yu içeri kurtarmaya çalışın.
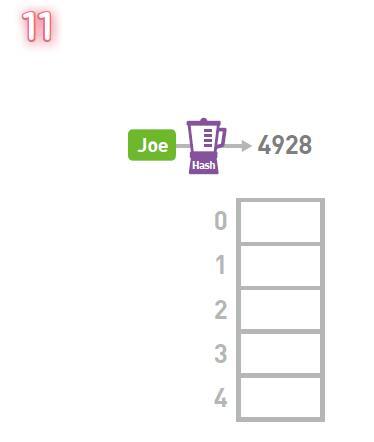
"Joe" dizesinin karma değeri olan Joe'nun anahtarını hesaplamak için bir karma işlevi (Hash) kullanın. Elde edilen sonuç 4928'dir (karma işlevi verilen verileri sabit uzunlukta düzensiz bir değere dönüştürebilir. Dönüştürülen düzensiz değer, çeşitli senaryolar için bir veri özeti olarak kullanılabilir).

Kalan sayıyı bulmak için elde edilen hash değerini dizinin uzunluğuna 5'e bölün. Bu tür kalan işlemlere "mod işlemleri" denir. Buradaki mod işleminin sonucu 3'tür.

Bu nedenle, Joe'nun verilerini dizinin 3. kutusunda saklıyoruz. Dizideki diğer verileri saklamak için önceki işlemi tekrarlayın.

Sue anahtarının hash değeri 7291, mod 5'in sonucu 1 ve Sue verileri kutu 1'de saklanıyor.

Dan anahtarının karma değeri 1539'dur ve mod 5'in sonucu 4'tür. Dan'in verilerini kutu 4'te saklayın.

Nell anahtarının hash değeri 6276'dır ve mod 5'in sonucu 1'dir. Dizinin 1. kutusunda saklanmalıydı, ancak şu anda Sue'nun verileri kutu 1'de saklanıyordu. Bu tür çoğaltılmış depolama konumuna "çakışma" denir.

Bu durumda, mevcut verilerin arkasında yeni verileri depolamaya devam etmek için bağlantılı listeyi kullanabilirsiniz.

Ally anahtarının hash değeri 9143 ve mod 5'in sonucu 3'tür. Dizinin 3. kutusunda saklanması gerekiyordu, ancak Joe'nun verileri zaten kutu 3'te, bu nedenle bağlantılı bir liste kullanılıyor ve Ally'nin verileri arkasında saklanıyor.

Bob anahtarının hash değeri 5278'dir ve mod 5'in sonucu 3'tür. Dizinin 3. kutusunda saklanmalıydı, ancak Joe ve Ally'nin verileri 3. kutuda zaten mevcuttu, bu nedenle Bob'un verilerini Ally'nin arkasında saklamak için bağlantılı bir liste kullanılır.

Bunun gibi tüm verileri sakladıktan sonra hash tablosu tamamlanır.
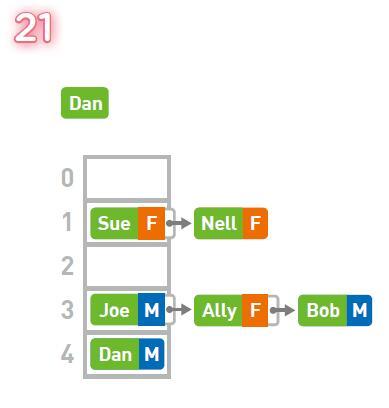
Ardından, verilerin nasıl sorgulanacağını açıklayın. Dan'in cinsiyetini sorgulamak istediğimizi varsayalım.

Dan'in hangi kutuda saklandığını bilmek için önce Dan anahtarının hash değerini hesaplamanız ve ardından mod işlemini gerçekleştirmeniz gerekir. Nihai sonuç 4, dolayısıyla 4. kutuda saklandığını biliyoruz.

Kutu 4'e baktığımızda, içindeki verilerin anahtarının Dan ile tutarlı olduğunu görebiliriz, bu nedenle karşılık gelen değeri çıkarın. Bundan Dan'in cinsiyetinin erkek (M) olduğunu biliyoruz.

Peki Ally'nin cinsiyetini sorgulamak istediğimde ne yapmalıyım? Depo yerini bulmak için önce Ally anahtarının hash değerini hesaplayın ve ardından mod işlemini gerçekleştirin. Nihai sonuç 3'tür.

Ancak, kutu 3'teki verilerin anahtarı Ally değil Joe'dur. Şu anda, Joe'nun bulunduğu bağlantılı listede doğrusal bir arama yapmak gerekir.

Ally ile ilgili verileri bulduk. Karşılık gelen değerini çıkarın ve Ally'nin cinsiyetinin kadın (K) olduğunu biliyorsunuz.
Yorum
Hash tablosunda, dizideki hedef verilere hızlıca erişmek için hash fonksiyonunu kullanabiliriz. Bir hash çakışması meydana gelirse, depolama için bağlantılı bir liste kullanılır. Bu şekilde, veri miktarından bağımsız olarak esnek bir şekilde yanıt verebiliriz.
Dizinin alanı çok küçükse, hash tablosu kullanılırken çakışmalar meydana gelebilir ve doğrusal aramanın frekansı daha yüksek olacaktır; tersine, dizinin alanı çok büyükse, birçok boş kutu görünecek ve bellek israfına neden olacaktır. Bu nedenle, dizi için uygun bir alan ayarlamak çok önemlidir.
Ek
Veri saklama sürecinde, bir çakışma meydana gelirse, bağlantılı liste, çakışmayı çözmek için mevcut verilerden sonra yeni veriler eklemek için kullanılabilir. Bu yönteme "zincir adres yöntemi" denir.
Zincir adres yöntemine ek olarak, çakışmaları çözmenin birkaç yolu vardır. Bunların arasında "açık adres yöntemi" yaygın olarak kullanılmaktadır. Bu yöntem, bir çakışma meydana geldiğinde, alternatif bir adresin (dizideki konum) hemen hesaplandığı ve verilerin saklandığı anlamına gelir. Hala bir çakışma varsa, ücretsiz bir adres olana kadar bir sonraki alternatif adresi hesaplamaya devam edin. Aday adres, bir karma işlevi veya "doğrusal algılama yöntemi" birden çok kez kullanılarak hesaplanabilir.
Ek olarak, hash fonksiyonundaki "orijinal değer, hash değerine göre hesaplanamaz". Bununla birlikte, bu yalnızca şifrelere ve diğer güvenlik özelliklerine karma tablolar uygularken dikkat edilmesi gereken bir durumdur ve karma tabloları kullanırken izlenmesi gereken bir kural değildir.
Veri depolamada karma tabloların esnekliği ve veri sorgularının verimliliği nedeniyle, genellikle programlama dillerinin ilişkilendirilebilir dizileri kullanılır.
6. Yığın
Yığın, "öncelik sıralarını" uygulamak için kullanılan grafiklerin ağaç yapısıdır. Öncelik kuyruğu bir veri yapısıdır, verileri özgürce ekleyebilirsiniz ancak veriyi çıkardığınız zaman minimumdan sırayla çıkarmanız gerekir. Yığının ağaç yapısında, her tepe noktasına "düğüm" adı verilir ve veriler bu düğümlerde depolanır.

Bu bir yığın örneğidir. Düğümdeki sayı saklanan verilerdir. Yığın içindeki her düğümün en fazla iki alt düğümü vardır. Ağacın şekli veri sayısına bağlıdır. Ek olarak, düğümlerin sırası aynı satırda yukarıdan aşağıya ve soldan sağa doğrudur.

Yığın içinde veri depolarken, bir kurala uyulmalıdır: alt düğüm, ana düğümden daha büyük olmalıdır. Bu nedenle, minimum değer üst kök düğümde saklanır. Yığına veri eklerken bu kurala uymak için yeni veriler genellikle sol alt satıra yerleştirilir. Alt satırda fazladan boşluk kalmadığında, aşağı başka bir satıra başlayın ve verileri bu satırın en sol ucuna ekleyin.

5 sayısını yığına eklemeyi deneyelim.
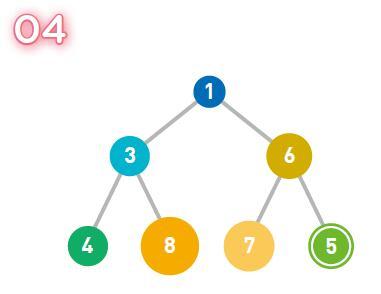
Yeni verilerin yerini bulmak için ilk olarak 02'deki talimatları izleyin. Şekildeki alt satır boş, bu nedenle verileri buraya ekleyin.

Ebeveyn düğüm, alt düğümden daha büyükse, yukarıda belirtilen kurallara uymaz, bu nedenle üst ve alt düğümlerin konumlarının değiştirilmesi gerekir.

Burada, ebeveyn düğümün 6'sı, alt düğümün 5'inden daha büyük olduğu için, iki sayı değiş tokuş edilir. Veriler kuralları karşılayana ve artık değiş tokuş edilmesine gerek kalmayana kadar bu işlemi tekrarlayın.

Şimdi, ebeveyn düğümün 1'i, çocuk düğümün 5'inden daha azdır ve ebeveyn düğümün sayısı daha küçüktür, bu nedenle daha fazla değişim yok.

Bu sayede yığına veri ekleme işlemi tamamlanmış olur.

Veri yığından alındığında, en üstteki veriler çıkarılır. Bu şekilde, yığındaki en üstteki veriler her zaman minimumda tutulabilir.

En üstteki veriler çıkarıldığı için, öbek yapısının da yeniden ayarlanması gerekir.

Son veriyi (bu durumda 6) 01'de açıklanan sırayla en üste taşıyın.
Çocuk düğümün sayısı ebeveyn düğümün sayısından küçükse, ebeveyn düğüm iki sol ve sağ çocuk düğümden daha küçük olanıyla değiştirilir.

Burada, ebeveyn düğümün 6'sı çocuk düğümün 5'inden (sağda) ve çocuk düğümün 3'ünden (solda) büyük olduğundan, soldaki çocuk düğüm ebeveyn düğümle değiştirilir. Veriler kurallara uyana ve artık değiş tokuş edilmesine gerek kalmayana kadar bu işlemi tekrarlayın.

Şimdi, çocuk düğümün 8'i (sağda), ebeveyn düğümün 6'sından ve çocuk düğümün 4'ünden daha büyüktür (solda) Soldaki çocuk düğümü ebeveyn düğümle değiştirmelisiniz.

Bu sayede yığından veri alma işlemi tamamlanmış olur.
Yorum
Yığın içindeki en üstteki veri her zaman en küçüktür, bu nedenle ne kadar veri olursa olsun, en küçük değeri getirmenin zaman karmaşıklığı O (1) 'dir.
Ek olarak, son verilerin verileri getirdikten sonra en üste taşınması ve ardından alt düğüm verilerinin boyutuyla karşılaştırılırken aşağı taşınması gerektiğinden, verileri almak için gereken çalışma süresi ağacın yüksekliğiyle orantılıdır. Veri miktarının n olduğunu ve ağacın yüksekliğinin yığının şekil özelliklerine göre logn olduğunu varsayarsak, ağacı yeniden yapılandırmanın zaman karmaşıklığı O (logn) olur.
Aynı şey veri eklemek için de geçerli. Yığının sonuna veri ekledikten sonra, veriler onu ana düğüm verilerinin boyutuyla karşılaştıracak ve yığın koşulları karşılanana kadar yukarı hareket edecektir.Bu nedenle, veri eklemek için gereken çalışma süresi ağacın yüksekliğiyle orantılıdır, bu da O ( logn).
Uygulama örneği
Yönetilen verilerden sık sık minimum değeri çıkarmanız gerekiyorsa, yığını kullanmak için çok uygundur. Örneğin, Dijkstra algoritmasında, her adımın, aday köşelerden başlangıç noktasına en yakın köşeyi seçmesi gerekir. Bu noktada, yığın, köşe seçiminde kullanılabilir.
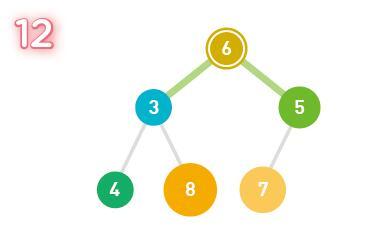
7. İkili arama ağacı
İkili arama ağacı (ikili arama ağacı veya ikili sıralama ağacı olarak da bilinir), grafiklerin ağaç yapısını kullanan bir veri yapısıdır. Veriler, ikili arama ağacının her bir düğümünde saklanır.

Bu bir ikili arama ağacı örneğidir. Düğümdeki sayı saklanan verilerdir. Buradaki açıklama aynı numaranın mevcut olmadığını varsayar.

İkili arama ağacının iki özelliği vardır. Birincisi, her bir düğümün değerinin, sol alt ağacındaki herhangi bir düğümün değerinden daha büyük olmasıdır. Örneğin, düğüm 9, sol alt ağacında 3'ten ve 8'den büyüktür.

Benzer şekilde, düğüm 15 de sol alt ağacındaki herhangi bir düğümün değerinden daha büyüktür.

İkincisi, her bir düğümün değerinin, sağ alt ağaçtaki herhangi bir düğümün değerinden daha az olmasıdır. Örneğin, düğüm 15, sağ alt ağacında 23, 17 ve 28'den küçüktür.

Bu iki özelliğe göre aşağıdaki sonuçlara varılabilir. Her şeyden önce, ikili arama ağacının minimum düğümü yukarıdan başlamalı ve sol alt ucu aramalıdır. Buradaki minimum değer 3'tür.

Tersine, ikili arama ağacının en büyük düğümü üstten başlar ve sağ altta sonu arar. Buradaki maksimum değer 28'dir.

İkili arama ağacına veri eklemeye çalışalım. Örneğin, 1 sayısını ekleyin.

İlk olarak, sayıların ekleneceği konumu bulmak için ikili arama ağacının en üst düğümünden başlayın. Eklemek istediğiniz 1'i düğümdeki değerle karşılaştırın, ondan küçükse sola, ondan büyükse sağa taşıyın.

1