Apple'ın makine öğrenimi geliştirme günlüğü: Apple Watch'ta gerçek zamanlı olarak çalışabilen bir Çin el yazısı tanıma sistemi nasıl tasarlanır
Lei Feng.com AI teknolojisi yorumu: Apple ML Journal'ın açılmasıyla birlikte Apple, kendi ürünlerini tasarlama ve sorunları çözmek için makine öğrenimini kullanma hakkında giderek daha fazla hikaye paylaştı. Son zamanlarda Apple, el yazısı Çince'nin tanınması üzerine bir makale yayınladı ve bu işlevin kendi düşünme ve uygulama sürecini tanıttı. Yazıda yepyeni bir teknoloji bulunmasa da samimi bir gelişim deneyimi paylaşımıdır. Lei Feng.com AI Technology Review makaleyi aşağıdaki gibi derledi.

Cep telefonları ve tabletler gibi mobil cihazlar ve akıllı saatler gibi giyilebilir cihazlar popüler hale geldikçe ve hatta vazgeçilmez hale geldikçe, el yazısı tanıma her zamankinden daha önemli hale geldi. Çince, büyük bir karakter kitaplığı içerir ve bu mobil cihazlarda Çince el yazısı tanımayı desteklemek, benzersiz bir dizi zorluk getirir. Bu makalede Apple, Çin el yazısının gerçek zamanlı tanınmasını sağlamak için iPhone, iPad ve Watch'ta (çizim modunda) bu zorluklara nasıl yanıt verdiklerini tanıttı. Apple'ın derin öğrenme tabanlı tanıma sistemi, 30.000'e kadar farklı karakteri doğru şekilde işleyebilir. Makul doğruluk elde etmek için, Apple'ın geliştiricileri akıllarını veri toplama modlarına, yazma yöntemlerinin temsiline ve eğitim yöntemlerine adadılar. Uygun yöntem kullanıldığı sürece daha büyük bir karakter kitaplığının bile çözülebileceğini buldular. Deneyler, eğitim verilerinin kalitesi yeterince yüksek ve miktar yeterince büyük olduğu sürece, karakter kitaplığı arttıkça tanıma doğruluğunun ancak yavaş yavaş azalacağını gösteriyor.
Giriş
El yazısı tanıma, mobil cihazların kullanıcı deneyimini geliştirebilir, özellikle Çince klavye girişi nispeten karmaşıktır. Çince'nin arkasındaki karakter kitaplığı çok büyük olduğu için Çince el yazısı tanıma da benzersiz bir şekilde zordur. Alfabeye dayalı diğer dillerde, karakterlerin büyüklük sırası genellikle 100 civarındayken, Çin ulusal standardı GB18030-200527.533 Çince karakter içerir ve Çin'de hala kullanımda olan birçok grafik karakter vardır.
Bilgisayarda işlemeyi kolaylaştırmak için yaygın bir uygulama, yalnızca bazı karakterlere odaklanmak ve genellikle günlük kullanımda en temsili karakterleri seçmektir. Bu fikre göre, Çin ulusal standart karakter seti GB2312-80 yalnızca 6763 karakter içerir (3755 birinci seviye karakter ve 3008 ikinci seviye karakter dahil). Çin Bilimler Akademisi Otomasyon Enstitüsü de birbirine çok yakın bir karakter seti oluşturdu ve bunu toplam 7356 karakter içeren CASIA veritabanında kullandı. SCUT-COUCH veri tabanının kapasitesi de aynı seviyededir.
Bu karakter kümeleri temelde Çin genelinde yazarların yaygın olarak kullanılan karakterlerini yansıtır. Bununla birlikte, kişisel düzeyde, "en sık kullanılan kelimeler" genellikle kişiden kişiye farklılık gösterir. Pek çok insan en az düzinelerce kendi "alışılmadık kelimesine" sahiptir, çünkü bu kelimeler aslında tek tek yazmak yerine ilgili şeylerin adlarında yer almaktadır. Bu şekilde, ideal koşullar altında Çince el yazısı tanıma algoritması GB18030-2005'te en azından 20.000'den fazla Çince karakter seviyesine genişletilmelidir.
Erken tanıma algoritmaları esas olarak tek vuruşlu analize dayalı yapılandırılmış bir yönteme dayanıyordu. Daha sonra, insanların istatistiksel yöntemler oluşturmak için genel şekil bilgilerini kullanma ilgisini uyandıran felç sırasının etkisini ortadan kaldırma ihtiyacı doğdu. Bununla birlikte, metin kategorilerinin sayısı ne kadar fazla olursa, metni tek bir kategori altında açıkça sınıflandırmak o kadar zordur.Bu yöntemler, büyük karakter kümeleri altında tanımanın zorluğunu büyük ölçüde artıracaktır.
MNIST gibi Latin karakter tanıma görevleri için, Convolutional Neural Networks (CNN) hızlı bir şekilde çok büyük bir avantaj gösterdi. Yeterli eğitim verisi olduğu ve bazı gerekli üretilmiş örnekler uygun şekilde desteklendiği sürece, CNN şüphesiz en yüksek performansı elde edebilir. Ancak bu çalışmalardaki karakter kategorileri oldukça küçüktür.
Daha önce, Apple araştırmacıları büyük ölçekli Çince karakter tanımanın nasıl yapılacağını incelemeye başladığında, CNN'in seçilmesi gerekiyordu. Ancak, CNN yönteminin ağı 30.000'e yakın karakter içerecek şekilde genişletmesi ve aynı zamanda gömülü cihazlarda gerçek zamanlı tanıma performansını sağlaması gerekir. Bu makalenin odak noktası, ideal performansı elde etmek için gecikme, karakter kapsamı, yazı stilinin sağlamlığı vb. Sorunların nasıl çözüleceğini tanıtmaktır.
Sistem yapılandırması
Apple araştırmacıları, bu çalışmada, daha önce MNIST el yazısı tanıma deneyinde kullanılan CNN'ye benzer bir ortak CNN mimarisi kullandılar. Sistemin genel mimarisi şekilde gösterilmiştir.
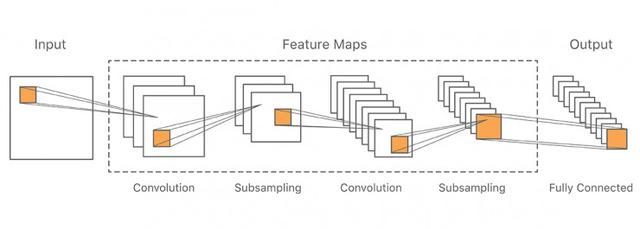
Sistem girişi, el yazısı Çince karakter içeren orta çözünürlüklü 48x48 bir resimdir (daha iyi performans için). Daha sonra, evrişimli katmanlar ve alt örnekleme katmanları dahil olmak üzere birkaç öznitelik çıkarma katmanına gönderilir. Son özellik çıkarma katmanı, tamamen bağlı bir katman aracılığıyla çıktıya bağlanır.
Her bir evrişimli katmanda, Apple araştırmacıları evrişim çekirdeği sayısını seçti ve giderek daha kaba olan taneciklikten mümkün olduğunca çok öznitelik çıkarabilen haritalar içeriyor. Maksimum havuzlama katmanı aracılığıyla 2x2 evrişim çekirdeği ve alt örnekleme kullanırlar. Son özellik katmanında bulunan küçük özellik haritasının büyüklüğü genellikle 1000 civarındadır. Son olarak, çıktı katmanındaki her sınıf için ayrı bir düğüm vardır GB2312-80'de seviye 1 Çince karakterler için 3755 düğüm vardır, bu tüm karakterlere genişletildiğinde 30.000'e yakındır.
Temel olarak, Apple araştırmacıları bu CNN modelini CASIA kıyaslama görevinde değerlendirdiler. Bu görev yalnızca Çince karakterlerde 1. seviye karakterleri kapsasa da, önceki literatürde çok sayıda tanıma testi doğruluğu sonuçları vardır. Eğitim seti ve test setine bölünmüş aynı CASIA-OLHWDB, DB1.0-1.2'yi kullandılar, eğitim numunelerinin sayısı yaklaşık 1 milyon.
Apple'ın araştırmalarının odak noktasının ürün odaklı olduğunu belirtmekte fayda var, bu nedenle amaçları CASIA'da mümkün olan en yüksek doğruluğu elde etmek değil, model boyutuna, akıl yürütme hızına ve kullanıcı deneyimine daha fazla odaklanmak. Bu nedenle, optimizasyon hedefleri, sonuçları gerçek zamanlı olarak hesaplayabilen kompakt bir sistemdir.Çeşitli farklı yazı stilleri ile baş edebilmesi ve standart olmayan vuruş dizilerine karşı sağlam olması gerekir. Bu şekilde, değerlendirmeye çevrimiçi veritabanı da eklenmiş olsa bile, yine de görüntü özelliklerine dayalı bir tanıma yöntemi seçmişlerdir. Ayrıca, gözlemlenen gerçek felç değişikliklerini ve görünüm değişikliklerini de hesaba kattılar.
Tablo 1, yukarıdaki Şekil 1'deki CNN modelinin test sonuçlarını gösterir; burada "Hz-1", seviye 1 Çince karakter kitaplığını (3755 karakter) ve "CR (n)", modelin ilk n tanıma sonucunu temsil eder. Doğru karakterlerle doğruluk. Yaygın olarak kullanılan doğruluk (n = 1) ve ilk 10 tanıma doğruluğuna (n = 10) ek olarak, tablo aynı zamanda en iyi 4 doğruluğu da (n = 4) ekler, çünkü Appleın kullanıcı arayüzü 4 aday karakter göstermektir.İlk 4 hanenin doğruluğu, kullanıcı deneyiminin önemli bir göstergesidir.
Tablo 1: CASIA çevrimiçi veritabanında 3755 Çince karakterin test sonuçları. Standart eğitim, ilişkili model boyutu 1MBÖnceki çalışmalarda, ilk tercihin doğruluk oranı% 93'e, ilk 10'un doğruluk oranı% 98'e ulaştı. Aksine, Apple'ın kendi ilk 10 doğruluk oranı diğer çalışmalarda olduğu gibi aynı seviyede olmasına rağmen, ilk doğruluk oranı biraz daha düşüktür. Apple'ın görüşüne göre, bu, ilk 4'ün daha yüksek bir doğruluğunu elde etmek için bir denge ve belki de daha da önemlisi, bu modelin (1MB) boyutu, daha önce benzer herhangi bir sistemden daha küçük.
Tablo 1'deki sistem, CASIA'daki verileri yalnızca eğitim için kullandı ve diğer eğitim verilerini kullanmadı. Apple'ın araştırmacıları, sistemi eğitmek için kendi iOS cihazlarında toplanan el yazısı verilerinin kullanılması durumunda ne gibi bir etkinin elde edileceğiyle de çok ilgileniyorlar. Bu verilerde kapsanan yazma stilleri daha çeşitlidir ve her karakterin daha fazla karşılık gelen eğitim örneği vardır. Aşağıdaki Tablo 2, aynı 3755 karakter kitaplığına karşılık gelen eğitim sonucudur.
Tablo 2: CASIA çevrimiçi veritabanında 3755 Çince karakterin test sonuçları. Geliştirilmiş eğitim, ilişkili model boyutu 15MBBu sistemin hacmi büyük ölçüde artmış olsa da (15MB'ye ulaşmıştır), doğruluk oranı sadece biraz artmıştır (ilk 4'ün kesinliğinin mutlak değeri% 2 artmıştır). Bu, test setindeki yazı stillerinin çoğunun CASIA eğitim setinde ele alındığını göstermektedir. Ancak bu aynı zamanda daha fazla eğitim verisi eklemenin bir zararı olmadığını da gösterir: yeni eklenen yazma stili modelin orijinal performansını olumsuz etkilemeyecektir.
30.000 karaktere genişletin
Daha önce de belirtildiği gibi, herkesin ideal "yaygın olarak yazılan karakterleri" farklıdır. Kullanıcı sayısı büyük olduğunda, gereken yazı tipi boyutu 3755'ten çok daha fazladır. Gerekli yazı tipi kitaplığını doğru bir şekilde seçmek o kadar basit ve anlaşılır değildir. GB2312-80'de tanımlanan basitleştirilmiş Çince karakterlerin ve Big5, Big5E ve CNS 11643-92'de tanımlanan geleneksel Çince karakterlerin kapsamı da farklıdır (3755'ten 48027'ye kadar Çince karakterler). Son zamanlarda, 4568 karakter eklenmiş HKSCS-2008 ve GB18030-2000'de daha da fazlası var.
Apple, kullanıcıların basitleştirilmiş veya geleneksel Çince, isimler veya şiirler ve yaygın olarak kullanılan diğer işaretler, görsel semboller ve emoji ifadeleri olsun, günlük dillerinde yazabilmelerini sağlamak istiyor. Ayrıca, kullanıcıların çeviri olmadan yazabilmelerini umuyorlar Ürün veya marka adlarında ara sıra görünen Latin karakterler. Apple, karakter kodlama standardı olarak uluslararası ana akım Unicode karakter setini takip eder, çünkü yukarıda bahsedilen neredeyse tüm karakter standartlarını kapsar (Unicode 7.0'ın BD genişlemesinde 70.000 karakteri ayırt edebildiğini belirtmekte fayda var ve hala düşünüyor. Daha ekle). Bu nedenle, Apple'ın karakter tanıma sistemi GB18030-2005, HKSCS-2008, Big5E'deki Çince karakterlerin yanı sıra temel ASCII karakter setine ve toplamda yaklaşık 30.000 karakter içeren bir dizi görsel sembol ve emoji ifadesine odaklanmayı seçti. Bu, çoğu Çinli kullanıcı için en iyi seçimdir.
Modelin iç karakter kitaplığını seçtikten sonra, bir sonraki kilit nokta, kullanıcının gerçekten kullandığı yazma stilini örneklemektir. Farklı yazı stilleri arasında onları ayırt etmeye yardımcı olabilecek bazı resmi kurallar olsa da, U + 2EBF () veya U + 56DB (dört) gibi bazı bölgesel yazma değişiklikleri de olacaktır. Karalanmış ve U + 306E () arasındaki benzerlik.

Ekranda görüntülenen karakterler de kafa karıştırıcı olabilir çünkü bazı kullanıcılar belirli karakterlerin belirli bir tarzda görüntülenmesini ister. Hızlı yazmak, stil karalamasını da yapacak ve bu da U + 738B () ve U + 4E94 (Beş) gibi karakterlerin belirsizliğini artıracaktır.

Son olarak, uluslararasılaşma derecesini artırmak bazen beklenmedik çatışmalara neden olabilir.Örneğin, U + 4E8C (iki), sürekli bir vuruşla yazıldığında, Latince "2" ve "Z" karakterleriyle çelişir.
Appleın tasarım yönergeleri, ister tipografik bir yazı tipi isterse de karalanmış, sınırlandırılmamış bir yazı gibi olsun, kullanıcılara tüm girdi olasılıklarını sağlamak içindir. Apple araştırmacıları, yazı tipi bozulmalarını olabildiğince fazla örtmek için Çin'in farklı bölgelerindeki yazarlardan veri topladı. Onları şaşırtan şey, çoğu kullanıcının daha önce hiç görmediği pek çok alışılmadık kelime olmasıydı. Yaygın olmayan kelimelere aşinalık nedeniyle, kullanıcılar yazarken tereddüt edebilir, yanlış vuruş sırasını yazabilir ve dikkate alınması gereken başka hatalara neden olabilir.
Apple'ın araştırmacıları veri yazmak ve toplamak için farklı yaşlardan, cinsiyetlerden ve eğitim seviyelerinden birçok sıradan Çinli insanı işe aldılar; nihayet elde edilen el yazısı veriler, diğer veritabanlarının sahip olmadığı birçok özelliğe sahipti: kaç binlerce kullanıcı dahil edildi İOS aygıtlarında (ekran kalemi değil) parmaklarla yazılmış birçok küçük veri yığını vardır. Diğer bir avantaj, iOS cihazlarının örneklemesinin çok net bir el yazısı oluşturmasıdır.
Apple araştırmacıları çok çeşitli yazma yöntemleri keşfettiler. Aşağıdaki şekil 2 ila 4, U + 82B1 (çiçekler) yazısının bir kısmını göstermektedir, bazıları baskıya yakın, bazıları karalanmış ve bazılarında büyük değişiklikler var.

Aslında, günlük hayatta kullanıcılar genellikle hızlı yazarlar ve çok değişir ve karalanmış ve çarpıtılmış el yazısı çok farklı görünür. U + 7684 (arasında) ve U + 4EE5 (için) gibi.


Öte yandan, bazen farklı kelimeler birbirine benzeyecek ve kafa karışıklığına neden olacaktır. Aşağıdaki U + 738 (Wang) ve U + 4E94 (Beş) verileri bariz örneklerdir. Karalanmış değişiklikleri ayırt edebilmek için yeterli eğitim verisine ihtiyaç duyulması gerektiğine dikkat etmek önemlidir.

Daha önce tartışılan tasarım yönergelerine göre Apple, eğitim verileri olarak el yazısıyla yazılmış on milyonlarca Çince karakter örneği topladı. Aşağıdaki Tablo 3'teki sonuçlar, tanınan karakter sayısı önceki 3755 karakterden yaklaşık 30.000'e çıkarıldıktan sonra elde edilmiştir. Hala önceki makaledeki CASIA çevrimiçi testinin aynısı.
Tablo 3: CASIA çevrimiçi veritabanında 30 bin karakterlik test sonuçlarıAynı model boyutu burada korunur. Yukarıdaki Tablo 2'deki sistem yalnızca seviye 1 Çince karakter aralığı ile sınırlıdır ve diğer her şey Tablo 3'teki sistem ile aynıdır. Doğruluk oranı biraz azalmıştır, bu da araştırmacıların beklentileri ile daha uyumludur, çünkü büyük ölçüde artan kapsam, daha önce bahsedilen "iki" ve "Z" gibi ek karışıklıklara neden olacaktır.
Tablo 1'in sonuçları Tablo 3 ile karşılaştırıldığında, karakter kapsamını 10 kat genişletmenin hata oranını 10 kat artırmadığı veya model büyüklüğünü 10 kat artırdığı görülmektedir. Aslında, daha büyük modeller için hata oranı çok daha yavaş yükselir. Bu nedenle, 30.000 karakteri kapsayan (yalnızca 3755 yerine) ve yüksek doğruluğa sahip bir Çince el yazısı karakter tanıma sistemi oluşturmak sadece mümkün değil, aynı zamanda uygulanabilir.
Apple araştırmacıları, sistemin 30.000 karakterin hepsinde nasıl performans gösterdiğini göstermek için, sistemi desteklenen tüm karakterleri içeren ve çeşitli yazı stillerini kullanan bir dizi farklı test setiyle de test etti. Tablo 4 sonuçların ortalamasıdır.
Tablo 4: Tüm yazma stilleri dahil olmak üzere 30.000 karakterlik bir test setinde birden fazla Apple dahili testinin ortalama sonuçlarıTabi ki Tablo 3 ve Tablo 4'ün sonuçları, farklı test setleriyle elde edildiği için doğrudan karşılaştırılamaz. Bununla birlikte, ilk doğruluk oranları ve ilk dört doğruluk oranları, tüm karakter kitaplığı için aynı seviyededir. Bu sonuç, daha dengeli bir eğitim modu ile elde edilir.
tartışmak
İdeografik Çalışma Grubu IRG, farklı kaynaklardan karakterler toplamaya ve yeni eklemeler önermeye devam ettikçe, yaklaşık 75.000 boyutundaki mevcut Unicode karakter seti, gelecekte artmaya devam edebilecek Çince, Japonca ve Korece ideografik karakterleri içerir. Açıkçası, yeni eklenen karakterler çok nadir karakterler olacaktır (tarihte veya şiirlerde yer alan isimler gibi). Bununla birlikte, isimlerinde bazı nadir kelimeler bulunan insanlar için bu görevler yine de anlamlıdır.
Peki, Apple gelecekte daha büyük bir karakter kitaplığıyla nasıl başa çıkmayı planlıyor? Bu makaledeki deney, farklı miktarlarda eğitim verisi altında eğitim ve test hata oranını gösterir. Bu şekilde, daha fazla eğitim verisi ve tanınacak daha fazla karakter olduğunda doğruluk performansını tahmin etmek için yaklaşık çıkarımlar yapılabilir.
Örneğin, Tablo 1'den Tablo 3'e, karakter kitaplığı ve modelle ilgili kaynakların boyutu için on kat artan doğruluk oranının yalnızca% 2 azaldığı (daha az) görülebilir. Öyleyse, 100.000 karakterlik bir karakter kitaplığı ve aynı miktarda artırılmış eğitim verisi için, yaklaşık% 84'lük ilk seçim doğruluk oranına ve% 97'lik ilk 10 doğruluk oranına (aynı ağ mimarisi için) ulaşmanın tamamen mümkün olduğunu tahmin etmek için neden var. ).
Özetle, 30.000'e kadar Çince karakteri kapsayan yüksek doğruluklu bir el yazısı tanıma sistemi oluşturmak, gömülü cihazlar için bile mümkün. Dahası, karakter kütüphanesinin boyutu arttıkça, yeterli miktarda yüksek kaliteli eğitim verisi olduğu sürece tanıma doğruluğu çok yavaş düşer. Bu, daha büyük bir karakter kitaplığına dayalı gelecekteki olası el yazısı tanıma için iyi bir haber.
Apple ML Journal, Lei Feng.com AI Technology Review Compilation aracılığıyla