Kapsül Ağına Dayalı Parmak Damar Tanıma Araştırması

Özet
Evrişimli sinir ağında (CNN) uzamsal parmak damarı bilgi kaybı problemini hedefleyen, Kapsül Ağı (Kapsül Ağı, Kapsül Ağı) tabanlı bir parmak damar tanıma algoritması önerilmiştir. Öğrenme süreci boyunca Capsnet'ler alt katmandan üst katmana "kapsül" şeklinde aktarılır.Bu sayede parmak damarlarının çok boyutlu özellikleri vektörler şeklinde kapsüllenir, özellikler kaybedildikten sonra restore edilmek yerine ağda saklanır. Eğitim seti olarak 60.000 görüntü ve test seti olarak 10.000 görüntü kullanılarak, ağ öğrenimi, görüntü iyileştirme ve kırpmadan sonra gerçekleştirilir. Deneyler, CapsNets'in ağ yapısı özelliklerinin, sırt bölgesinin işlenmesinde CNN'den daha etkili olduğunu, karşılaştırma VGG'sinin doğruluğunun% 13.6 arttığını ve kayıp değerinin de 0.01'e yakınsadığını göstermektedir.
Dar ev dekorasyonu: iç dekorasyona atıfta bulunur; iç mekanı daha güzel hale getirmek için güzelleştirme perspektifinden düşünülür;
Geniş anlamda ev geliştirme: İç mekanların tadilatı ve dekorasyonu dahil; bugün geniş anlamda, iç dekorasyon ve dekorasyonun birleşimi olan ev geliştirme hakkında konuşuyoruz.
Çince alıntı biçimi: Yu Chengbo, Xiong Dien.Kapsül Ağına Dayalı Parmak Damar Tanıma Araştırması. Elektronik Teknoloji Uygulaması, 2018, 44 (10): 15-18.
İngilizce alıntı biçimi: Yu Chengbo, Xiong Dien.Kapsül ağına dayalı parmak damarı tanıma üzerine araştırma.Elektronik Tekniğin Uygulanması, 2018, 44 (10): 15-18.
0 Önsöz
Son yıllarda, makine öğreniminin geliştirilmesinde, derin öğrenme algoritmaları da sürekli geliştirildi ve güncellendi. AlexNet'in 2012'de doğumundan 2017'de VGG, GoogleNet, ResNet ve diğer ağların optimize edilmiş ve geliştirilmiş sürümlerinin ortaya çıkmasına kadar, derin öğrenme algoritmalarının ImagNet Görüntü Sınıflandırma Zorluğu'ndaki diğer sınıflandırma algoritmalarından çok daha iyi performans göstermesini sağladı. Evrişimli sinir ağı (CNN), evrişim yoluyla özellikleri çıkarır, alttan üst seviyeye doğru eşler, karmaşık işlevlerin yaklaştırılmasını gerçekleştirir ve akıllı öğrenme yeteneğini gösterir. Literatür, parmak damar görüntülerini eğitmek, 3 × 3 evrişim çekirdeğini 1 × 1 olarak değiştirmek ve özellik haritalarının sayısını azaltmak için geliştirilmiş bir AlexNet ağının kullanılmasını önermektedir. 50.000 döngüden sonra, tanıma oranı% 99.1'e ulaşmaktadır. Literatür, parmak damar görüntülerini eğitmek için VGG ağını kullanır ve düşük kaliteli, orta kaliteli ve yüksek kaliteli görüntülerin eğitim sonuçlarını 16 katmanlı VGG ağı ve 19 katmanlı VGG ağı ile karşılaştırır. 16 katmanlı VGG ağının yanlış tanıma oranı en düşük 0,396 (yüksek kaliteli görüntü ).
Standart yüksek kaliteli görüntü eğitimi sayesinde, CNN parmak damar tanıma için uygundur, ancak bazı pratik sorunlar da vardır. Toplayıcı tarafından toplanan görüntünün sığ parmak damar görüntüsünü toplama olasılığı çok yüksektir.Aynı zamanda görüntü işleme iki boyutlu bir matrise dayanmaktadır.CNN, global parmak damar görüntüsünün özelliklerini öğrenmede çok etkili değildir. Epidermisin arkasındaki damarlar öğrenilmeyecek, bu nedenle tanıma doğruluğu ciddi şekilde etkilenecektir.
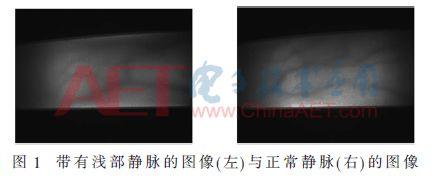
Şekil 1'de görüldüğü gibi yüzeysel damar görüntüsünün özellikleri lokal damarların daha ince, daha açık renkli, düzensiz dağılmış ve eksik olmasıdır.Bunun ana nedeni damarın görece geride olması ve kızılötesi kameranın dokudan net bir şekilde geçememesidir. Ateş etmek. Bununla birlikte, normal görüntülerdeki damarların kalınlığı ve rengi eşit olarak dağılmıştır.
Aralık 2017'de HINTON GE, CapsNets'in ağ yapısını önerdi ve multiMINIST ile ilgili eğitimin doğruluğu% 99.23 idi ve bu, afinist test setinde% 79 doğruluk elde ederek CNN'nin% 66'sını aştı.Aynı zamanda, CapsNets zaman alıcıydı. Şu anda en doğru ağdır. Parmak damar görüntülerinde genellikle damar örtüşmeleri olur ve bu da genellikle edinim işlemi sırasında üst üste gelen damar görüntüsüyle sonuçlanır. CNN uzamsal konum üzerinde zayıf bir öğrenme etkisine sahiptir, bu nedenle görüntüleri toplarken, aynı parmak birden çok kez toplanacaktır, böylece ağ özellik haritasındaki her damarı olabildiğince öğrenebilirken, CapsNets uzamsal konumdaki damar görüntülerinin işlenmesini çok aşabilir. CNN'de tüm öğrenme süreci, alt katmandan yüksek katmana, çok boyutlu özellikleri kapsayan bir "kapsül" şeklinde aktarılır, bu da damar özelliklerini daha az olasılıkla korurken eğitim örnek sayısını azaltabilir. Bu nedenle, bu makale CapsNets'in parmak damar tanıma yöntemlerine uygulanmasını önermektedir.
1 CapsNets
1.1 Ağ yapısı
Bazı büyük bilgisayarla görme görevleri farklı bir CNN mimarisi gerektirir. CNN görüntü sınıflandırmasının etkisi araştırmacılar tarafından kabul edilmiştir, ancak aşağıdaki sorunlar vardır:
(1) CNN'in çok sayıda görüntü üzerinde eğitilmesi gerekir, bu da eğitim örneklerini almanın çok zaman almasına neden olur, ancak CapsNets eğitim için daha az eğitim verisi kullanabilir.
(2) CNN belirsizliği iyi idare edemez. CapsNets, yoğun sahnelerde bile iyi performans gösterebilir.
(3) CNN, havuz katmanında çok fazla bilgi kaybeder. Havuzlama katmanının maksimum değeri, oluşma olasılığı daha düşük olan özellikleri atarken, oluşma olasılığı daha yüksek olan özellikleri korur.Genellikle bu önemli bilgilere ihtiyacımız vardır.Bu katmanlar uzamsal çözünürlüğü azaltır, bu nedenle çıktıları girdiyle karşılaştırılamaz. Küçük değişikliklere yanıt verin. Ağ boyunca ayrıntılı bilgilerin depolanması gerektiğinde bu bir sorundur. Günümüzde bu sorunun çözümü, CNN etrafında karmaşık bir mimari oluşturarak kayıp bilgilerin bir kısmını kurtarmaktır. CapsNets'in ayrıntılı öznitelik bilgileri, kaybedildikten sonra geri yüklenmek yerine ağ genelinde saklanır. Girişteki küçük bir değişiklik, çıktıda küçük bir değişikliğe yol açar ve bilgi korunur, buna eşdeğerlik denir. Bu nedenle CapsNets, farklı görüntü görevlerinde aynı basit ve tutarlı mimariyi kullanabilir.
(4) CNN, bir bileşenin hangi nesneye ait olduğunu otomatik olarak belirlemek için ek bileşenlere ihtiyaç duyar. CapsNets, bunun için bir bileşen hiyerarşisi sağlayabilir.
CapsNet çok sığ bir ağın yanı sıra toplam 3 kat evrişimli katman ve tamamen bağlantılı katmandır. CNN, düşük seviyeli özelliklerin ayıklanmasında çok iyi performans gösterir. Aksine, CapsNets bir nesnenin "örneklerini" karakterize etmek için kullanılır, bu nedenle yüksek seviyeli örnekleri karakterize etmek için daha uygundur. Bu nedenle, geleneksel CNN'nin evrişimli katmanı, alt katman özelliği çıkarımı için CapsNets'in alt katmanına eklenir.
Şekil 2'de gösterildiği gibi, düşük seviyeli özelliklerden Birincil Kapsüle, ikinci evrişimli katmanın boyutu 6 × 6 × 8 × 32 olup, adım boyutu 2 olan 329 × 9 × 256 filtre ile hacmin 8 katı yapılır. Ürün operasyonu 6 × 6 × 1 × 32 boyutlarında CNN katmanında 6 × 6 × 32 elementler vardır ve her element skalerdir.Kapsülde boyutta 6 × 6 × 8 × 32 katman vardır. 6 × 6 × 32 eleman, her eleman, esas olarak düşük seviyeli öznitelik vektörlerini depolayan bir 1 × 8 vektördür.
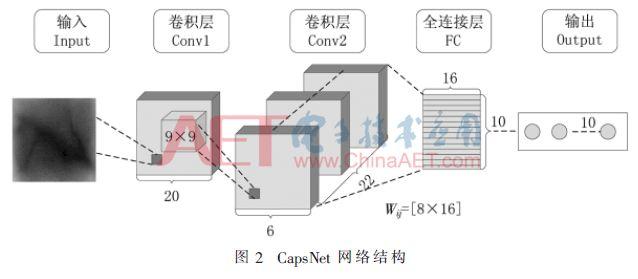
Primary Capsule'den Digit Capsule'e, PrimaryCaps ve DigitCaps tamamen bağlıdır, ancak geleneksel CNN skaler ve skaler gibi değildir. Bu tam bağlantılı katman, bir vektöre bağlı bir vektördür. Dinamik yönlendirme algoritması, cij ve çıktı 584 vj'yi hesaplamak için 3 kez yinelenir.
Rakam Kapsülü son çıktıya kadar, uzunluğu karakterizasyon içeriğinin olasılığını temsil eder, bu nedenle sınıflandırma yaparken çıkış vektörünün L2 normunu alın. CapsNets, önceki sinir ağı çıktısı olasılık toplamı 1 gibi değildir, çünkü CapsNets aynı anda birden fazla nesneyi tanıma yeteneğine sahiptir.
1.2 Kapsül
Orijinal sinir ağı, yerel bir havuzdaki tekrarlanan özellik algılayıcısının aktivitesini özetlemek için tek bir skaler çıktının kullanımına dayanıyordu.CNN, tek bir görüntü üzerinde yer değiştirme ve döndürme gerçekleştirecek ve bunu iki görüntü olarak ele alacaktı. Bununla birlikte, sinir ağı çok boyutlu özellikler biçimini, yani "kapsüller" kullanmalıdır.Bu kapsüller, girdileri üzerinde çok karmaşık bazı dahili hesaplamalar yapar ve daha sonra bu hesaplamaların sonuçlarını, bilgi bakımından zengin çıktılar içeren bir vektör halinde kapsüllemektedir. Her kapsül, yerel bir koşul ve etkili deformasyon aralığı içinde dolaylı olarak tanımlanan bir görsel varlığı tanımlamayı öğrenecek ve sınırlı bir aralıkta ve bir dizi varlık parametresinde var olma olasılığını çıkaracaktır.Bu varlık parametreleri seti, görsel varlığa göre aydınlatma koşullarını içerecektir, Doğru duruş ve deformasyon bilgileri vb. Kapsül normal çalıştığı zaman, görsel varlığın var olma olasılığı yerel olarak değişmez, yani varlık, kapsülün kapsadığı sınırlı aralık dahilinde görünüm manifoldu üzerinde hareket ettiğinde, olasılık değişmeyecektir. Varlık parametreleri "eşit değişken" dir. Gözlem koşulları değiştikçe, örnek parametreleri, Şekil 3'te gösterildiği gibi görünüm manifoldundaki varlığın dahili koordinatlarını temsil ettiğinden, varlık görünüm manifoldunda hareket ettiğinde buna göre değişecektir. Gösterildi.
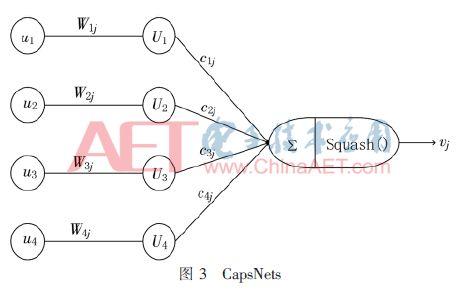
Görüntüdeki parmak damar özelliklerini algılayan ve sabit uzunlukta üç boyutlu bir vektör veren bir kapsül varsayalım. Ardından görüntüdeki damarları hareket ettirmeye başlayın. Aynı zamanda, vektör uzayda dönerek tespit edilen damarın durumunun değiştiğini gösterir, ancak uzunluğu sabit kalacaktır çünkü kapsül damarı tespit ettiğinden hala emin. Nesne görüntüde hareket ettikçe sinirsel aktivite değişecektir, ancak algılama olasılığı sabit kalır Bu, CNN tarafından sağlanan maksimum havuzlamaya dayalı değişmezlik değil, CapsNets tarafından takip edilen değişmezliktir.

1.3 Squash işlevi
CNN'nin yaygın olarak kullanılan aktivasyon fonksiyonları arasında doğrusal süperpozisyondan sonra 0 ~ 1 veya 1 ~ -1 arasında sıkıştırılan ReLU, sigmoid vb. CapsNets'te, ön katman ağında bir vektör şeklinde iletildiğinden, "kapsül" etkinleştirildiğinde yönlendirilmesi gerekir. CapsNets'in etkinleştirme işlevi Squash olarak adlandırılır ve ifade formül (2) 'de gösterilir:

1.4 Dinamik yönlendirme
Kapsülün giriş ve çıkışının iç çarpımı, giriş ve çıkışın benzerliğini ölçer ve ardından yönlendirme katsayısını günceller. Pratikte en iyi yineleme sayısı 3'tür. Dinamik yönlendirmenin adımları şunlardır:
(1) Giriş resmini kapsülleyin ve Uj | i çıktısını, yönlendirme yinelemelerinin sayısı r;
(2) bij'i, katman 1 VNi'yi bir sonraki katman VNj'ye bağlama olasılığı olarak tanımlayın, başlangıç değeri 0'dır;
(3) Bir döngüde (4) - (7) adımlarını r kez yürütün;
(4) VNi'nin l katmanı için, bij'i olasılık cij'ye dönüştürmek için Softmax'ı kullanın;
(5) l + 1 tabakasının VNj'si için ağırlıklı toplam sj;
(6) l + 1 katmanının VNj'si için, vj'yi elde etmek üzere sj'yi etkinleştirmek için etkinleştirme işlevini kullanın;
(7) bij'i Uj | i ve vj arasındaki ilişkiye göre güncelleyin.
Bij'i güncellemek için Uj | i ve vj'nin iç çarpımını kullanın. İkisi benzer olduğunda, iç çarpım daha büyük olur ve bij de daha büyük olur. Düşük seviyeli VNi'yi yüksek seviyeli VNj'ye bağlama olasılığı artar; tersine, ikisi arasındaki fark büyük olduğunda , Nokta çarpım küçüktür, bij de küçüktür ve düşük seviyeli VNi'nin yüksek seviyeli VNj'ye bağlanma olasılığı azalır.
1.5 Kayıp işlevi
CapsNets'in kayıp fonksiyonu, formül (3) 'te gösterildiği gibi, SVM'nin kayıp fonksiyonuna benzer;
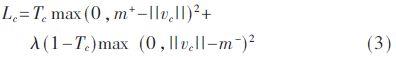
Denklem (3) ayrıca pozitif ve negatif numuneler ile hiper düzleme arasındaki mesafeyi maksimize etmeyi ifade eder. Burada iki kalibrasyon noktası m + = 0.9 ve m- = 0.1 verilmiştir.Kayıp, pozitif örnek m + 'nın 0.9 olacağı öngörülmektedir ve 0.9'u aşarsa iyileştirmeye devam etmesine gerek yoktur; negatif m-tahmini 0.1'dir ve düşürmeye gerek yoktur. Tekrar düşmeye devam etmelidir. İlk kaybın çok büyük olmasını önlemek için eğitim sırasında sayısal kararlılık için kullanılan ve tüm çıktı değerlerinin küçülmesine neden olan değeri 0,5 olarak sabitlenmiştir. Formüldeki her iki terim de karelere sahiptir, çünkü bu kayıp fonksiyonunun bir L2 normu vardır ve toplam kayıp, tüm kayıp türlerinin toplamıdır.
2 deney
2.1 Veri seti
Bu deneyde kullanılan veri seti, 584 bireyin 6 parmağının (başparmak ve küçük parmak hariç) görselidir ve her bir parmak tekrar tekrar 20 kez toplanmaktadır, yani veri setinin boyutu 584 × 6 × 20'dir. Bunlar arasında eğitim seti 60.000 ve test seti 10.000'dir.
2.2 Deneysel sonuçlar
TensorFlow açık kaynak çerçevesini kullanarak derin sinir ağları tasarlayın ve uygulayın. 3 yönlendirme döngüsü ve 31.000 eğitim yinelemesi gerçekleştirin. Tanıma oranı ve kayıp değeri Tablo 1'de gösterilmektedir.
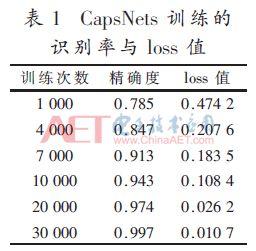
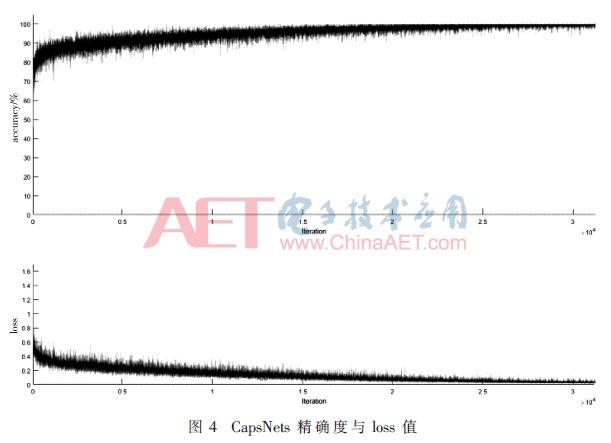
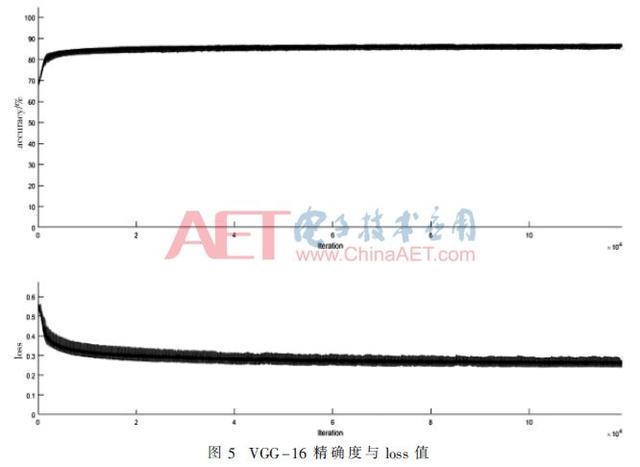
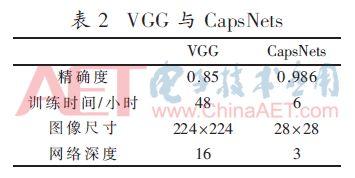
Tüm deney NVIDIA Titanxp üzerindedir. CapsNet ağı eğitim süresi yaklaşık 6 saat sürer.Şekil 4'ten apsisin CapsNets'in yineleme sayısı ve ordinatın CapsNet'lerin doğruluk ve kayıp değeri olduğu görülebilir. Yineleme 2.000 katına ulaştığında ,% 90'lık doğruluğa yaklaşmaya başladı ve kayıp 0.2'ye kadar düştü. Yinelemelerin sayısı arttıkça, titreşim yavaş yavaş azalır ve kararlı hale gelir ve sonunda% 98.6'ya yaklaşır ve kayıp değeri de şaşırtıcı bir şekilde 0.0107'ye yaklaşır. Şekil 5, VGG-16'nın eğitim diyagramıdır.Görece kararlı olduğu ve sonraki öğrenmenin doğruluğu pek geliştirmediği görülmektedir.İterasyon 200 katına ulaştığında ağın doğruluğu% 84'e yaklaşır ve nihai doğruluk% 85'tir. Değer yavaş yavaş azalır ve nihai toplam kayıp değeri 0.21'dir. Tablo 2'de gösterildiği gibi, CapsNets, VGG-16'ya kıyasla bariz avantajlara sahiptir (aynı veri seti deneyini kullanarak).
3 Sonuç
Deneyler, parmak damar tanıma için CapsNets'in CNN'den daha iyi olduğunu doğruladı.Ağ yapısının basitliği nedeniyle, eğitim hızı büyük ölçüde iyileştirildi. Aynı zamanda CapsNets'in uzamsal özelliklerinden dolayı damar özellikleri daha tam olarak çıkarılır, bu da tanıma doğruluğunu artırır. Bununla birlikte, CapsNet'ler genellikle arka planla doludur. CapsNets henüz emekleme aşamasındadır.Gelecekteki çalışmalarda, büyük veri kümeleri ortaya çıktığında başka sorunlar ortaya çıkabilir.Ancak, CapsNets'in ortaya çıkışı, yapay zeka araştırmalarında ilerlememizi sağlar. Büyük bir adım.
Referanslar
KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet sınıflandırması derin evrişimli.Uluslararası Sinirsel Bilgi İşlem Sistemleri Konferansı, 2012, 60 (2): 1097-1105.
SIMONYAN K, ZISSERMAN A. Büyük ölçekli görüntü tanıma için çok derin evrişimli ağlar Bilgisayar Bilimi, arXiv: 1409.1556, 2014.
SZEGEDY C, LIU W, JIA Y, ve diğerleri. Evrişimlerle daha derine inmek. Bilgisayarla Görü ve Örüntü Tanıma IEEE Konferansı, 2015: 1-9.
He Kaiming, Zhang Xiangyu, Ren Shaoqing, ve diğerleri. Görüntü tanıma için derin artık öğrenme. IEEE Bilgisayar Topluluğu, 2015.
Wu Chao, Shao Xi. Derin Öğrenmeye Dayalı Parmak Damar Tanıma Araştırması Bilgisayar Teknolojisi ve Geliştirilmesi, 2018 (2): 200-204.
HONG H G, LEE M B, PARK K. NIR görüntü sensörlerini kullanarak evrişimli sinir ağı tabanlı parmak damar tanıma.Sensörler, 2017, 17 (6): 1-21.
Yu Chengbo, Qin Huafeng Parmak Damar Görüntü Özelliği Ekstraksiyon Algoritması Araştırması Bilgisayar Mühendisliği ve Uygulamaları, 2008, 44 (24): 175-177.
GONZALEZ R C, WOODZ R E. Dijital Görüntü İşleme Ruan Qiuqi, ve diğerleri, tercüme edildi. Beijing: Electronic Industry Press, 2007.
Wen Yandong, Zhang Kaipeng, Li Zhifeng, ve diğerleri.Derin yüz tanıma için ayırt edici bir özellik öğrenme yaklaşımı. Bilgisayar Bilimi Ders Notları, Springer, 2016, 47 (9): 499-515.
HINTON GE, KRIZHEVSKY A, WANG S D.Otomatik kodlayıcıları dönüştürmek.Uluslararası Yapay Sinir Ağları Konferansı, 2011, 6791: 44-51.
SABOUR S, FROSST N, HINTON G E.Kapsüller arasında dinamik yönlendirme. NIPS2017, 2017.
Liu Yang, Guo Shuxu, Zhang Fengchun, ve diğerleri Seyrek ayrışmaya dayalı parmak damar görüntüsü denoising.Sinyal işleme, 2012, 28 (2): 179-185.
ROSDI B A, CHAI W S, SUANDI S A. Yerel çizgi ikili paterni kullanarak parmak damar tanıma. Sensörler, 2011, 11 (12): 11357-71.
AREL I, ROSE D C, KARNOWSKI T P. Derin makine öğrenimi - yapay zeka araştırmalarında yeni bir sınır Hesaplamalı Zeka Dergisi IEEE, 2010, 5 (4): 13-18.
yazar bilgileri:
Yu Chengbo, Xiong Dien
(Elektrik ve Elektronik Mühendisliği Okulu, Chongqing Teknoloji Üniversitesi, Chongqing 400050)

