"ICML Eğitimi" Derin Güçlendirmeli Öğrenme, Karar ve Kontrol (117 PPT)

200.000, bu, bugün Xinzhiyuan'ın ulaştığı toplam kullanıcı sayısı. Akıllı evrene yolculuk sırasında, Xinzhiyuan ile seyahat eden her arkadaşınıza teşekkür edin. Dikkatiniz ve desteğiniz "Xinzhiyuan" yıldız gemisinin tükenmez yakıtıdır.
Tam PPT indirme: https://sites.google.com/view/icml17deeprl

"Büyülü" bir sinir ağı modelini basit ve ölçeklenebilir bir eğitim algoritmasıyla birleştiren derin öğrenme, bilgisayarla görme, konuşma tanıma ve doğal dil işleme gibi bir dizi denetimli öğrenme alanında büyük bir etkiye sahip olmuştur. Derin ağların karmaşık, yüksek boyutlu işlevleri yakalama ve esnek dağıtılmış gösterimleri öğrenme yeteneği, bu başarıyı mümkün kılar. Bu yetenek, gerçek dünyadaki karar verme ve kontrol problemleri üzerinde bir etkiye sahip olabilir.Makineler yalnızca karmaşık duyusal kalıpları sınıflandırmakla kalmaz, aynı zamanda eylemleri seçebilir ve uzun vadeli etkilerini açıklayabilir.
Karar verme ve kontrol sorunları, daha klasik derin öğrenme uygulamalarında ilgili denetimden yoksundur ve çözülmesi için yeni algoritma geliştirmeyi gerektiren bazı zorluklar getirir. Bu eğitici yazıda, pekiştirmeli öğrenmeyle ilgili temel pekiştirme ve optimal kontrol teorilerini tanıtacağız ve model tabanlı algoritmalar, taklit öğrenme ve ters pekiştirmeli öğrenme dahil olmak üzere derin öğrenmeyi karar verme ve kontrole genişletmedeki en son başarılardan bazılarını tartışacağız. Mevcut derin güçlendirme öğrenme algoritmalarının sınırlarını ve sınırlamalarını keşfedin.
Derin takviyeli öğrenme, karar verme ve kontrol

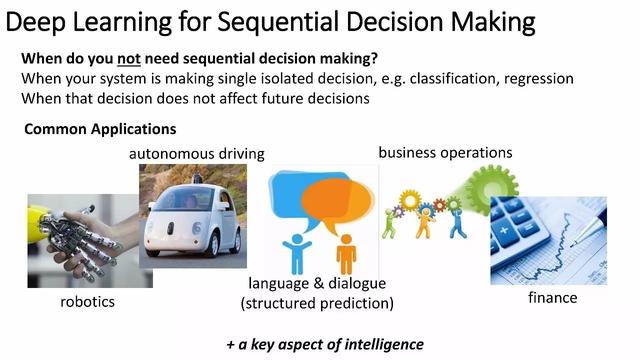
Sıralı karar verme için derin öğrenme
Sıralı karar ne zaman gerekli değildir?
-
Sisteminiz, örneğin sınıflandırma, regresyon gibi bireysel kararlar verirken
-
Bu karar gelecekteki kararları etkilemediğinde
Genel uygulama
Robotlar, otonom sürüş, dil diyaloğu (yapılandırılmış tahmin), iş operasyonları, finans
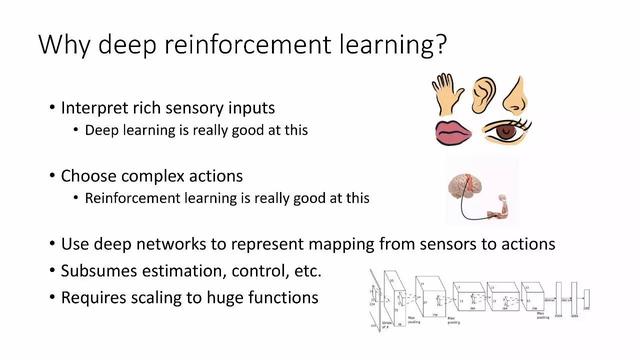
Neden derin pekiştirmeli öğrenmeyi seçmelisiniz?
-
Derin öğrenme, zengin duyusal girdiyi açıklamak için harikadır
-
Pekiştirmeli öğrenme, karmaşık eylemleri seçmek için iyidir
-
Duyuların ve eylemlerin eşlemesini temsil etmek için derin ağları kullanın
-
Tahmin, kontrol vb. Dahil
-
Büyük işlevlere genişletilmesi gerekiyor
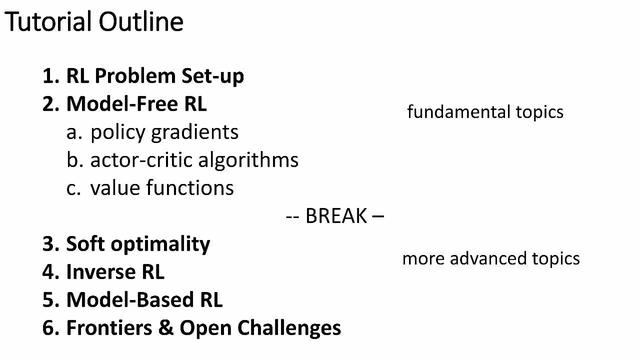
Bu öğreticinin yapısı:
Pekiştirmeli öğrenme için problem belirleme
Model içermeyen pekiştirmeli öğrenme
Strateji gradyanı
aktör-eleştirmen algoritması
Değer işlevi
3. Yumuşak optimallik
4. Ters RL
5. Model tabanlı RL
6. Sınır ve açık zorluklar
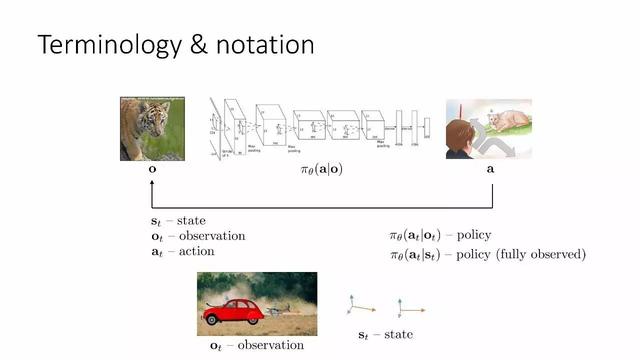
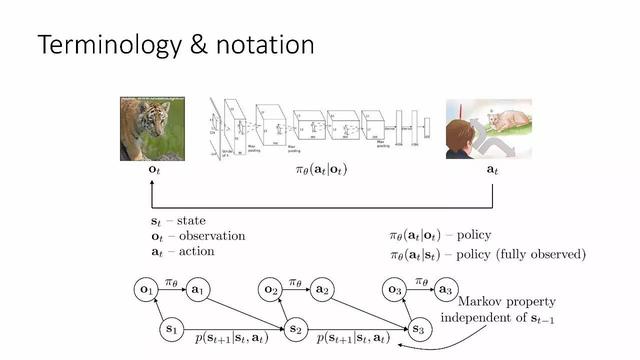
Terimler ve semboller
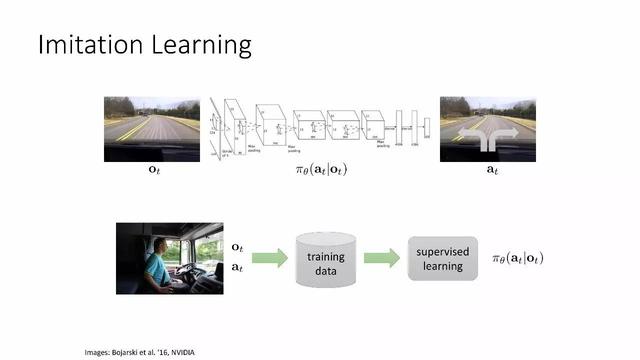
Taklit öğrenme

Ödül işlevi


Pekiştirmeli öğrenmenin amacı
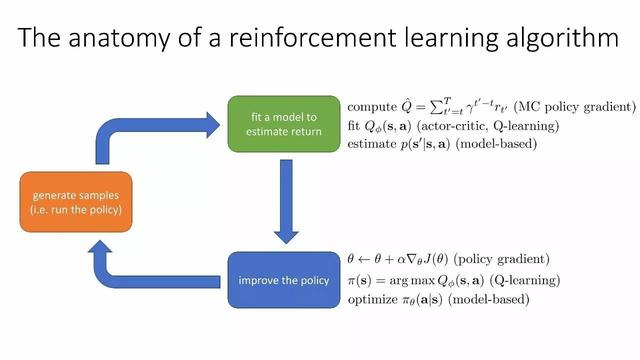
Takviye öğrenme algoritması anatomisi
Örnekler oluşturun (yani stratejileri çalıştırın) getirileri tahmin etmek için bir model oluşturun politikaları iyileştirin


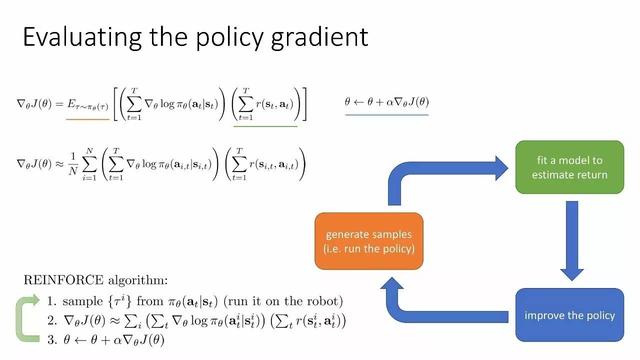


Değerlendirme stratejisi gradyanı

Politika gradyanıyla ilgili sorunlar
(Üst) Yüksek varyans
(Alt) Yavaş yakınsama, öğrenme oranını seçmek zor

Varyansı azaltın

Temel
Ortalama ödül en iyi temel değil ama oldukça iyi.

Kontrol değişkeni

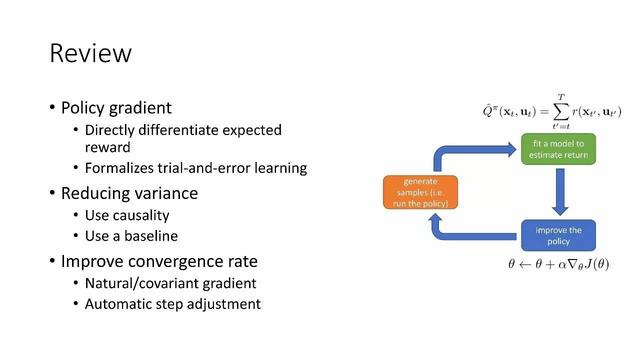
gözden geçirmek
Strateji gradyanı:
Doğrudan türev beklenen ödül
riyal-hata öğrenme
Varyansı azaltın
Nedensellik kullanın
Temel kullanın
Yakınsama oranının doğal / ortak değişken gradyanını iyileştirin
Otomatik kademe ayarı
Değişken / doğal strateji gradyanı

Strateji gradyanı örneği: TRPO
-
Doğal gradyan
-
Otomatik kademe ayarı
-
Ayrık eylem ve sürekli eylem
-
kullanıcı dostu
-
Kodlanabilir

