Özet Fudan Üniversitesi'nden Chen Junkun: Doğal Dil İşlemede Çok Görevli Öğrenme AI Araştırma Topluluğu Mesleki Yayın Odası No. 6

AI Technology Review Editörün Notu : Son birkaç yılda, derin öğrenme, doğal dil işlemede büyük ilerleme kaydetti, ancak ilerlemenin kapsamı bilgisayarla görmedeki kadar önemli değil. Önemli nedenlerden biri veri ölçeği sorunudur. Çok görevli öğrenme, birden çok görevi birlikte öğrenmek ve her bir görevin modelinin doğruluğunu artırmak için birden çok görev arasındaki ilişkiyi tam olarak keşfetmektir, böylece her görev için eğitim verisi talebini azaltır.
Geçtiğimiz günlerde, Leifeng.com AI Araştırma Enstitüsü'nün açık sınıfında, Fudan Üniversitesi Bilgisayar Bilimleri Bölümü'nde yüksek lisans öğrencisi olan Chen Junkun, araştırma grubunun doğal dil işleme alanındaki çok görevli öğrenme konusundaki son çalışmalarını paylaştı. Herkese açık sınıfın yeniden oynatma videosu makalenin sonunda tıklanabilir. Orijinali okuyun İzlemek
Konuk paylaşma:
Chen Junkun, Fudan Üniversitesi Bilgisayar Bilimleri Bölümü'nde yüksek lisans öğrencisidir. Danışmanı Doçent Qiu Xipeng'dir. Ana araştırma yönü doğal dil işleme, çok görevli öğrenme vb. Araştırma çalışması AAAI, IJCAI'de yayınlandı.
Konuyu paylaş: Doğal dil işlemede çok görevli öğrenme ve Fudan Üniversitesi NLP laboratuvarına giriş
Ana hatları paylaşın:
1. Fudan Üniversitesi NLP Laboratuvarına Giriş
2. Derin öğrenmeye dayalı doğal dil işleme
3. Doğal dil işlemede derin öğrenmenin ikilemi
4. Doğal dilde çok görevli öğrenme
5. Çoklu görev kıyaslama platformu
Leifeng.com AI Araştırma Enstitüsü paylaşım içeriğini şu şekilde düzenler:
Bu paylaşımın iki ana amacı vardır: Birincisi, Fudan Üniversitesi'nin NLP laboratuvarının ilgili çalışmalarını tanıtmak; diğeri ise, lisansüstü öğrenciler için eğitim almaya istekli öğrencilerin yerel laboratuvarları daha iyi anlamalarını sağlamak, böylece yüksek lisans öğrencilerini seçmede daha fazla hedefe sahip olabilmelerini sağlamak. Seks.
Fudan Üniversitesi NLP Laboratuvarına Giriş
Paylaşmadan önce kendimi tanıtalım. Şu anda Fudan Üniversitesi NLP Laboratuvarı'nda Doçent Qiu Xipeng'in vesayeti altında yüksek lisans okulunun üçüncü yılında okuyorum ve şimdi de ByteDance AI Lab'da stajyerim. Ana araştırma yönergeleri doğal dil işleme, çok görevli öğrenme ve geçiş. Öğrenin. Bugünkü paylaşım, çok görevli öğrenmeye odaklanacağım.
Ayrıca Fudan Üniversitesi'nin NLP laboratuvarını tanıtın.İnsan dilini anlamak ve işlemek için makine teknolojisini kullanmaya kendini adamıştır.Önde gelen yerli bir ekibe sahiptir ve laboratuvardaki öğretmenler çok zengin deneyime sahiptir. Araştırma grubum, dil temsili öğrenimi, sözcüksel / sözdizimsel analiz, metin muhakemesi, soru yanıtlama sistemleri vb. Dahil olmak üzere derin öğrenme ve doğal dil işleme üzerine odaklanmaktadır. Eğitmen Doçent Qiu Xipeng'dir. Son yıllarda, en iyi uluslararası konferansları yayınladık / 50'den fazla dergi ve ayrıca ACL 2017 seçkin makalesini kazandı; SQUAD 2.0'da ikinci oldu ve SQUAD 1.1'de birkaç kez birinci oldu; ayrıca, halkın sorunu çözmesine yardımcı olmayı umarak açık kaynaklı bir doğal dil işleme sistemi geliştiriyoruz FudanNLP (Çin'deki en eski açık kaynaklı NLP sistemlerinden biri), fastNLP (modüler, otomatik ve ölçeklenebilir bir NLP sistemi) dahil olmak üzere birçok sorun.
Bu doğal dil işleme raporunun ana hatları şunları içerir:
-
Doğal Dil İşlemeye Giriş
-
Derin öğrenmeye dayalı doğal dil işleme
-
Doğal Dil İşlemede Derin Öğrenmenin İkilemi
-
Doğal dil işlemede çok görevli öğrenme
-
Yeni çoklu görev kıyaslama platformu
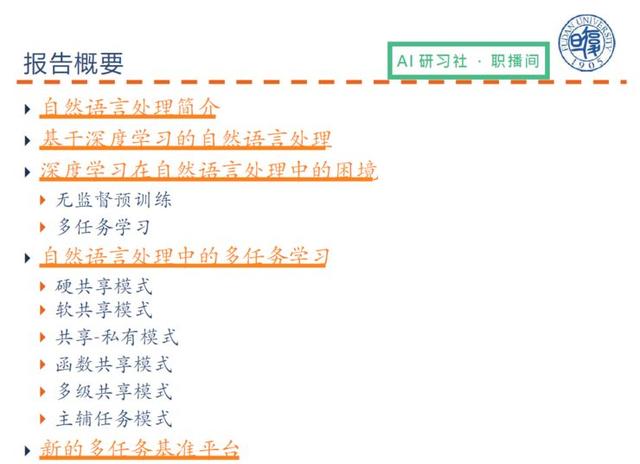
Doğal Dil İşlemeye Giriş
İlk olarak, kısaca doğal dil dil işleme kavramını tanıtın.
Turing testinin, bir kişi bir makineyle konuştuğunda diğer tarafın makine mi yoksa insan mı olduğunu söyleyemeyeceği ve makinenin Turing testini geçtiği anlamına geldiğini biliyoruz. Bu, doğal dil işlemenin özüne götürür: makinenin doğal dili anlamasına ve üretmesine izin verin.
Peki doğal dil işleme nedir? Kabaca, programlama dilleri gibi yapay dillerden farklı olan insan dili olarak anlayabiliriz. Doğal dil işleme görevleri arasında konuşma tanıma, doğal dil anlama, doğal dil üretimi, insan-bilgisayar etkileşimi ve ilgili ara aşamalar bulunur. Şu anda, yapay zeka ve bilgisayar biliminin çapraz konusu olarak sınıflandırılabilir.
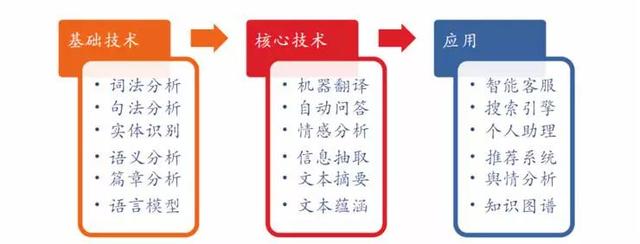
Teknik açıdan, üç seviyeye ayrılabilir: temel teknoloji, çekirdek teknoloji ve uygulama:
Doğal dil işlemenin zorluğu belirsizlikte yatmaktadır. Örnek olarak Çince kelime segmentasyonunu aşağıdakileri göstermek için kullanacağım:
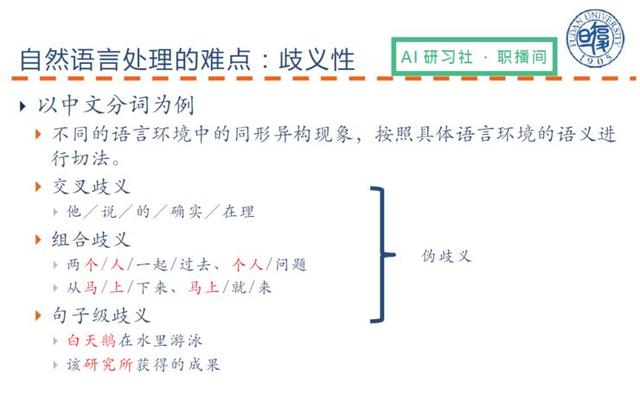
(Doğal dil işlemenin zorluklarının ayrıntılı açıklaması için lütfen videoyu 00:05:35 'de izleyin)
Doğal dil işlemenin gelişim tarihi şu şekilde özetlenebilir: 1990'dan önce, doğal dil işleme için birçok kurala dayalı yöntem kullanıldı; 1990'lardan sonra, bazı istatistiksel öğrenme yöntemleri aşamalı olarak tanıtıldı; şu anda, 2012'den beri derin öğrenme Çılgınlık, derin öğrenme sinir ağlarının uçtan uca eğitimine dayanan doğal dil işlemeyi gerçekleştirmeye başladı. Kısacası, doğal dil işleme, dili anlama (metinden makineye), üretme (makineden metne) ve ardından etkileşimde bulunma sürecidir.
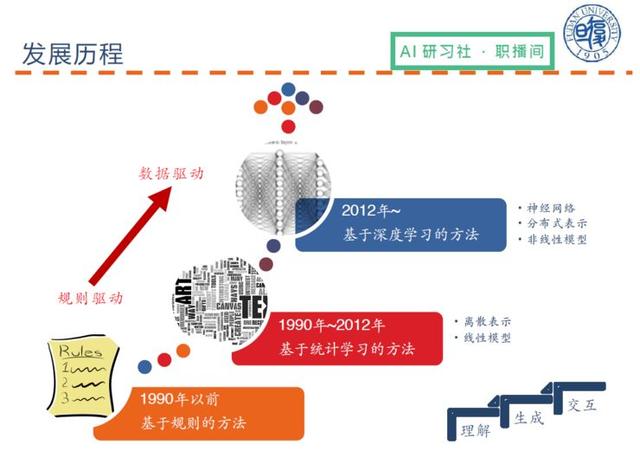
İnsanlar için ideal doğal dil işleme akışı nedir?
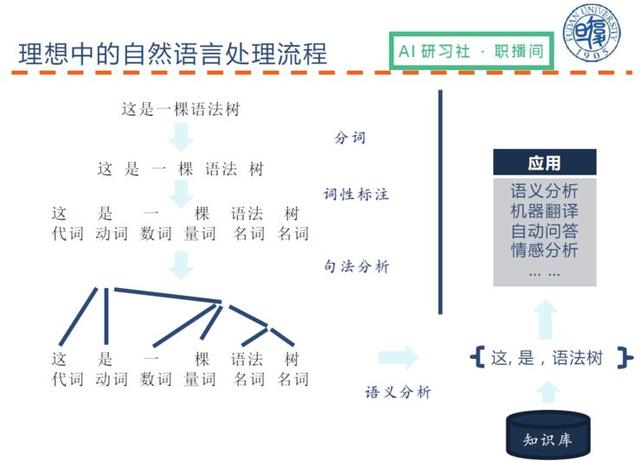
(İdeal doğal dil işleme sürecinin ayrıntılı açıklaması için lütfen videoyu 00:08:10 'da izleyin)
Derin öğrenmeye dayalı doğal dil işleme
Derin öğrenmeye dayalı doğal dil işlemenin nasıl bir şey olduğundan bahsedelim. Önce bir bilgisayarda dil anlambiliminin nasıl temsil edileceğinden bahsedeyim?

Dil anlambiliminin bilgisayarlarda temsil edilmesinden önce bazı bilgi tabanı kuralları, derin öğrenmede ise dağıtılmış temsil yöntemi kullanılmıştır. İşte bir resim örneği:

(Dilin anlambilimine ve durumlarına ilişkin özel açıklamalar için lütfen videoyu 00:09:00 'da izleyin)
Burada doğal dil işlemede çok önemli bir kavramı tanıtacağız - Kelime Gömme Bu konsept, 2013'ten beri giderek popüler hale geldi.
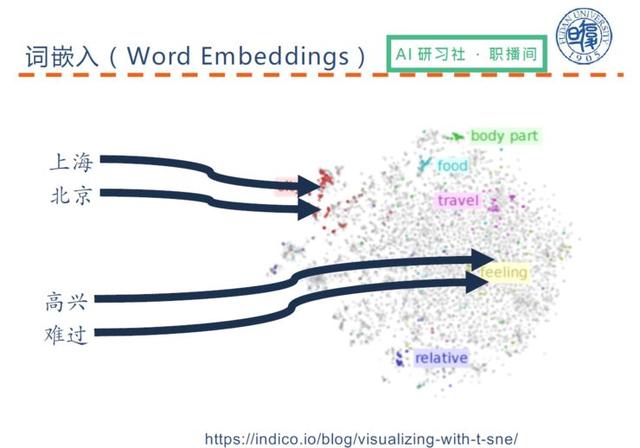
(Kelime yerleştirmenin belirli bir açıklaması için lütfen 00:10:40 videoya tekrar bakın)
Kelime temsilinden sonra cümle temsili dikkate alınmalıdır, ancak cümle temsili kelime temsilinden çok daha zordur.Burada esas olarak sinir ağlarında cümlelerin nasıl temsil edileceğinden bahsediyoruz.
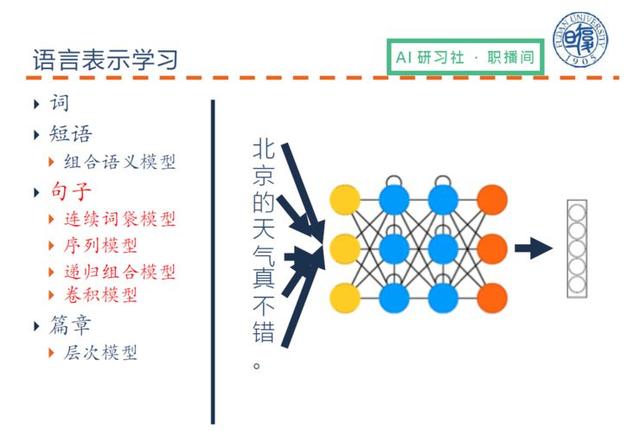
(Sinir ağındaki cümle temsilinin spesifik açıklaması için lütfen 00:12:42 videoyu izleyin)
Kelime ve cümle temsillerini aldıktan sonra, doğal dil işleme görevlerinin türlerini özetlemek isterseniz, bunları aşağıdaki kategorilere ayırabilirsiniz:
-
İlk olarak, metin oluşturma ve görüntü tanımlama oluşturma görevleri dahil olmak üzere sıraya yaz (nesne);
-
İkinci olarak, metin sınıflandırması ve duyarlılık analizi görevleri dahil olmak üzere kategoriye göre sıralama;
-
Üçüncüsü, Çince analizi, konuşma parçası etiketleme ve anlamsal rol etiketleme görevleri dahil olmak üzere sekansa senkronize edilmiş sekans;
-
Dördüncüsü, makine çevirisi, otomatik özetleme ve diyalog sistemi görevleri dahil olmak üzere diziye asenkron sekans.
Doğal Dil İşlemede Derin Öğrenmenin İkilemi
Bilgisayarla görü ile karşılaştırıldığında, derin öğrenmenin doğal dil işlemede daha büyük bir ikilemi vardır.
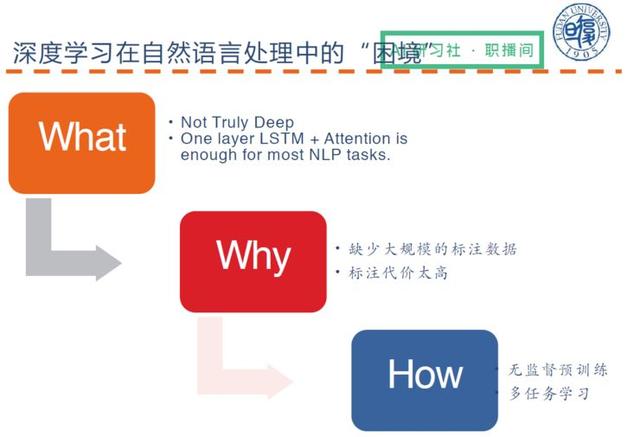
Bu zorluklar ışığında, şu anda iki grup nispeten etkili çözüm bulunmaktadır:
Biri denetimsiz ön eğitimdir;
İkincisi, çok görevli öğrenmedir.
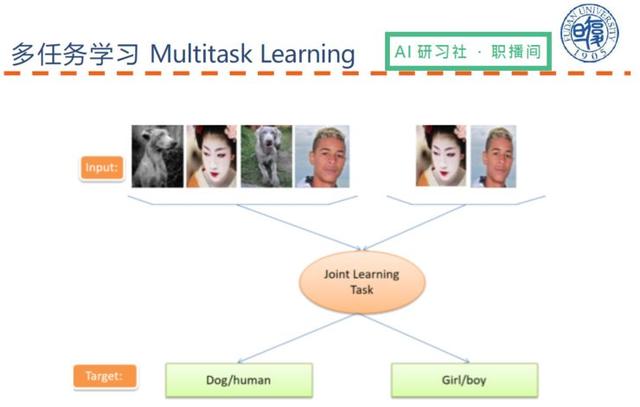
Öyleyse neden çoklu görev öğrenimi doğal dil işlemede bu kadar iyi performans gösteriyor? Sebepler şunları içerir:
-
Örtük veri geliştirme;
-
Daha doğal temsil öğrenimi;
-
Daha iyi temsil öğrenimi, iyi bir temsilin birden fazla görevin performansını iyileştirebilmesi gerekir;
-
Düzenlilik: Paylaşılan parametreler, aşırı uyumu önleyebilecek şekilde ağ yeteneğini bir dereceye kadar zayıflatır;
-
Gizli dinleme (gizli dinleme).
(Doğal dil işlemede derin öğrenmenin spesifik açıklamaları ve nedenleri ve çözümleri-denetimsiz öğrenme ve çoklu görev öğrenimi için lütfen 00:13:51 adresindeki videoya tekrar bakın)
Doğal dil işlemede çok görevli öğrenme
Doğal dilde çoklu görev öğreniminden bahsedelim. İdeal olarak, doğal dil işleme, girdiden sözcüksel analize, sözdizimsel analize ve ardından çoklu görev yapmaya kadar bir süreçtir.Çok görevli doğal dil işleme, sözcüksel analiz, sözdizimsel analiz ve görevleri aynı anda gerçekleştirmek için paylaşılan bir modülü kullanabilir. .
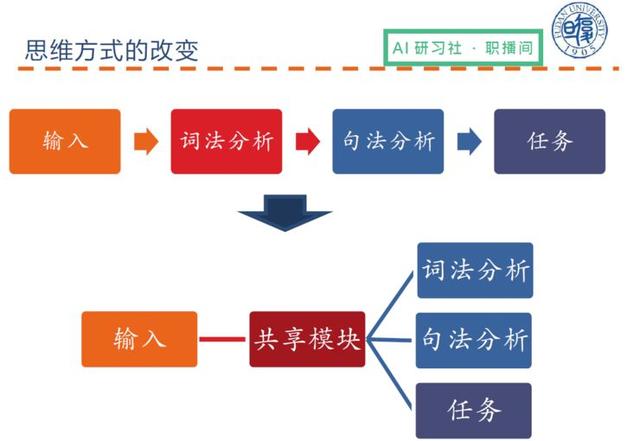
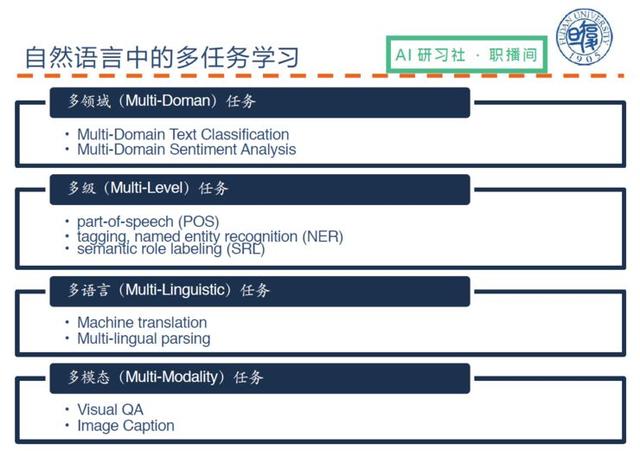
Doğal dilde çok görevli öğrenme aşağıdaki kategoriler halinde özetlenebilir:
-
Birincisi, çok alanlı (Multi-Doman) bir görevdir
-
İkincisi, çok seviyeli (Çok Seviyeli) bir görevdir
-
Üçüncüsü, Çok Dilbilimsel görevdir
-
Dördüncüsü, çok modlu (Çok Modalite) bir görevdir
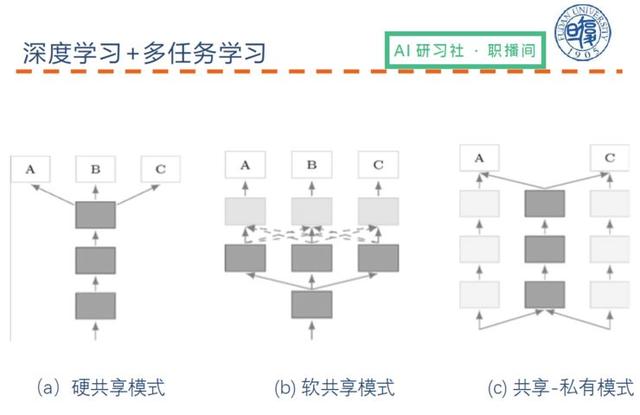
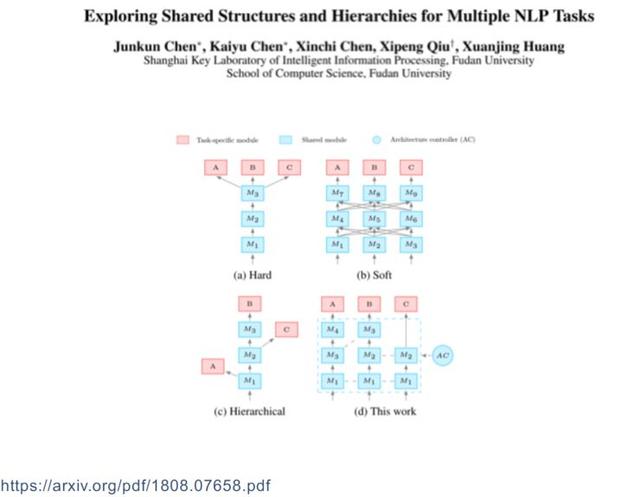
Derin öğrenme altında çok görevli öğrenme, genellikle aşağıdaki üç şekilde özetlenebilecek bazı çok seviyeli sinir ağlarını paylaşır:
-
İlk olarak, zor paylaşım modeli
-
İkincisi, yumuşak paylaşım modeli
-
Üçüncüsü, paylaşılan özel model
(Doğal dil işlemede çoklu görev öğrenme türleri ve derin öğrenmedeki çok görevli öğrenme yöntemleri hakkında spesifik açıklamalar için lütfen 00:23:15 adresindeki videoya tekrar bakın)
Paylaşım modları aşağıdaki kategorilere ayrılabilir:

Daha sonra, laboratuvar kağıtlarına ve ilgili bazı makalelere odaklanacağım ve bu paylaşım modlarını tanıtacağım:
-
Sert paylaşım modu

-
Yumuşak paylaşım modu
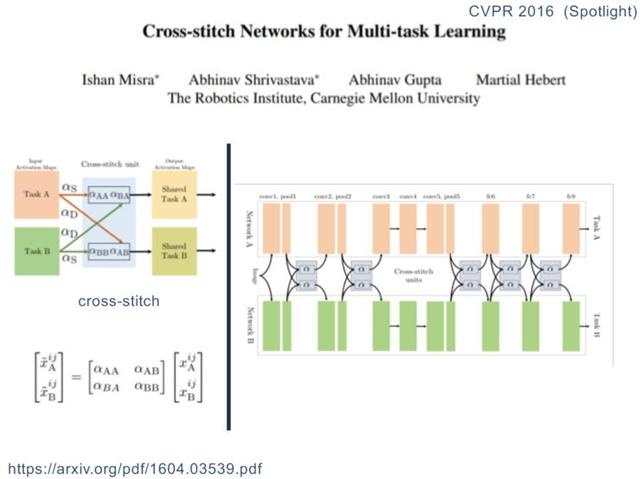
-
Paylaşılan özel mod
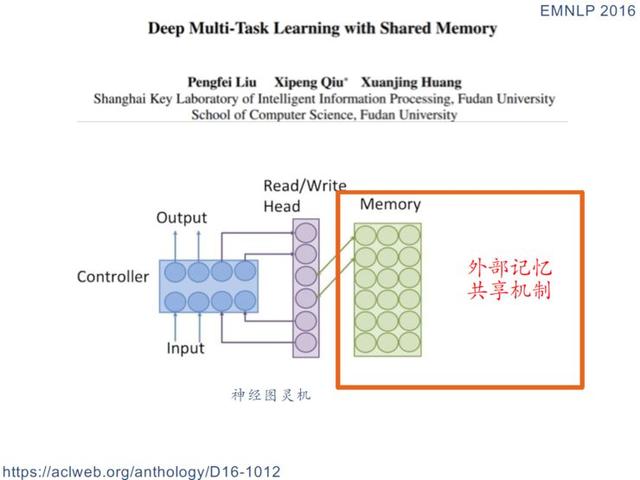
-
İşlev paylaşım modu
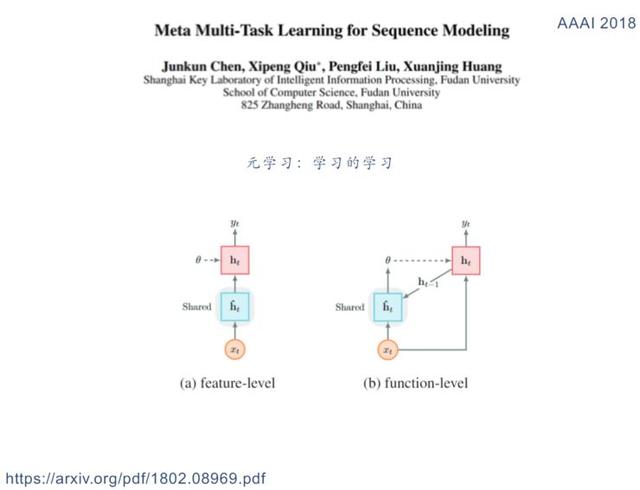
-
Çok seviyeli paylaşım modu

-
Birincil ve ikincil görev modu
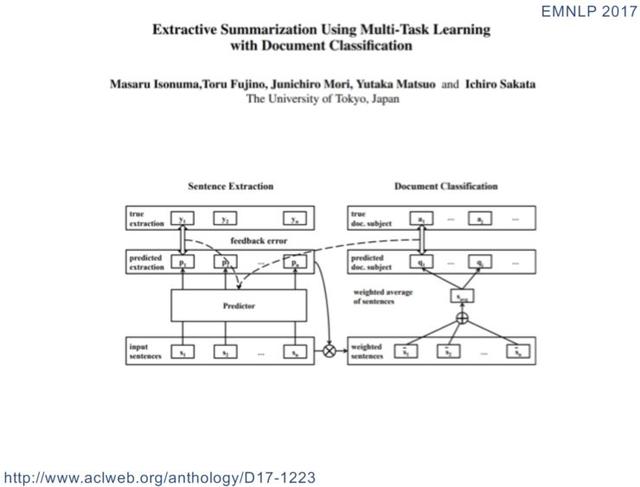
Ardından, paylaşım modu keşfi hakkında konuşun:
(Bu tür paylaşım modlarının vaka tanıtımı ve paylaşım modlarının keşfedilmesiyle ilgili özel açıklamalar için lütfen 00:26:35 adresindeki videoyu tekrar izleyin)
Yeni çoklu görev kıyaslama platformu
Daha sonra, çok görevli öğrenim için iki ana akım kıyaslama daha tanıtacağım.
Geçen yıldan beri popüler olan okuduğunu anlama hakkında konuşmama izin verin, yani makine bir veya daha fazla belgeyi okuyor ve bazı ilgili soruları cevaplıyor. Doğal dil işleme için zor bir görev türüdür ve iki ölçüt getirir.
-
ilk olarak Decanlp Çok görevli öğrenme için ortak bir eğitim seti olarak birçok Q1 görevini bir araya getirir.Her görevin farklı değerlendirme göstergeleri vardır ve her görevin türü de çok farklıdır. Bazıları çeviri ve bazıları özettir.
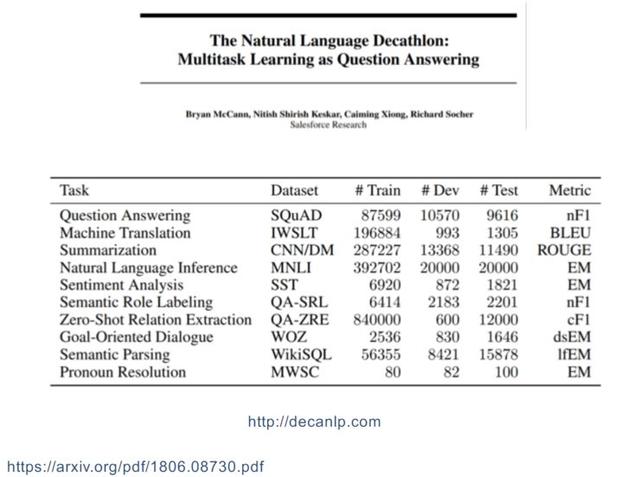
-
İkincisi, yakın zamanda herkes tarafından maksimize edilen GLUE veri kümesidir. Decanlp kavramına benzeyen NYU tarafından yapılmıştır ve aynı zamanda QA ve duyarlılık sınıflandırmasına benzer bir veri setidir.
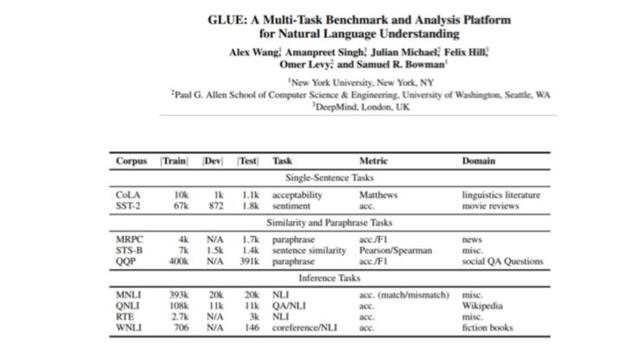
Bu iki veri setinde hala geliştirme için çok yer var, ancak kişisel olarak insanların son zamanlarda sıralamayı yapma şeklinin biraz değiştiğini hissediyorum.
(Bu iki ölçütün spesifik açıklamaları ve konuşmacılar tarafından paylaşılan bazı düşünceler için lütfen 00:46:50 adresindeki videoya tekrar bakın)
Yukarıdakiler, bu sayıda davetliler tarafından paylaşılan tüm içeriklerdir. Bu herkese açık sınıfın tekrar videosu makalenin sonunda tıklanabilir. Orijinali okuyun İzlemek.
Daha fazla genel sınıf videosu için lütfen Leifeng.com AI Araştırma Topluluğu'nu ( ziyaret edin. WeChat genel hesabını takip edin: AI Araştırma Enstitüsü (okweiwu), en son genel sınıf canlı yayın süresi önizlemesini edinebilirsiniz.