Canlı | Microsoft Super Mahjong AI Suphx Ar-Ge ekibi teknik ayrıntıları derinlemesine açıklıyor
Çin'de ve hatta tüm Asya bölgesinde tanınmış bir toplu eğlence projesi olan Mahjong, yalnızca Asya'da yüz milyonlarca oyuncuya sahiptir. Son derece yüksek popülerlik, birçok insanı Mahjong'un çok kolay bir masa oyunu olduğunu düşündürüyor. Bununla birlikte, mahjong'u başlatmak kolay olsa da, gerçekten iyi bir şekilde mahjong oynamak ve mahjong'da uzman olmak çok zordur. Örnek olarak uluslararası üne sahip profesyonel bir mahjong platformu olan tenhou.net'i ele alalım Platformdaki 350.000'den fazla aktif oyuncu arasında, oyuncuların% 1'inden azı 7 etap ve üzeri profesyonel seviyeye ulaştı.
Ağustos 2019'da Microsoft, Dünya Yapay Zeka Konferansı'nda Microsoft Research Asia tarafından geliştirilen bir mahjong AI sistemi olan Suphx'in, uluslararası üne sahip profesyonel mahjong platformu "Tianfeng" üzerinde onuncu aşamaya yükseltilen ilk AI sistemi olduğunu ve gücünün aşıldığını resmen duyurdu Platform, odadaki en iyi insan oyuncuların ortalama seviyesini açıklıyor. Mahjong AI'nın zorlukları nelerdir? Suphx, AI oyun alanında bu atılımı nasıl başardı? Microsoft Research Asia'nın Suphx Ar-Ge ekibi arXiv ile ilgili makaleler yayınladı (orijinal metni okumak için tıklayın) Bu makale, makalenin temel içeriğini açıklayacaktır.

Şekil 1: Tianfeng oyuncu sıralaması dağılımı ve Suphx sıralaması, Suphx Tianfeng oyuncularının% 99,99'undan fazlasını alıyor
Mahjong AI'nın karşılaştığı zorluklar
Mahjong AI sistemi Suphx, temel olarak derin takviye öğrenme teknolojisine dayanmaktadır. Derin pekiştirmeli öğrenme, bir dizi oyun AI'sında büyük başarı elde etmiş olsa da, bunu doğrudan Mahjong AI'ya uygulamak kolay değildir ve çeşitli zorluklarla karşı karşıyadır.
1. Zorluk: Mahjongun puanlama kuralları genellikle çok karmaşıktır , Tianfeng platformu gibi rekabetçi mahjong'da, puanlama kuralları daha karmaşıktır.
Her şeyden önce, bir tur mahjong oyununda genellikle 8 tur veya daha fazla olur.Her turdan sonra, dört oyuncu bu tur için bir puan alır (pozitif veya negatif olabilir). Bir oyunun 8 turunun tamamı (veya daha fazlası) bittiğinde, dört oyuncu, oyunun bu turunun puan ödülünü hesaplamak için tüm turların toplam puanlarına göre sıralanır. Tianfeng platformunda, birinci veya ikinci oyuncular belirli sayıda puan alacak, üçüncü oyuncu aynı puanlara sahip olacak ve dördüncü oyuncu belirli bir sayıda puan düşürülecektir. Bir oyuncunun oynadığı oyun sayısı arttıkça puanları değişecek, puanları belirli bir seviyeye çıktığında yükseltilecek ve oyuncunun puanları 0'a düşüldüğünde bir puan düşürülecektir. Bu nedenle, sıralamayı yükseltmek için oyuncuların olabildiğince birinci veya ikinci sırada yer alması ve dördüncü sırada olmaktan kaçınmaya çalışması gerekir.
Bir oyunun bir turunun son noktaları birden fazla turun toplam puanı ile belirlendiğinden, usta stratejik olarak bazı turları kaybedebilir. Örneğin, bir oyuncu ilk 7 turda zaten büyük bir skorla liderlik etmişse, kasıtlı olarak 8. turu kaybedebilir ve üçüncü veya dördüncü sıradaki oyuncunun turu kazanmasına izin vererek toplam puanının ilk sırada olmasını sağlayabilir. Sonunda oyunun bu turunun maksimum puanlarını alın. Başka bir deyişle, bir turun kazanılması veya kaybedilmesi, oyuncunun iyi oynayıp oynamadığını doğrudan temsil etmez, bu nedenle her turun puanını, pekiştirmeli öğrenme için bir ödül geri bildirim sinyali olarak doğrudan kullanamayız.
İkinci olarak, Tianfeng platformundaki oyunun her turu için puanlama kurallarının, kazananın kart türüne göre puanı hesaplaması gerekir.Hepsi bir arada, karışık, açık, vb. Gibi kart türü için birçok olasılık vardır, farklı kart türleri Puan büyük ölçüde değişecektir. Bu tür puanlama kuralları, satranç ve Go gibi oyunlardan çok daha karmaşıktır. Mahjong ustalarının birinci, ikinci veya dördüncü sırayı elde etmek için Hu kart olasılığını ve Hu kartının puanını dengelemek için kart türünü dikkatlice seçmeleri gerekir.
Zorluk 2: Oyun teorisi açısından Mahjong, eksik bilgiler içeren çok oyunculu bir oyundur . Mahjong'da toplam 136 taş vardır.Her oyuncu kendi 13 eli ve herkesin oynadığı taşlar dahil olmak üzere sadece birkaç taşı görebilir.Diğer üç oyuncu da dahil olmak üzere daha fazla taş vardır. El kartları ve duvar kartları. Bu kadar çok gizli bilinmeyen bilgiyle karşı karşıya kalan mahjong oyuncularının kendi ellerine göre iyi bir karar vermeleri zordur (bkz. "Hangi oyun AI türü daha zordur? Analiz etmek için matematiksel yöntemler kullanın", Oyunun gizli bilgileri ve karmaşıklığı analiz edilir).

Zorluk 3: Karmaşık puanlama kurallarına ek olarak, Mahjong'un oyun stili de daha karmaşıktır ve birden fazla karar türünün dikkate alınması gerekir Örneğin, normal kart çekme ve oynamaya ek olarak, genellikle bir kart alıp almama, bir karta dokunma, bir kart tutma, dik durma ve bir kart oynayıp oynamayacağına da karar vermek gerekir. Herhangi bir oyuncunun vuran kong ve Hu kartları, kart çekme sırasını değiştirecektir, bu nedenle Mahjong için normal bir oyun ağacı oluşturmak bizim için zordur. Bir oyun ağacı inşa etsek bile, oyun ağacı çok büyük olacak ve sayısız dalı olacak, bu da Monte Carlo Ağaç Arama (MCTS) ve Monte Carlo karşı olgular gibi bazı iyi yöntemlere yol açacaktır. Pişmanlığın Minimizasyonu (MCCFR) algoritması doğrudan uygulanamaz.

Suphx'in karar süreci ve model mimarisi
Suphx'in kart oyunu stratejisi, Mahjong-atan kart modeli, ayakta duran dik model, yemek kartı modeli, dokunma kartı modeli ve kaldıraç modelinin karmaşık karar verme türleriyle başa çıkmak için eğitilmesi gereken 5 modeli içerir. Buna ek olarak, Suphx, kazanmanın mümkün olduğunda kazanmaya karar vermek için kural tabanlı bir kazanma modeline de sahiptir.
Suphx'in belirli karar verme süreci aşağıdaki şekilde gösterilmektedir:
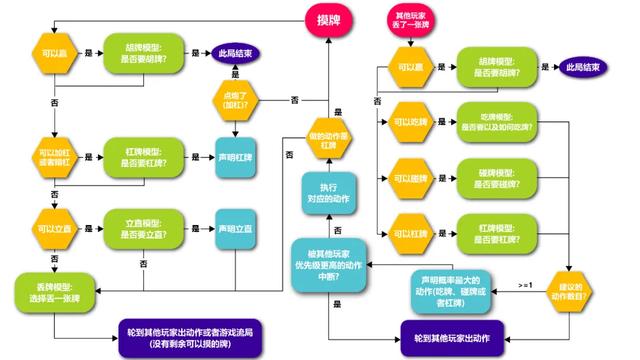
Şekil 2: Suphx karar süreci
Suphx'in beş modelinin tümü, derin artık evrişimli sinir ağlarına dayanmaktadır.Genel yapıları (Şekil 3 ve Şekil 4'te gösterildiği gibi) benzerdir ve temel fark, girdi ve çıktı boyutlarında yatmaktadır. Kayıp kart modelinin çıktısında 34 karttan herhangi birini kaybetme olasılığını temsil eden 34 düğüm vardır.Diğer 4 model çıktı katmanında ise dik durma, kart yeme, kartlara dokunma ve oyun kartları olasılığını temsil eden sadece 2 düğüm vardır.

Şekil 3: Atılan kart modelinin yapısı

Şekil 4: Dik durma, yeme kartları, dokunma kartları ve oyun kağıtlarının model yapısı
Bu modellerin girdisi iki geniş bilgi kategorisi içerir:
1. Oyuncunun kendi eli, açık kartları (atılan kartlar, dokunulan kartlar ve açık çubuklar dahil) ve her oyuncunun kümülatif skoru, koltuğu, sıralaması vb. Gibi güncel gözlemlenebilir bilgiler.
2. Belirli bir kartı oynamak için kaç kart kazanmanız gerektiği, kaç puan kazanabileceğiniz, yenme olasılığının ne olduğu gibi geleceği tahmin etmek için bilgiler.
Konvolüsyonel sinir ağı CNN'nin görüntü verilerini işlemek için daha uygun olduğu, ancak mahjong'un kendisinin doğal görüntü verisi olmadığı, bu nedenle mahjong'un bu bilgisini CNN'nin işleyebilmesi için kodlamamız gerektiği belirtilmelidir. Şekil 5, oyuncunun elini kodlamak için 4x34 matris kullandığımızı göstermektedir.

Şekil 5: El bilgilerinin matris ifadesi
Aslında, Suphx geliştirmenin ilk aşamasında, insan oyuncuların davranışlarını taklit etmek için denetimli öğrenmede iyi performans gösteren, ancak pekiştirmeli öğrenmeye uygun olmayan karar ağacı algoritması LightGBM'yi benimsedik, bu yüzden daha sonra CNN'e geçtik.
Suphx eğitim algoritması
Suphx eğitim süreci üç ana adıma bölünmüştür: Birincisi, denetimli öğrenme yoluyla bu 5 modeli eğitmek için Tianfeng platformundan ana oyun kayıtlarını kullanın ve ardından Mahjong'un benzersizliğini çözmek için tasarladığımız kendi kendine oyun pekiştirmeli öğrenmeyi ve iki teknolojiyi kullanın. Sonunda, Suphx'in gerçek savaştaki yeteneğini daha da geliştirmek için çevrimiçi strateji uyarlamalı algoritma kullanıyoruz.
Aşağıda Suphx öğrenme algoritmasındaki bazı temel bağlantılara odaklanacağız:
Dağıtılmış pekiştirmeli öğrenme
Suphx'in tüm eğitim süreci çok karmaşıktır ve birden çok GPU ve birden çok CPU'nun koordinasyonunu gerektirir, bu nedenle dağıtılmış bir mimari benimsiyoruz (Şekil 6'da gösterilmiştir). Mimari bir parametre sunucusu ve çoklu kendi kendine oyun düğümlerini içerir Her bir düğüm, çoklu strateji arasında (yani mahjong oynamak) oyunları yürütmek için çoklu mahjong simülatörleri ve çoklu çıkarım motorları içerir. Her bir kendi kendine oyun düğümü periyodik olarak kart oyununun kaydını parametre sunucusuna gönderir ve parametre sunucusu bu kart oyunu kayıtlarını mevcut stratejiyi eğitmek ve geliştirmek için kullanır. Bir süre sonra, kendi kendine oyun düğümü, kendi kendine oyun oynamanın bir sonraki aşaması için parametre sunucusundan en son stratejiyi alır.
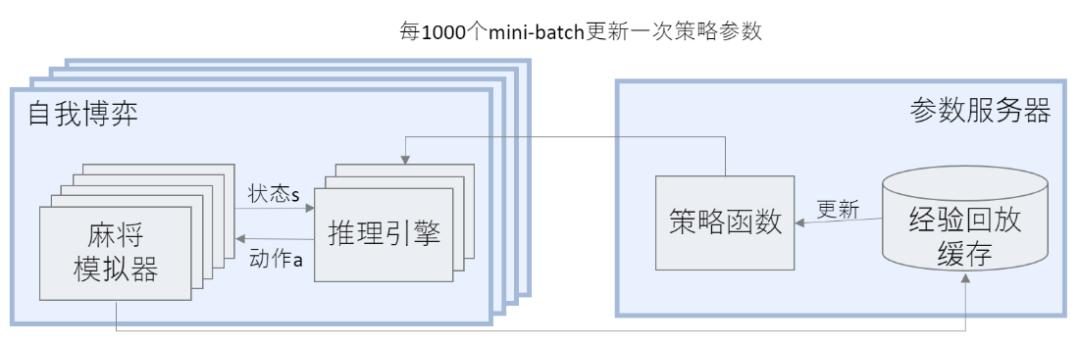
Şekil 6: Dağıtılmış eğitim
Pekiştirmeli öğrenme eğitiminin stratejinin entropisine çok duyarlı olduğunu bulduk. Entropi çok küçükse, pekiştirmeli öğrenme eğitimi hızla birleşir ve kendi kendine oyun stratejiyi önemli ölçüde geliştiremez; entropi çok büyükse, pekiştirmeli öğrenme eğitimi dengesiz hale gelir ve eğitim sürecinde strateji değişiklikleri çok yoğun olur. Bu nedenle, pekiştirmeli öğrenme eğitim sürecinde politika entropisini düzenliyoruz ve entropinin ne çok büyük ne de çok küçük olmasını istiyoruz.
Küresel ödül tahmini
Yukarıda belirtildiği gibi, Mahjong'un puanlama kuralları çok karmaşıktır - oyuncuların her turda puanları vardır ve puanlar, birden çok raundun toplam puanlarına göre hesaplanır. Ancak, ne oyun başına puanlar ne de bir raundun son noktaları, pekiştirmeli öğrenme eğitimi için geri bildirim sinyalleri için uygun değildir.
Bir oyunda birden fazla tur olduğu için, bir geri bildirim sinyali iyi oynanan turlar ile kötü oynanan turlar arasında ayrım yapamayacağından turun sonundaki nihai ödül puanı puanları. Bu nedenle, pekiştirmeli öğrenme için her tur için ayrı ayrı eğitim sinyalleri sağlamamız gerekir.
Bununla birlikte, her turun skorları ayrı ayrı hesaplansa bile, özellikle en iyi profesyonel oyuncular için bir turun kalitesini yansıtmayabilir. Örneğin, bir oyun turunun son bir veya iki vuruşunda, kümülatif puanda birinci sırada yer alan oyuncu, genellikle kümülatif skor daha yüksek olduğunda daha muhafazakar hale gelir ve üçüncü veya dördüncü sıradaki oyuncuya bilinçli olarak izin verir. Oyuncu bu turu kazanır ve ikinci sıradaki oyuncunun kazanmasını engeller, böylece ilk genel sıralama sıkı bir şekilde korunabilir. Başka bir deyişle, negatif bir puan mutlaka kötü bir strateji anlamına gelmez.
Bu nedenle, pekiştirmeli öğrenme eğitimi için etkili sinyaller sağlamak için, son oyun ödülünü oyunun her turuna uygun şekilde atfetmemiz gerekir. Bu amaçla, bu oyunun ve önceki tüm oyunların bilgilerine dayanarak nihai oyun ödülünü tahmin edebilen küresel bir ödül tahmin edici getirdik. Suphx'te ödül öngörücü, Şekil 7'de gösterildiği gibi tekrarlayan bir sinir ağıdır (GRU).

Şekil 7: Küresel ödül tahmini
Ödül tahmin edicisinin eğitim verileri, Tianfeng platformundaki usta oyuncuların geçmiş kayıtlarından gelir ve eğitim süreci, tahmin edilen değer ile nihai oyun ödülü arasındaki kare hatasını en aza indirmektir. Tahmin edenin eğitilmesinden sonra, kendi kendine oyun tarafından oluşturulan oyun için, mevcut tur tarafından tahmin edilen son ödül ile bir önceki turda tahmin edilen son ödül arasındaki farkı, raundun pekiştirici öğrenme eğitimi için geri bildirim sinyali olarak kullanırız.
Peygamber Koçu
Mahjong'da diğer oyuncuların el kartları, duvar kartları vb. Gibi çok sayıda gizli bilgi vardır. Bu gizli bilgiler elde edilemezse, belirli bir eylemin (örneğin, otuz bin atma) iyi ya da kötü olduğundan emin olmak zordur, bu yüzden Mahjong Zorluğun temel nedenlerinden biri. Bu durumda Suphx, pekiştirmeli öğrenme yoluyla stratejiyi geliştirebilse de, öğrenme hızı çok yavaş olacaktır.
Takviye öğrenme eğitimini hızlandırmak için, (1) oyuncunun kendi özel el kartları, (2) tüm oyuncuların genel kartları, (3) diğer halka açık bilgiler dahil olmak üzere tüm bilgileri görebilen bir "peygamber" tanıttık. , (4) Diğer üç oyuncunun özel elleri, (5) Duvar kartları. Yalnızca (1), (2) ve (3) normal oyuncular tarafından kullanılabilir ve (4) ve (5) yalnızca "peygamber" in elde edebileceği ek "mükemmel" bilgilerdir.

Şekil 8: Solda normal gözlemlenebilir bilgi, sağda ise tam bilgi (rakibin duvar kartlarının "mükemmel" bilgileri dahil)
Bu "haksız" mükemmel bilgilerle, "Peygamber", yoğun öğrenme ve eğitimden sonra kolayca mahjong süper ustası olabilir ve istikrarlı rütbe 20 segmenti kolayca aşabilir. Buradaki zorluk, AI eğitimini yönlendirmek ve hızlandırmak için "peygamber" in nasıl kullanılacağıdır. Deneyler, basit bilgi damıtma veya taklit öğrenmenin "peygamber" in "süper güçlerini" AI sistemine çok iyi aktaramayacağını göstermiştir - yalnızca sınırlı bilgi alabilen normal bir yapay zeka için İyi eğitilmiş bir "peygamber" in davranışını taklit etmenin zor olduğunu söyledi, çünkü "peygamber" in yeteneği sıradan yapay zekanın yeteneğinin çok ötesinde çok güçlüdür. Örneğin, "peygamber" diğer oyuncuların ellerini görür ve her oyuncunun hangi kartları oynadığını bilir, böylece diğer oyuncuların kayıp kartlar nedeniyle kartları yenmesini önlemek için kesinlikle güvenli kartlar oynayabilir.Ancak normal AI bu bilgiye sahip değildir. Peygamber'in bu kartı neden oynadığını hiç anlamayabilirsiniz, bu yüzden bu davranışı öğrenememiştir. Bu nedenle, normal AI eğitimine rehberlik etmek için "peygamber" i kullanmanın daha akıllı bir yoluna ihtiyacımız var.

Suphx'te yaklaşımımız şu şekildedir:
İlk olarak, "peygamberi" yoğun öğrenmeyle eğitin ve "peygamberi" eğitmek için mükemmel bilgi dahil tüm özellikleri kullanın. Bu süreçte "peygamber" in öğrenme süreci kontrol edilmeli ve çok güçlü hale getirilmemelidir.
Sonra, maskeler ekleyerek mükemmel özellikleri yavaş yavaş kaybettik, böylece "peygamber" sonunda normal yapay zekaya geçiş yaptı.
Ardından, normal AI'yı eğitmeye ve belirli sayıda yineleme gerçekleştirmeye devam ediyoruz. Sürekli eğitim sürecinde iki teknik kullanılır: biri öğrenme oranını onda bire düşürmektir; ikincisi, reddetme örneklemesini kullanırız, yani kendi kendine oyun tarafından oluşturulan örnek mevcut modelin davranışından çok farklıysa, Bu örnekleri atın. Deneylerimize göre, bu beceriler olmadan, sürekli eğitim istikrarsız olacak ve daha fazla gelişme getirmeyecektir.
Parametreli Monte Carlo strateji uyarlaması
Bir mahjong ustası için, ilk eller farklı olduğunda stratejisi çok farklı olacaktır. Örneğin, ilk el iyi ise, daha fazla puan almak için aktif olarak saldıracaktır; ilk el iyi değilse, savunmaya ve kayıpları azaltmak için Hu kartlarından vazgeçme eğiliminde olacaktır. Bu, Go AI ve StarCraft gibi önceki oyun AI'larından çok farklı. Bu nedenle, savaş sırasında çevrimdışı eğitim stratejisini ayarlayabilirsek, daha güçlü bir Mahjong AI elde edebiliriz.
Monte Carlo Ağaç Arama (MCTS), savaşta kazanma oranını artırmak için Go gibi oyun yapay zekasında gelişmiş bir teknolojidir. Ne yazık ki, daha önce de belirtildiği gibi, mahjong çizme ve oynama sırası sabit değildir ve normal bir oyun ağacı oluşturmak zordur. Bu nedenle MCTS, Mahjong AI'ya doğrudan uygulanamaz. Suphx'te, parametre Monte Carlo strateji uyarlaması (pMCPA) adlı yeni bir yöntem tasarladık.
Mahjong AI'ya ilk el verildiğinde, çevrimdışı eğitim stratejisini verilen ilk ele daha uygun hale getirmek için ayarlayacağız. Spesifik süreç:
Simülasyon: Üç rakibin ellerini ve duvar kartlarını rastgele örnekleyin ve ardından simülasyon oyununu tamamlamak için çevrimdışı eğitim stratejisini kullanın. Toplamda K kez yapın.
Ayarlama: Gradyanı güncellemek ve stratejide ince ayar yapmak için bu K oyunlarının sürecini ve puanını kullanın.
Kart oynamak: Diğer oyunculara karşı oynamak için ince ayarlanmış stratejiyi kullanın.
Deneylerimiz gösteriyor ki, mahjong'un gizli bilgi kümesinin ortalama boyutu ile karşılaştırıldığında, K simülasyon sayısı sayısının büyük olması gerekmiyor ve pMCPA'nın bu el için tüm olası sonraki durumları toplamasına gerek yok. İstatistik. PMCPA parametreleştirilmiş bir yöntem olduğundan, güncellenmiş stratejide ince ayar yapmak, sınırlı simülasyonlardan elde edilen bilgileri görünmeyen bir duruma genelleştirmemize yardımcı olabilir.
Çevrimiçi savaş
Suphx, Tianfeng platformundaki özel odada diğer oyunculara karşı 5.000'den fazla oyun oynadı, 10 seviyede odanın en yüksek seviyesine ulaştı ve stabil seviyesi, platformdaki diğer ikisini geçerek 8.7'ye (Şekil 9'da gösterildiği gibi) ulaştı. İyi bilinen bir AI seviyesi ve en iyi insan oyuncuların ortalama seviyesi.
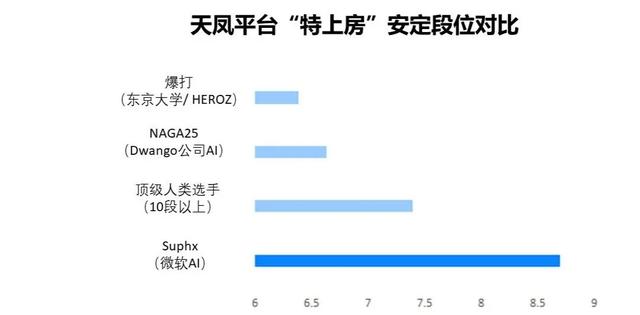
Şekil 9: Tianfeng platformu "Özel Shangfang" kararlılığının karşılaştırması
Aşağıdaki tablo, 1/2/3/4 pozisyon oranı, Hu kart oranı ve atış oranı dahil olmak üzere bu oyunlarda bazı Suphx istatistiklerini göstermektedir. Suphx'in özellikle savunmada iyi olduğunu ve 4 bit hızının ve anlaşma oranının özellikle düşük olduğunu gördük.
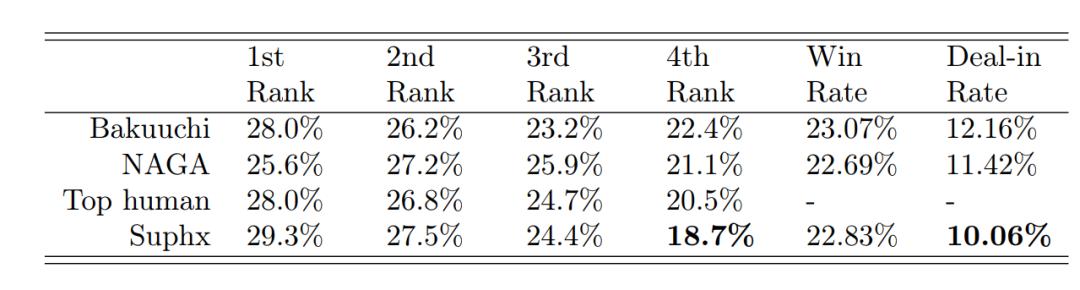
Not: Yukarıdaki tablodaki Bakuuchi, Tokyo Üniversitesi / HEROZ tarafından geliştirilen Mahjong AI "Boom" dur.
Suphx'in "farklı bir yaklaşım" olduğu söylenebilir. Farklı bir kişisel tarzı vardır ve birçok yeni strateji ve oyun stili yaratmıştır.Örneğin, özellikle güvenli kartları saklamakta iyidir, karma olma eğilimindedir vb. Aşağıdaki şekil Tianfeng platformundaki gerçek savaş sırasında Suphx tutma güvenlik kartlarının bir örneğini göstermektedir. Şu anda Suphx'in (Güney) kartları atması gerekiyor. Eğer bir insan oyuncu ustasıysa, bu durumda kuzey rüzgarını kaybedecek, ancak Suphx şu anda 7 kaybedecek, bu da insan oyunculara alışılmadık görünüyor. 7 iyi bir kart olduğu için 7 kaybetmek Hu kartın ilerlemesini yavaşlatacaktır. Suphx'in 7'yi kaybetmesinin ve kuzey rüzgarını tutmasının nedeni kuzey rüzgarının bir güvenlik kartı olması.Yani gelecekte bir noktada birisi aniden ayağa kalkıp bir engel isterse, Suphx top atmadan kuzey rüzgarını oynayabilir. Hâlâ bir Hu kart şansı var; Kuzey Rüzgârını önde kaybetmişse, o zaman bu sefer güvenli bir kart oynamak için elindeki iyi kartları kaldırması gerekecek ve bu da Hu kartlarının olasılığını büyük ölçüde azaltacaktır.

Resim 10: Suphx (güney konumu) güvenlik kartını kuzey rüzgarında tutar
Suphx oyununu izleyen birçok oyuncu, oyundan ilham aldıklarını ifade ettiler. Bazı mahjong meraklıları, Suphx'e "Mahjong ders kitabı" ve "Suphx öğretmeni" bile atıfta bulundular. Suphx'in oynanışını öğrenerek, mahjonglarını daha da geliştirmelerine ve zenginleştirmelerine yardımcı oldular. beceri. "300'den fazla Suphx maçı izledim ve artık insan oyuncuları bile izlemiyorum. Suphx'ten birçok yeni teknik öğrendim ve bunlar üç kişilik mahjong oyunum için çok ilham verici," Mahjong Yarışmacı Tai sosyal medyada dedi. Geçen yıl haziran ayında, world's dünyanın 15. üç kişilik Mahjong Tianfeng kazananı ve hem dört oyunculu Mahjong hem de üç kişilik Mahjong'da Tianfeng rütbesini kazanan ilk en iyi oyuncu oldu.
Özet ve görünüm
Suphx, açık ara en güçlü Mahjong AI sistemidir ve aynı zamanda Tianfeng platformundaki en iyi insan oyuncuların çoğunu geride bırakan ilk Mahjong AI'dır. Suphx'in Tianfeng platformundaki başarılarının bugün sadece bir başlangıç olduğuna inanıyoruz.Gelecekte, Suphx için daha fazla güncellenmiş teknolojiler sunacağız ve Mahjong AI ve kusurlu bilgi oyunu araştırmasının ön saflarını desteklemeye devam edeceğiz.
Aynı zamanda, AI oyun araştırmalarının yapay zeka teknolojisinin yenilikçi gelişimini destekleyebileceğini, yapay zekanın gerçekten hayatımıza girmesine izin verebileceğini ve insanların daha karmaşık ve gerçekçi zorlukları çözmelerine yardımcı olabileceğini umuyoruz. Finansal piyasa tahminleri ve lojistik optimizasyonu gibi birçok gerçek dünya sorunu, karmaşık işlemler / ödül kuralları ve eksik bilgiler dahil olmak üzere Mahjong ile aynı özelliklere sahiptir.
Suphx'te Mahjong AI için tasarladığımız, küresel ödül tahmini, peygamber rehberliği ve parametreli strateji uyarlaması dahil olmak üzere tasarladığımız teknolojilerin gerçek dünya uygulamalarında umut verici olacağına inanıyoruz.Ayrıca, bu teknolojilerin genişletilmesini ve uygulanmasını aktif olarak teşvik ediyoruz. .

Suphx Ar-Ge ekibi
Suphx teknolojisiyle ilgilenen öğrenciler, daha fazla ayrıntı için buradaki makaleyi okuyabilirler:
https://arxiv.org/abs/2003.13590
9 Nisan günü öğleden sonra, Microsoft Asya Araştırma Enstitüsü baş araştırmacısı Qin Tao ve Microsoft Süper Mahjong AI Suphx Ar-Ge ekibinin kıdemli araştırma mühendisi Li Junjie, B istasyonunun canlı yayın odasında makalenin teknik ayrıntılarını yorumladı.
