Statikten dinamiğe, son yıllarda kelime temsilinin gelişimi
Yazar | Xiaofan Yang
Düzenle | Kongun Sonu
Doğal dil işleme teknolojisinin tüm gelişim tarihi boyunca, en küçük anlamsal unsur olan "kelime" nin dijital olarak nasıl temsil edileceği her zaman bir araştırma noktası olmuştur.
Son yıllarda, büyük etiketlenmemiş metin verileri, yani kelime gömme ile eğitilmiş düşük boyutlu kelime temsil vektörleri, konuşma parçası etiketleme, sözdizimi analizi, adlandırılmış varlık tanıma, anlamsal rol etiketleme, makine çevirisi gibi birçok görevde gösterildi. etkililik. Ancak bu tür bir kelime gömme statiktir, çünkü eğitim süreci tamamlandığı sürece, artık yeni bağlamla değişmeyeceklerdir.
Statik kelime gömme yüksek verimliliğe sahip olmasına rağmen, statik doğası, çok anlamlılık sorunuyla uğraşmayı zorlaştırır, çünkü kelimenin anlamı bağlamına bağlıdır. Araştırmacılar, bu sorunu çözmek için, bağlama dayalı kelimelerin anlamlarını dinamik olarak öğrenmek için yakın zamanda birçok yöntem önerdiler.
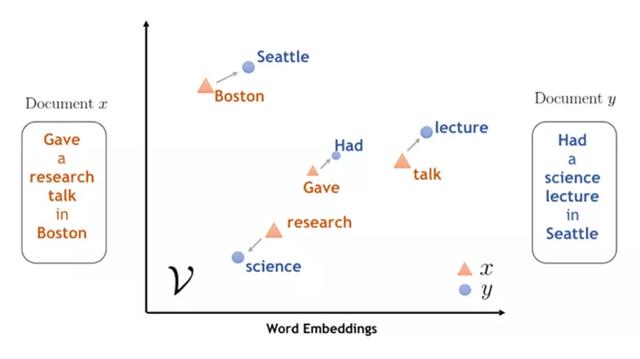
Örneğin, "Apple cep telefonu satıyor" ve "Ben bir elma yedim" cümlelerinde, statik kelime gömme iki "elma" arasındaki anlamsal farkı ayırt edemezken, dinamik kelime gömme bağlama göre farklı temsiller verebilir. Açıktır ki, önceden eğitilmiş bir dil modelinden çıkarılan böylesine dinamik bir kelime gömme, birçok doğal dil işleme görevinde önceki statik kelime gömme işleminden daha iyi performans gösterebilir.
Peki, kelime gömme statikten dinamiğe nasıl gelişir? Statüko nedir? Ve gelecekteki trendler neler?
Son zamanlarda, Harbin Teknoloji Enstitüsü Wang Yuxuan, Hou Yutai, Che Wanxiang, Liu Ting ve diğerleri, International Journal of Machine Learning and Cybernetics'de kelime yerleştirme üzerine bir inceleme makalesi yayınladılar. Bu soruyu cevapladı.

Dergi kaynak adresi: https://doi.org/10.1007/s13042-020-01069-8
İndirme adresini açın:
Bu inceleme yepyeni bir bakış açısıyla - statikten dinamiğe kelime yerleştirmenin gelişimi - kelime temsil modelinin kapsamlı bir incelemesi.İçeriği ayrıntılı ve koleksiyona değer.Vaka köşesinde herhangi bir zamanda başvurulabilecek bir materyaldir.
1. Statik karakterizasyon
Statik kelime temsilinin gelişimi kabaca iki aşamaya ayrılabilir.
İlk aşamada, seyrek ve yüksek boyutlu vektörler esas olarak kelimeleri temsil etmek için kullanılır. En klasik olanı tek sıcak (Tek ateşli) temsildir, her kelime yüksek boyutlu bir vektöre karşılık gelir, vektördeki bir bit "1" ve diğer bitler "0" dır. Bu tür kelime vektörlerinin tümü birbirine ortogonaldir ve farklı kelimeler arasındaki anlamsal mesafenin yakın olup olmadığını ölçmek doğal olarak imkansızdır. Bu tür bir gömülü sistemde veri seyrekliği ve yüksek boyutluluk sorunu vardır.Genellikle kelime vektörünün boyutu, sistemin kelime dağarcığı kadar büyüktür ve kullanımı zordur.
Bu sorunları çözmek için, ikinci aşamada insanlar, yüksek boyutlu vektörler yerine yoğun düşük boyutlu vektörleri eğitmek için büyük miktarda metin verisi kullanırlar. Aşağıda, bu aşamadaki bazı temsili kelime ifade yöntemleri verilmiştir:
Sinir ağı dil modeli. Dağıtılmış kelime vektörleri oluşturmak için derin sinir ağlarının kullanılması, ilk aşamada "veri seyrekliği" sorununu çözen yeni bir çağ yaratmıştır (yani, eğitim setinde bulunmayan kelime dizileri test setinde görünebilir). Modelin eğitim amacı, bir kelime dizisi verilen bir sonraki olası kelimeyi tahmin etmektir.
SİNAMEKİ. SENNA aynı zamanda sinir ağı tabanlı bir modeldir, ancak eğitim hedefi, bir metin parçasının kabul edilebilirliğini değerlendirmektir. Bu hedef, bir kelimenin olasılığını tahmin etmekten daha basit ve daha uygundur.
CBOW ve Skip-gram modeli. Yenilikçi tasarım ve basitleştirilmiş ağ mimarisinin ardından elde edilen CBOW ve Skip-gram modelinin hesaplama karmaşıklığı büyük ölçüde azaltılmış ve dağıtılmış temsil geliştirme tarihinde bir kilometre taşı haline gelmiştir. Tanınmış Word2Vec, CBOW ve Skip-gram'ın en popüler uygulamasıdır.
GloVe ve fastText. GloVe ve fastText, patlayarak ortaya çıkan kelime gömme modelinde büyük bir etki bıraktı. İlki daha küresel bilgi yakalar ve belirli kelimelerin ortak özelliklerini daha iyi kullanır; ikincisi, farklı kelimeler arasındaki yazım benzerliğini dikkate alır ve bir kez daha eğitim hızını büyük ölçüde artırır.
Yukarıda açıklanan bu düşük boyutlu yoğun dağılımlar NLP alanında büyük başarı göstermiş olsalar da, belirsizlik sorunu için biraz çaresizler. Açıkçası, bir kelime, bağlamla değişmeyecek olan bir prototip vektör ile temsil edilir.
Bu sorunu çözmenin sezgisel bir yolu, bir kelimeyi temsil etmek (farklı anlamları) için birden çok prototip vektörü kullanmaktır. Bu fikre dayanarak, Reisinger ve Mooney, kümeleme yoluyla her bir kelime için özel anlamlara sahip birden çok vektör üreten çok prototipli bir vektör uzay modeli önerdi. Bu çoklu prototip fikri, aynı zamanda duyu düzeyinde düğünlere de yaygın bir şekilde uygulanmıştır. Huang ve diğerleri, bu teknolojiyi SENNA mimarisinde kullandı ve iyi sonuçlar elde etti.
2. Dinamik karakterizasyon
Bir kelimenin belirsizliğini çözmenin başka bir yolu (ve muhtemelen daha etkili) dinamik temsilleri veya temsilleri bağlamla değişen "bağlam yerleştirmeleri" olarak adlandırılanları kullanmaktır.
CoVe. Bu, farklı bağlamsal içeriğe dayalı olarak farklı kelime temsilleri üretmeye yönelik ilk girişimdir. Sıradan diziye makine çevirisi görevlerinde derin bir LSTM kodlayıcı eğittiler ve daha sonra bunu bağlama göre değişen sözcük yerleştirmeleri oluşturmak için kullandılar ve ardından bu sözcük yerleştirmelerini aşağı akış görevlerine uyguladılar. Bu modelin tasarımı basit ve anlaşılırdır, ancak birçok görevde iyileştirmeler getirdi ve dinamik karakterizasyonun yolunu açtı.
ELMo. CoVe ile karşılaştırıldığında, ELMo eğitimi artık iki dilli veri gerektirmiyor ve neredeyse sınırsız etiketlenmemiş metni doğrudan kullanmasına izin veriyor. Aşağı akış görevlerindeki büyük başarısı, tüm NLP araştırma alanının da dikkatini çekti. Teknik bir bakış açısına göre, büyük ölçekli etiketlenmemiş bir külliyat üzerinde derin bir çift yönlü dil modeli eğitmek ve ardından iç katmanlarından temsilleri çıkarmak EMLo temsilidir.
ULMFit. ULMFit, LSTM'ye dayalı bir iyileştirme girişimidir. Teknik olarak öne çıkan özellikler, modelin ince ayar aşamasında hedef göreve daha iyi uyum sağlamasına yardımcı olabilecek ayırt edici ince ayar, eğimli üçgen öğrenme oranları ve kademeli çözülmedir. O sırada diğer modellere büyük bir avantajla liderlik etmek.
GPT. LSTM'nin öğrenme yeteneği nispeten sınırlıdır, bu nedenle LSTM kullanan ELMo ve ULMFit, uzun dizilerdeki bağımlılıkları iyi bir şekilde idare edemez. Dikkat temelli Transformer modeli önerildikten sonra, Transformer'ı çekirdek olarak kullanan GPT modeli mükemmel bir performans göstermiştir, bu da dil modeli ön eğitiminin ve bağlam temelli kelime temsilinin etkinliğini daha da kanıtlamaktadır.
BERT. Ayrıca Transformer'a dayalıdır ve soldan sağa ve sağdan sola önceden eğitilmiş modeli dikkate alır.BERT, şüphesiz 2019 boyunca en sık karşılaştırılan ve tartışılan modeldir. Sadece mükemmel performansı nedeniyle değil, aynı zamanda iki yeni denetimsiz eğitim öncesi görev, kelime maskeleme ve sonraki cümle tahmini önerdiğinden, daha sonraki araştırmacılara da çok ilham verdi. Ayrıca BERT'e dayalı çok sayıda geliştirilmiş model vardır.
XLNet. Bazı araştırmacılar, BERT'nin maskeleme yönteminin yeni eksiklikler getirdiğine inanıyor ve bazıları BERT'nin yetersiz eğitim problemine sahip olduğuna inanıyor (yeterince yakınsama değil). XLNet, eğitim öncesi süreçteki birçok ayrıntıyı yeniden tasarladı ve eğitim öncesi kelime yerleştirmenin performans kaydını bir kez daha yeniledi.

3. Değerlendirme yöntemleri ve veri setleri
Sözcük gömmenin mevcut değerlendirme göstergeleri, iç değerlendirme ve dış değerlendirme olmak üzere iki kategoriye ayrılmıştır.
İçsel değerlendirme, manuel değerlendirme temelinde kelimeler arasındaki sözdizimsel veya anlamsal ilişkiyi doğrudan değerlendirmektir. Farklı değerlendirme yöntemlerine göre, mutlak iç değerlendirme yöntemi ve karşılaştırmalı iç değerlendirme yöntemi olarak ikiye ayrılabilir. İlk kategoride, insan değerlendirmeleri önceden toplanır ve ardından yerleştirme yöntemleri için bir kıyaslama olarak kullanılır. Karşılaştırmalı iç değerlendirme yönteminde erişimci, belirli kelime ilişkisi görevlerine ilişkin sonuçlarına dayalı olarak kelime gömme kalitesini doğrudan değerlendirir. Mutlak dahili değerlendirmeler, karşılaştırmalı iç değerlendirmelerden daha yaygın olarak kullanılır çünkü test sırasında insan katılımını gerektirmezler. Daha popüler değerlendirme yöntemleri şunları içerir:

Dış değerlendirme, aşağı akış görevlerine girdi olarak sözcük yerleştirmelerini kullanır ve değişiklikleri ölçmek için bu görevler için belirli ölçütler kullanır. Kelime gömme hemen hemen tüm NLP görevlerine uygulanabilir olduğundan, teorik olarak tüm görevler dış değerlendirme olarak kabul edilebilir.
Dış değerlendirmede, örtük varsayım, kelime yerleştirmenin bir görevde iyi sonuçları olduğu ve aynı zamanda başka bir görevde olacağıdır. Ancak bu varsayım doğru değildir Deneysel sonuçlar, farklı NLP görevlerinin farklı kelime yerleştirmeleri için farklı tercihleri olduğunu göstermektedir. Bu nedenle, belirli bir göreve sözcük yerleştirmek için belirli bir dış değerlendirme yararlı olsa da, genel bir değerlendirme göstergesi olarak kabul edilemez.
4. Çapraz dil kelime yerleştirme
Dünyada yaklaşık 7000 farklı dil vardır, ancak yalnızca birkaç dil zengin insan açıklama kaynaklarına sahiptir. Bu, daha az kaynaklı dillere geçiş için eğitim nesneleri olarak kaynak bakımından zengin dillerin kullanılması ve giriş yerleştirmelerinin paylaşılan bir semantik alana yansıtılması için diller arası kelime gömme geçiş öğrenimini gerektirir. Bu tür gömme, diller arası kelime gömme olarak adlandırılır.
Farklı eğitim hedeflerine göre, çevrimiçi ve çevrimdışı olmak üzere ikiye ayrılabilir. Genel olarak, çevrimiçi yöntemler tek dilli ve diller arası hedefleri birlikte optimize ederken, çevrim dışı yöntemler girdi olarak farklı dillerin önceden eğitilmiş tek dilli kelime yerleştirmelerini alıp bunları paylaşılan anlamsal alana yansıtır.
Farklı tek dilli kelime gömme türlerine göre, diller arası gömme öğrenme yöntemleri statik gömme ve dinamik gömme olarak ikiye ayrılabilir.
Statik gömülü çevrimiçi yöntem genellikle kaynak dilin ve hedef dilin dil modellerini öğrenir ve diller arası hedefler aracılığıyla hedeflerini optimize eder. Çevrimdışı statik gömme yöntemi, kaynak dilin vektör uzayını hedef semantiğin vektör uzayına dönüştürmek için bir eşleme (çoğunlukla doğrusal bir geçiş matrisi) öğrenmektir.
Tek dilli dinamik kelime yerleştirmeden esinlenen bazı insanlar, son zamanlarda diller arası dinamik kelime yerleştirmeyi incelemeye başladılar. Çevrimiçi yöntemde, Mulcaire ve diğerleri, ELMo modeline dayalı çok dilli bir bağlamsal temsil modeli önermiş ve çok dilli verilerden karakter düzeyinde bilgi elde etmiştir. Lample ve Conneau, BERT hedefini benimsedi ve birden çok diller arası görevlerde en son sonuçları elde eden diller arası dil modellerini (XLM'ler) öğrenmek için paralel verilerden çapraz dil denetimi kullandı. Çevrimdışı yöntem için Mulcaire ve diğerleri, önceden eğitilmiş bağlam sözcüklerini gömmek ve hizalamak için doğrusal eşleme kullandı. Wang ve diğerleri, bu dönüşümü doğrudan anlamsal alanda öğrenmeyi önerdiler, böylece kelimenin anlamını koruyabilen bir diller arası dinamik yerleştirme elde ettiler.
Zengin kaynak dillerini haritalama kullanarak düşük kaynak dillerine yerleştirmeye ek olarak, aynı anda farklı dillerin yerleştirmelerini eğitmeyi de deneyebilirsiniz. Devlin ve arkadaşları, tek dilli Wikipedia külliyatında 104 dilden tek dilli bir modeli (Multi-BERT) önceden eğitti ve bu, sıfır vuruşlu çapraz dil modeli göçünde şaşırtıcı avantajlar gösterdi.
5. Özet
Dinamik kelime gömme çoğu NLP görevinde inanılmaz bir başarı elde etmiş olsa da, bu alanda hala keşfedilmeye değer birçok sorun var. Yazar, makalede kendi kendini denetleyen öğrenme, çok görevli öğrenme, çok modlu öğrenme, küçük örneklem öğrenme, dil oluşturma, yorumlanabilirlik, düşmanca saldırılar ve basitleştirilmiş eğitim süreci dahil olmak üzere 8 zorlu yönü tartışıyor. Burada tekrar etmeyeceğim ve ilgilenen okuyucular orijinal makaleyi okuyabilir.