ICLR 2020 | "Eşzamanlı Ortalama Öğretim" çerçevesi, denetimsiz öğrenim için daha sağlam sözde etiketler sağlar

Bu makale, Hong Kong Çince tarafından ICLR-2020'de yayınlanan ve daha pratik açık küme denetimsiz etki alanı uyarlama sorununu çözmeyi amaçlayan "Karşılıklı Ortalama Öğretim: Kişi Yeniden Tanımlamada Denetimsiz Alan Uyarlaması için Sözde Etiket Rafineri" başlıklı bir makaleyi tanıtmaktadır. Sözde açık küme, hedef etki alanında bulunan kategorilerin önceden bilinemeyeceği anlamına gelir. Bu çalışma, birden fazla yaya yeniden tanıma görevindeki etkinliğini doğrulamıştır ve doğruluk, denetlenen öğrenme performansına büyük ölçüde yaklaşan% 13-% 18 oranında en gelişmiş teknolojinin doğruluğundan önemli ölçüde daha yüksektir. Bu aynı zamanda ICLR'nin içerdiği yaya yeniden tanımlama görevleriyle ilgili ilk makale olup, kod ve model yayınlanmıştır.
Metin | Ge Yixiao
Editör | Jia Wei

Makaleye bağlantı: https://openreview.net/forum?id=rJlnOhVYPS
Kod bağlantısı: https://github.com/yxgeee/MMT
1. Arka plan tanıtımı
1.1. Görev
Person ReID (Person ReID), belirli yayaların görüntülerini kameralardan almayı amaçlar ve gözetim senaryolarında yaygın olarak kullanılır. Günümüzde, manuel açıklamalı birçok büyük ölçekli veri seti, bu görevin hızlı gelişimini teşvik etmiş ve aynı zamanda bu görev için doğrulukta niteliksel bir gelişme getirmiştir.
Bununla birlikte, pratik uygulamalarda, model büyük ölçekli bir veri seti üzerinde eğitilmiş olsa bile, doğrudan yeni bir izleme sistemine yerleştirilmişse, önemli alan farklılıkları genellikle doğrulukta önemli bir düşüşle sonuçlanır. Her bir izleme sisteminde veri toplama ve manuel etiketleme çok zaman alıcıdır ve zahmetlidir ve elde edilmesi zordur.
Bu nedenle, yukarıdaki sorunları çözmek için denetlenmemiş alan uyarlaması (Denetimsiz Alan Uyarlaması) görevi önerilmiştir, böylece etiketli kaynak alan (Kaynak Alan) üzerinde eğitilen model, elde etmek için etiketlenmemiş hedef alana (Hedef Alan) uyarlanabilir. Hedef alanda iyileştirilmiş alma doğruluğu. Genel denetimsiz etki alanı adaptasyon probleminden (hedef etki alanı ve kaynak etki alanı paylaşım kategorileri) farklı olarak, yaya yeniden tanımlama görevindeki hedef etki alanı kategorilerinin sayısının tahmin edilemez olduğunu ve genellikle kaynak etki alanıyla çakışmadığını belirtmek gerekir. Daha pratik ve zorlayıcı olan, açık küme, denetimsiz bir etki alanı uyarlamalı görevdir.
1.2 Motivasyon
Yayaların yeniden tanımlanmasında denetimsiz alan adaptasyonu için mevcut teknik çözümler, küme tabanlı sözde etiket yöntemi, etki alanı dönüştürme yöntemi, görüntü veya özellik benzerliğine dayalı sözde etiket yöntemi olarak ikiye ayrılır; bunlar arasında küme tabanlı sözde etiket yöntemi bulunur. Daha etkili olduğu ve en gelişmiş doğruluğu koruduğu kanıtlanmıştır, bu nedenle bu makale esas olarak bu tür yönteme odaklanmaktadır. Adından da anlaşılacağı gibi küme tabanlı sözde etiket yöntemi,
(i) İlk olarak, sözde etiketler oluşturmak üzere etiketlenmemiş hedef etki alanı görüntü özelliklerini kümelemek için bir kümeleme algoritması (K-Ortalamaları, DBSCAN, vb.) kullanın.
(ii) Sözde etiket, hedef alandaki ağın öğrenimini denetlemek için kullanılır. Yukarıdaki iki adım, aşağıdaki şekilde gösterildiği gibi yakınsamaya kadar döngü yapar:
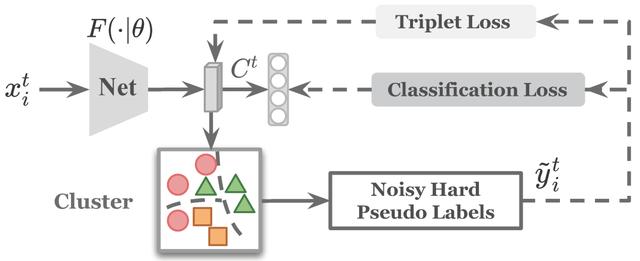
Bu tür bir yöntem, modelin optimizasyonu ile birlikte sözde etiketlerin kalitesini bir dereceye kadar iyileştirebilse de, modelin eğitimi genellikle kaçınılmaz sözde etiket gürültüsü tarafından engellenir ve ilk sözde etiket gürültüsü büyük olduğunda, model daha büyüktür. Çökme riski. Sözde etiket gürültüsü, esas olarak, hedef alanda önceden eğitilmiş kaynak etki alanı ağının sınırlı ifade gücünden, hedef etki alanı kategorilerinin bilinmeyen sayısından ve kümeleme algoritmasının kendisinin sınırlamalarından gelir. Bu nedenle, sözde etiket gürültüsü ile nasıl başa çıkılacağı ağın nihai performansı üzerinde çok önemli bir etkiye sahiptir, ancak mevcut çözümler bunu etkili bir şekilde çözememiştir.
2. Çözüm
2.1. Genel Bakış
Kümeleme tabanlı algoritmalarda sözde etiket paraziti sorununu etkili bir şekilde çözmek için, bu makale sözde etiketleri optimize etmek için "senkronize ortalama öğretme" çerçevesinin kullanılmasını önerir. Temel fikir, çevrimiçi sözde etiketleri gerçekleştirmek için daha sağlam "yumuşak" etiketler kullanmaktır. optimizasyon. Burada, "sert" etiketler, yaygın olarak kullanılan tek özellikli etiketler gibi% 100 güvenle, "yumuşak" etiketler ise güven anlamına gelir. < Gibi% 100 etiketler.

Yukarıdaki şekilde gösterildiği gibi, A1 ve A2 aynı kategoriye aittir ve benzer görünümdeki B aslında başka bir kategoridir.Pozların çeşitliliği nedeniyle, kümeleme algoritması tarafından oluşturulan sözde etiketler yanlışlıkla A1 ve B'yi bir kategoriye sınıflandırır ve A1 ve A2 Farklı kategorilere bölündüğünde, eğitim için yanlış sözde etiketlerin kullanılması hatanın büyümeye devam etmesine neden olacaktır. Makale, ağın veri dağıtımını öğrenme ve yakalama yeteneğine sahip olması nedeniyle, ağın çıktısının etkin bir denetim olarak kullanılabileceğine dikkat çekti. Bununla birlikte, ağın çıktısının kendini eğitmek için kullanılması tavsiye edilmez ve bu kaçınılmaz olarak hataların artmasına neden olur. Bu nedenle, bu makale, ağın kendi çıktı hatasını aşırı uydurmaktan kaçınmak için, işbirlikli eğitim altında karşılıklı denetimin etkisini elde etmek için simetrik bir ağı eşzamanlı olarak eğitmeyi önermektedir. Gerçek işlemde, bu makale denetlemek için "ortalama modeli" kullanır ve aşağıda açıklanacak olan daha güvenilir ve kararlı "yumuşak" etiketler sağlar. Genel olarak makale
- Önerilen "Eşzamanlı Ortalama Öğretim" ( M mutlak M ean- T Her biri) Çerçeve, denetimsiz etki alanı uyarlamalı görevler için daha güvenilir ve sağlam sözde etiketler sağlar;
- İşbirliğine dayalı eğitimin çerçevesini desteklemek üzere Triplet için makul sözde etiketler ve eşleşen kayıp işlevleri tasarlayın.
2.2. Eşzamanlı ortalama öğretim

Yukarıdaki şekilde gösterildiği gibi, bu makalede önerilen "senkronize ortalama öğretim" çerçevesi, ortak eğitim için çevrimdışı optimize edilmiş "sert" sözde etiketleri ve çevrimiçi olarak optimize edilmiş "yumuşak" sözde etiketleri kullanır. "Sabit" sözde etiketler kümeleme ile oluşturulur ve her eğitim döneminden önce ayrı ayrı güncellenir; "yumuşak" sözde etiketler, ortak eğitimli bir ağ tarafından oluşturulur ve ağ güncellendiğinde çevrimiçi olarak optimize edilir. Sezgisel olarak konuşursak, çerçeve sözde etiketlerdeki gürültüyü azaltmak için Eş Ağların çıktısını kullanır ve birbirini optimize etmek için çıktıların tamamlayıcılığını kullanır. Bu tamamlayıcılığı artırmak için temel olarak aşağıdaki önlemler alınmaktadır:
- İki ağ Net 1 ve Net 2 için farklı başlatma parametreleri kullanın;
- Rasgele farklı girişimler oluşturun, örneğin, iki ağa görüntü girişi için rasgele kırpma, rasgele çevirme, rasgele silme vb. Gibi farklı rasgele geliştirme yöntemleri kullanın ve iki ağın çıktı özellikleri için rasgele bırakma kullanın;
- Ağ 1 ve Ağ 2'yi eğitirken, farklı "yumuşak" denetim kullanılır, yani "yumuşak" etiket, diğer tarafın ağının "ortalama modelinden" gelir;
- Karşılıklı denetim için mevcut ağın kendisi Net 1/2 yerine ağın "ortalama modeli" Mean-Net 1/2 kullanın.
Burada, "ortalama model" parametreleri, karşılık gelen ağ parametrelerinin kümülatif ortalamalarıdır Spesifik olarak, "ortalama modelin" parametreleri, kayıp fonksiyonunun geri yayılmasıyla güncellenmez, ancak kayıp fonksiyonu her tersine çevrildiğinde güncellenir. Yönlendirdikten sonra, karşılık gelen ağ parametrelerinin ağırlıklı ortalamasını almak için aşağıdaki formülü kullanın:

Burada, sırasıyla Net 1 ve Net 2'nin ilk yinelemesini ve mevcut parametrelerini ifade eder. Başlatma sırasında. Bu nedenle, "ortalama model", ağın geçmiş parametrelerinin ortalamasını alıyor olarak kabul edilebilir İki "ortalama model", zaman birikimi nedeniyle daha bağımsız ve tamamlayıcıdır. Basit bir işbirliğine dayalı öğrenme şeması, buradaki "ortalama modeli" kaldırmak ve Ağ 2'yi denetlemek için Ağ 1'in çıktısını kullanmak gibi simetrik ağı denetlemek için ağın çıktısını doğrudan kullanmaktır. Böyle bir planın iki dezavantajı vardır. (1) Ağın kendisi daha hızlı güncellenmek için geri yayılım parametrelerine dayandığından ve gürültüden daha ciddi şekilde etkilendiğinden, bu tür dengesiz denetimin kullanımı ağın öğrenimini etkileyebilir. Ablasyon öğrenmede bir karşılaştırma yapılır. (2) Bu basitleştirilmiş şema, ağın birbirine yaklaşması için doğrudan eğitilmesine izin verir, bu da ağın hızlı bir şekilde benzerliğe yakınlaşmasına ve çıktının tamamlayıcılığını azaltmasına neden olur.Bu, makalenin Ek A.1'inde ayrıntılı olarak açıklanmıştır. "Ortalama model" geri yayılma gerçekleştirmediğinden, gradyanı hesaplamaya ve depolamaya gerek olmadığı ve video belleğini ve hesaplama karmaşıklığını büyük ölçekte artırmayacağı belirtilmelidir. Testte, akıl yürütme için ağlardan yalnızca biri kullanılır ve temel ile karşılaştırıldığında, testin hesaplama karmaşıklığını artırmayacaktır.
Yaya yeniden tanıma görevlerinde, sınıflandırma kaybı ve üçlü kayıp genellikle daha iyi doğruluk elde etmek için ortak eğitim için kullanılır. Sınıflandırma kaybı, sınıflandırıcının tahmin edilen değerine etki eder ve üçlü kayıp doğrudan görüntü özelliklerine etki eder. Görüntülemeyi kolaylaştırmak için aşağıda referans kodlayıcı ve sınıflandırıcı kullanıyoruz.Her Ağ bir kodlayıcı ve sınıflandırıcıdan oluşuyor.Net 1 ve Net 2'yi ayırt etmek için üst simgeler kullanıyoruz. Kaynak alanı hedef alandan ayırmak için köşe etiketleri kullanıyoruz Kaynak alan görüntüsü ve etiketi olarak temsil edilir ve hedef alan etiketlenmemiş görüntü olarak temsil edilir.
2.3 "Yumuşak" sınıflandırma kaybı
Denetim için "sert" sözde etiketler kullanıldığında, sınıflandırma kaybı genel bir çok sınıflı çapraz entropi kaybı işlevi ile temsil edilebilir:

Yukarıdaki formülde, kümeleme ile oluşturulan hedef etki alanı görüntüsünün "sert" sözde etiketidir. "Senkronize ortalama öğretim" çerçevesinde, "yumuşak" sınıflandırma kaybındaki "yumuşak" sözde etiket, "ortalama model" Ortalama-Net 1 / 2'nin sınıflandırma tahmin değeridir. Sınıflandırma tahmini için, iki dağılım arasındaki mesafeyi azaltmak için model damıtmada yaygın olarak kullanılan denetim için "yumuşak" bir çapraz entropi kaybı işlevi kullanmayı düşünmek kolaydır:


Yukarıdaki formüldeki nötr, aynı görüntünün farklı rastgele veri geliştirme yöntemlerinden geçtiği anlamına gelir. Bu formül, Net 1'in sınıflandırma tahmin değerinin Ortalama-Net 2 sınıflandırma tahmin değerine yaklaşmasını ve Net 2 yaklaşımının sınıflandırma tahmin değerinin Ortalama-Net 1 sınıflandırma tahmin değerine dönüştürülmesini amaçlamaktadır.
2.4, "yumuşak" üçlü kayıp
Geleneksel üçlü (çapa, pozitif, negatif) kayıp fonksiyonu şu şekilde ifade edilir:

Yukarıdaki formül Öklid mesafesini temsil eder ve sırasıyla alt simgeler ve pozitif örnekler ve negatif örnekler, marj süperparametreleridir. Burada, pozitif ve negatif örnekler, kümeleme tarafından oluşturulan sözde etiketlerle değerlendirilir, bu nedenle bu formül "sert" sözde etiketlerin eğitimini desteklemek için kullanılabilir. Ancak, yumuşak etiketlerin eğitimini desteklemek yeterli değildir ve üçlü çıkarma kaybı, sezgisel olarak yumuşak etiketler sağlayamaz. buraya zorluk Bu mu Üçlünün görüntü özelliklerine dayalı olarak makul bir "yumuşak" sözde etiketin nasıl tasarlanacağı ve karşılık gelen "yumuşak" üçlü kayıp işlevinin nasıl tasarlanacağı . Bu makale, aşağıdaki gibi ifade edilen bir üçlü içindeki özellikler arasındaki ilişkiyi temsil etmek için softmax-triplet kullanmayı önermektedir:

Buradaki softmax-triplet değer aralığı