Düşük güçlü bilgisayarla görme teknolojisinin sınırı, dört ana yön, daha küçük, daha hızlı ve daha verimli arayış

Yazar | Jia Wei
Düzenle | Kongun Sonu
Derin öğrenme, hedef tespiti ve sınıflandırma gibi bilgisayarla görme görevlerinde yaygın olarak kullanılmaktadır. Ancak bu uygulamalar genellikle çok fazla hesaplama ve enerji tüketimi gerektirir. Örneğin, bir resim sınıflandırmasını işlemek için VGG-16'nın 15 milyar hesaplama yapması gerekirken, YOLOv3'ün 39 milyar hesaplama yapması gerekir.
Bu, düşük güçlü gömülü sistemlerde veya mobil cihazlarda derin öğrenmenin nasıl dağıtılacağı sorusunu gündeme getirir. Çözümlerden biri, bilgi işlem görevini bulut tarafına aktarmaktır, ancak bu sonuçta sorunu çözmez, çünkü drone'larda konuşlandırılanlar gibi (genellikle bağlantı kesilmesi durumunda çalışan) birçok derin öğrenme uygulamasının uç tarafta hesaplanması gerekir. Veya uydulardaki uygulamalar.
2016'dan bu yana, endüstri model hızlandırma ve minyatürleştirme üzerine araştırmaları keşfetmeye başladı ve ayrıca çok sayıda minyatürleştirme çözümü önerdi. Bu teknolojiler, kayıpsız doğruluğu sağlarken DNN'lerdeki fazlalığı ortadan kaldırabilir, hesaplama miktarını% 75'ten fazla azaltabilir ve çıkarım süresini% 50'den fazla azaltabilir. Ancak DNN modellerini uç tarafta büyük ölçekte dağıtmak istiyorsanız, yine de optimize etmeye devam etmeniz gerekir.
İlerlemek istiyorsanız, yine de düşük güçlü bilgisayar görüşü araştırma ilerlemesinin mevcut durumuna bakmanız gerekir. Purdue Üniversitesi'nden Abhinav Goel ve diğerleri, yakın zamanda bu alandaki araştırma ilerlemesi üzerine referans almaya değer bir inceleme yaptılar.

Makaleye bağlantı: https://arxiv.org/pdf/2003.11066
Bu makalede Goel ve diğerleri, düşük güçlü çıkarım yöntemlerini dört kategoriye ayırmaktadır:
1. Parametre niceleme ve budama: DNN model parametrelerini depolamak için kullanılan bit sayısını azaltarak belleği ve hesaplama maliyetini azaltın.
2. Sıkıştırma evrişim filtresi ve matris ayrıştırma: Bellek gereksinimlerini ve fazlalık matris işlemlerinin sayısını azaltmak için büyük DNN katmanını daha küçük katmanlara ayırın.
3. Ağ mimarisi araması: Beklenen performansa sahip DNN mimarilerini bulmak için farklı düzeylerde kombinasyonlarla otomatik olarak DNN'ler oluşturun.
4. Bilgi aktarımı ve damıtma: Hesaplama açısından daha yoğun bir DNN'nin çıktısını, özelliklerini ve etkinleştirmesini taklit etmek için kompakt bir DNN eğitin.
Bu dört yöntemin tanıtımı ve avantajları ve dezavantajları aşağıdaki şekilde özetlenmiştir:

Bu yöntemlerin avantajlarını ve dezavantajlarını özetlemeye ek olarak, Goel ve diğerleri tarafından yapılan bu inceleme ayrıca bazı olası iyileştirme önlemleri önerdi.Çalışanlar ayrıca gelecekteki araştırmalara rehberlik edecek bir dizi değerlendirme göstergesi önerdi.
1. Parametre ölçümü ve budama
Bellek erişiminin DNN'lerin enerji tüketimi üzerinde önemli bir etkisi vardır. Düşük güçlü DNN'ler oluşturmak için bir strateji, performansı ve bellek erişim sürelerini dengelemektir. Bu strateji için şu anda iki yöntem vardır, biri parametreleri ölçmek, yani DNN parametrelerinin boyutunu küçültmek, diğeri ise budama, önemsiz parametreleri ve bağlantıları DNN'lerden kaldırmaktır.
1. Parametre niceleme
Çalışmalar (Courbariaux ve ark.), Farklı bit genişliklerine sahip sabit nokta formatlarında depolanan parametrelerle eğitilmeyi göstermiştir, test hatası biraz artmasına rağmen (bu hatanın değişimi neredeyse ihmal edilebilir), parametrelerin bit genişliği azalmaktadır, ancak Enerji tüketimi büyük ölçüde azaltılabilir. Aşağıda gösterildiği gibi:

Bu temelli araştırmaya dayanarak, verilen doğruluk kısıtlamaları altında DNN parametreleri için en iyi bit genişliğini bulmaya çalışan çok sayıda çalışma (LightNN, CompactNet, FLightNN, vb.) Ortaya çıktı. Courbariaux, Rastegari ve diğerleri bile ikili bir sinir ağı önerdiler.
DNN'lerin bellek gereksinimlerini daha da azaltmak için, genellikle parametre niceleme ve model sıkıştırmasının bir kombinasyonu kullanılır. Örneğin, Han ve arkadaşları ilk önce parametreleri ayrı kutulara nicemledi ve ardından bu kutuları sıkıştırmak için Huffman kodlamasını kullandı, böylece model boyutunu% 89 düşürürken, doğruluk temelde etkilenmedi. Benzer şekilde, HashedNet, DNN bağlantılarını hash gruplarına nicelendirir, böylece aynı pakete hashing uygulanmış bağlantılar aynı parametreleri paylaşır. Ancak bu yöntem yüksek bir eğitim maliyeti gerektirdiğinden uygulamaları sınırlıdır.
avantaj: Parametrenin bit genişliği azaldığında, DNN'lerin performansı temelde değişmeden kalır. Bunun başlıca nedeni, kısıtlama parametrelerinin eğitim süreci sırasında bir düzenlilik etkisine sahip olmasıdır.
Dezavantajlar ve iyileştirme talimatları: 1) Niceleme teknolojisini kullanan DNN'lerin genellikle birçok kez yeniden eğitilmesi gerekir, bu da eğitim enerjisini yoğun hale getirir, bu nedenle eğitim maliyetlerinin nasıl azaltılacağı dikkate alınması gereken bir teknolojidir; 2) DNN'lerdeki farklı katmanların özelliklere duyarlılığı Farklı, eğer tüm katmanların bit genişliği aynı ise, bu zayıf performansa yol açacaktır.Bu nedenle, her bağlantı katmanı için farklı hassasiyet parametrelerinin nasıl seçileceği, eğitim süreci sırasında öğrenilebilecek performansı iyileştirmek için önemli bir adımdır.
2. Budama
Önemsiz parametreleri ve bağlantıları DNN'lerden kaldırmak, bellek erişimlerinin sayısını azaltabilir.
Hessen ağırlıklı distorsiyon ölçüm yöntemi, bu fazlalık parametreleri kaldırmak ve DNN modelinin boyutunu azaltmak için DNN'deki parametrelerin önemini değerlendirebilir, ancak bu ölçüm tabanlı budama yöntemi yalnızca herkes için uygundur. Bağlantı katmanı.
Budamayı evrişimli katmana genişletmek için birçok bilim insanı sihrini göstermiştir. Anwar ve diğerleri, bir partikül filtreleme yöntemi önerdi; Polyak ve diğerleri, verilere örnekler girdi ve seyrek olarak etkinleştirilen bağlantıları kesip çıkardı; Han ve diğerleri, DNN'deki parametreleri ve bağlantıları öğrenmek için yeni bir kayıp işlevi kullanır; Yu ve diğerleri, kullanır. Çıktıya göre her parametrenin önemini ölçmek için önem puanlarını yayan bir algoritma.
Diğerleri modele aynı anda budama, nicemleme ve sıkıştırma uygulamaya çalışarak model boyutunu% 95 oranında azalttı.
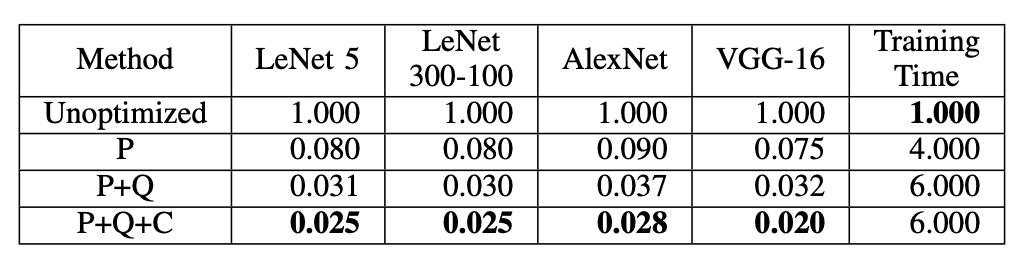
Çizim: Farklı DNN modellerinin sıkıştırma oranı. Burada P: Budama, Q: Niceleme, C: Sıkıştırma.
avantaj: Yukarıdaki tabloda gösterildiği gibi, daha önemli performans kazanımları elde etmek için budama, niceleme ve kodlama ile birleştirilebilir. Örneğin, üçü birlikte kullanıldığında, VGG-16'nın boyutu orijinal boyutun% 2'sine düşürülebilir. Ek olarak, budama DNN modelinin karmaşıklığını azaltabilir ve böylece aşırı uydurmayı azaltabilir.
Dezavantajlar ve iyileştirme talimatları: Benzer şekilde, budama da eğitim süresini artıracaktır. Yukarıdaki tabloda gösterildiği gibi, budama ve nicemlemeyi aynı anda kullanmak eğitim süresini% 600 artırır; DNN seyrek kısıtlamalar kullanılarak budanırsa bu sorun daha ciddi hale gelecektir. Ek olarak, budamanın avantajları yalnızca seyrek matrisler için özel donanım veya özel veri yapıları kullanıldığında ortaya çıkacaktır. Bu nedenle, mevcut bağlantı budama teknolojisi ile karşılaştırıldığında, Kanal düzeyinde budama, herhangi bir özel veri yapısı gerektirmediğinden ve matris seyrekliği üretmediğinden bir iyileştirme yönü olabilir.
İki, sıkıştırılmış evrişim filtresi ve matris ayrıştırma
Evrişim işlemleri DNN'lerin büyük bir bölümünü oluşturur.AlexNet'i örnek olarak alırsak, tam bağlı katman parametrelerin yaklaşık% 89'unu oluşturur. Bu nedenle, DNN'lerin güç tüketimini azaltmak istiyorsanız, evrişimli katmanın hesaplama miktarını ve tamamen bağlı katmanın parametre miktarını azaltmalısınız. Bunun aynı zamanda iki teknik yönü vardır: 1) daha küçük bir evrişim filtresi kullanmak; 2) matrisi daha küçük parametrelere sahip bir matrise ayırmak.
1. Sıkıştırma evrişim filtresi
Daha büyük bir filtre ile karşılaştırıldığında, daha küçük bir evrişim filtresi daha az parametreye ve daha düşük hesaplama maliyetine sahiptir.
Ancak tüm büyük evrişimli katmanlar değiştirilirse, DNN'nin çevirisini ve deformasyonunu etkileyecek ve bu da DNN modelinin doğruluğunu azaltacaktır. Bu yüzden bazı insanlar bu fazlalık filtreleri belirlemeye ve onları daha küçük filtrelerle değiştirmeye çalışıyor. SqueezeNet tam da böyle bir teknolojidir, 3 × 3 evrişimi 1 × 1 evrişime dönüştürmek için üç strateji kullanır.

Yukarıdaki şekilde gösterildiği gibi, AlexNet ile karşılaştırıldığında, SqueezeNet parametreleri% 98 oranında azaltır (tabii ki işlenenlerin sayısı biraz artar), ancak performans etkilenmez.
MobileNets, hesaplamaları, gecikmeleri ve parametreleri azaltmak için darboğaz katmanlarında derin ayrılabilir konvolüsyonlar kullanır. Epthwise ayrılabilir kıvrımlar kullanılırken, özellik boyutu küçük tutulur ve daha yüksek doğruluk elde etmek için yalnızca daha büyük bir özellik alanına genişletilir.
avantaj: Darboğaz evrişim filtresi, DNN'lerin bellek ve gecikme gereksinimlerini büyük ölçüde azaltır. Çoğu bilgisayarla görme görevi için, bu yöntemler SOTA performansı sağlayabilir. Filtreleme ve sıkıştırma, budama ve niceleme tekniklerine ortogonaldir (birbirini etkilemez), bu nedenle bu üç teknik, enerji tüketimini daha da azaltmak için birlikte kullanılabilir.
Dezavantajlar ve iyileştirme talimatları: 1 × 1 evrişimin küçük bir DNN'de hesaplama açısından çok pahalı olduğu ve düşük doğruluk ile sonuçlandığı kanıtlanmıştır.Bunun başlıca nedeni, hesaplama yoğunluğunun donanımı etkin bir şekilde kullanmak için çok düşük olmasıdır. Belleği etkin bir şekilde yöneterek, derinlemesine ayrılabilir evrişimin hesaplama yoğunluğu geliştirilebilir; önbellekteki parametrelerin alan ve zaman yerelliğini optimize ederek, bellek erişimlerinin sayısı azaltılabilir.
2. Matris ayrışımı
Tensör veya matrisin toplam-çarpım formuna ayrıştırılmasıyla, çok boyutlu tensör daha küçük matrislere ayrıştırılır ve böylece fazlalık hesaplamaları ortadan kaldırılır. Bazı çarpanlara ayırma yöntemleri DNN modelini 4 kattan fazla hızlandırabilir çünkü matrisi daha yoğun bir parametre matrisine ayrıştırabilir ve yapılandırılmamış seyrek çarpımın yerellik sorununu önleyebilir.

Doğruluk kaybını en aza indirmek için, matris ayrıştırması katman bazında gerçekleştirilebilir: önce bir katmanın parametrelerini çarpanlara ayırın ve ardından sonraki katmanları yeniden yapılandırma hatasına göre çarpanlara ayırın. Bununla birlikte, katman katman optimizasyon yöntemi, bu yöntemlerin büyük ölçekli DNN modellerine uygulanmasını zorlaştırır, çünkü ayrıştırılmış hiperparametrelerin sayısı modelin derinliği ile katlanarak artar. Wen ve diğerleri, faktörlü süperparametrelerin sayısını azaltmak için kompakt bir çekirdek şekli ve derinlik yapısı kullandı.
Matris ayrıştırması için birçok teknik vardır. Kolda ve arkadaşları, çarpanlara ayırma tekniğinin çoğunun DNN modellerini hızlandırmak için kullanılabileceğini kanıtladı, ancak bu teknikler, doğruluk ve hesaplama karmaşıklığı arasındaki en iyi dengeyi sağlayamayabilir. Örneğin, CPD (Tipik Yakınsama ve Ayrıştırma) ve BMD (Toplu Normalleştirme Ayrıştırma) doğrulukta çok iyi sonuçlar verebilir, ancak Tucker-2 ayrıştırmasının ve tekil değer ayrıştırmasının doğruluğu o kadar iyi değildir. CPD, sıkıştırmada BMD'den daha iyidir, ancak CPD ile ilgili optimizasyon problemleri bazen çözülemezdir ve bu da ayrıştırılamamasına yol açar, ancak KMY'nin çarpanlara ayrılması her zaman mevcuttur.
avantaj: Matris ayrıştırma, DNN'nin hesaplama maliyetini düşürebilir ve aynı çarpanlara ayırma hem evrişimli katmanda hem de tam bağlantılı katmanda kullanılabilir.
Dezavantajlar ve iyileştirme talimatları: Teorik açıklama eksikliğinden dolayı, neden bazı ayrıştırmaların (CPD, BMD gibi) daha yüksek doğruluk elde ederken diğerlerinin başaramadığını açıklamak zordur.Ayrıca, matris ayrıştırmasıyla ilgili hesaplamalar genellikle model tarafından elde edilen performans kazanımlarına eşdeğerdir ve bu da fayda sağlar Kayıpla dengeleme. Ek olarak, matris ayrıştırmanın büyük ölçekli DNN modellerinde uygulanması zordur, çünkü derinlik arttıkça süper parametrelerin ayrışması katlanarak artar ve eğitim süresi esas olarak doğru ayrıştırma süper parametrelerini bulmak için harcanır; aslında, süper parametrelerin tüm uzaydan gerçekleştirilmesi gerekmez. Arama, böylece eğitim sırasında büyük DNN modellerinin eğitimini hızlandırmak için daha iyi bir arama alanını nasıl bulacağınızı öğrenebilirsiniz.
Üç, ağ mimarisi araması
Düşük güçlü bilgisayarla görme programları tasarlarken, farklı görevler için farklı DNN modeli mimarileri gerekli olabilir. Bununla birlikte, birçok yapısal olasılık nedeniyle, optimal bir DNN modelini elle tasarlamak genellikle zordur. En iyi yol, bu süreci, yani Ağ Mimarisi Aramasını otomatik hale getirmektir.

NAS, denetleyici olarak tekrarlayan bir sinir ağı (RNN) kullanır ve aday DNN mimarileri oluşturmak için pekiştirmeli öğrenmeyi kullanır. Bu aday DNN mimarilerini eğitin ve ardından test için doğrulama setini kullanın ve test sonuçları, kontrolörün bir sonraki aday mimarisini optimize etmek için bir ödül işlevi olarak kullanılır.
NASNet ve AmoebaNet, NAS'ın etkinliğini kanıtlar, mimari arama yoluyla DNN modelleri elde ederek SOTA performansı elde edebilirler.
Mobil cihazlar için etkili bir DNN modeli elde etmek için, Tan ve diğerleri, kontrolörde çok amaçlı bir ödül fonksiyonu kullanan MNasNet'i önerdi. Deneyde MNasNet, NASNet'ten 2,3 kat daha hızlıdır, parametreler 4,8 kat azaltılır ve işlem 10 kat azaltılır. Ayrıca MNasNet, NASNet'ten daha doğrudur.
Bununla birlikte, NAS yönteminin dikkat çekici etkisine rağmen, NAS algoritmalarının çoğu hesaplama açısından çok pahalıdır. Örneğin, MNasNet, ImageNet veri kümesinde verimli bir DNN mimarisi bulmak için 50.000 GPU'ya ihtiyaç duyar.
NAS ile ilişkili hesaplama maliyetini düşürmek için, bazı araştırmacılar aracı görevlerine ve ödüllerine göre aday mimarileri aramayı öneriyor. Örneğin, yukarıdaki örnekte, ImageNet'i seçmiyoruz, ancak daha küçük bir CIFAR-10 veri seti kullanıyoruz. FBNet bu şekilde işlenir ve hızı MNasNet'in 420 katıdır.
Bununla birlikte, Cai ve arkadaşları, proxy görevleri için optimize edilmiş DNN mimarisinin hedef görev için en uygun olduğunu garanti edemediğini gösterdi.Vekil tabanlı NAS çözümlerinin sınırlamalarının üstesinden gelmek için Proxyless-NAS'ı önerdiler. Yöntem, aday mimarilerin sayısını azaltmak için yol düzeyinde budama kullanır ve gecikme gibi hedeflerle başa çıkmak için gradyan tabanlı bir yöntem kullanır. 300 GPU saat içinde etkili bir mimari buldular. Ek olarak, tek yollu NAS (Tek Yollu NAS) adı verilen bir yöntem, mimari arama süresini 4 GPU saati içinde sıkıştırabilir, ancak bu hızlanma, düşük doğruluk maliyetiyle gelir.
avantaj: NAS, herhangi bir manuel müdahale olmaksızın olası tüm mimari alanlarda arama yaparak doğruluk, bellek ve gecikme arasındaki ödünleşmeleri otomatik olarak dengeler. NAS, birçok mobil cihazda en iyi doğruluk ve enerji tüketimi performansını elde edebilir.
Dezavantajlar ve iyileştirme talimatları: Hesaplama miktarı çok fazla, bu da büyük veri kümelerinde görevlerin yapısını aramayı zorlaştırıyor. Ek olarak, performans gereksinimlerini karşılayan bir mimari bulmak için, her bir aday mimarinin eğitilmesi ve hedef cihazda çalıştırılması ve daha yüksek hesaplama maliyetlerine yol açacak bir ödül işlevi oluşturması gerekir. Aslında, aday DNN'ler, verilerin farklı alt kümeleri üzerinde paralel olarak eğitilebilir, böylece eğitim süresini kısaltır; farklı veri alt kümelerinden elde edilen gradyanlar, eğitimli bir DNN'de birleştirilebilir. Ancak, bu paralel eğitim yöntemi daha düşük doğrulukla sonuçlanabilir. Öte yandan, yüksek bir yakınsama oranını korurken, uyarlanabilir bir öğrenme oranının kullanılması doğruluğu artırabilir.
4. Bilgi aktarımı ve damıtma
Büyük modeller, küçük modellerden daha doğrudur, çünkü ne kadar fazla parametre olursa, öğrenmeye izin veren işlev o kadar karmaşıktır. Küçük bir modelle böylesine karmaşık bir işlevi öğrenebilir misiniz?
Bunun bir yolu, büyük bir DNN modelinden elde edilen bilgiyi küçük bir DNN modeline aktaran Bilgi Aktarımıdır. Karmaşık fonksiyonları öğrenmek için, küçük DNN modeli, büyük DNN modeli ile işaretlenen veriler üzerinde eğitilecektir. Bunun arkasındaki fikir, büyük bir DNN ile işaretlenen verilerin küçük bir DNN için yararlı birçok bilgi içermesidir. Örneğin, büyük bir DNN modeli, bir girdi görüntüsü için bazı sınıf etiketlerinde orta-yüksek bir olasılık çıkarır, bu durumda bu, bu sınıfların bazı ortak görsel özellikleri paylaştığı anlamına gelebilir; küçük bir DNN modeli için, bu olasılıklar simüle edilirse, doğrudan verilerden Çin'de öğrenmek için daha fazlasını öğrenebilmelisiniz

Diğer bir teknik, 2014 yılında Peder Hinton tarafından önerilen Bilgi Damıtmasıdır. Bu yöntemin eğitim süreci, bilgi aktarımından çok daha basittir. Bilgi damıtmada, küçük DNN modeli, öğrenci-öğretmen modeli kullanılarak eğitilir.Küçük DNN modeli öğrencidir ve bir grup özel DNN modeli öğretmendir; öğrencileri eğiterek, küçük DNN modeli öğretmenin çıktısını taklit edebilir. Genel görevi tamamlayın. Bununla birlikte, Hinton'un çalışmasında, küçük DNN modelinin doğruluğu buna göre azalmıştır. Li ve diğerleri, küçük DNN modelinin doğruluğunu daha da iyileştirmek için öğretmen ve öğrenci arasındaki özellik vektörünün Öklid mesafesini en aza indirmek için kullanılır. Benzer şekilde FitNet, öğrenci modelindeki her katmanın öğretmenin özellik haritasını taklit etmesine izin verir. Bununla birlikte, yukarıdaki iki yöntem, öğrenci modelinin yapısı hakkında katı varsayımlar gerektirir ve genellemeleri zayıftır. Bu sorunu çözmek için Peng ve arkadaşları, göstergeler arasındaki korelasyonu bir optimizasyon problemi olarak kullandı.
avantaj: Bilgi aktarımına ve bilgi damıtmasına dayalı teknoloji, büyük ölçekli eğitim öncesi modellerin hesaplama maliyetini önemli ölçüde azaltabilir. Araştırmalar, bilgi damıtma yönteminin yalnızca bilgisayarla görmede değil, yarı denetimli öğrenme ve alan uyarlaması gibi birçok görevde de kullanılabileceğini göstermiştir.
Dezavantajlar ve iyileştirme talimatları: Bilgi damıtma, öğrencilerin ve öğretmenlerin yapısı ve ölçeği hakkında genellikle katı varsayımlara sahiptir, bu nedenle tüm uygulamaları genellemek zordur. Ek olarak, mevcut bilgi damıtma teknolojisi, büyük ölçüde softmax çıktısına dayanır ve farklı çıktı katmanlarıyla çalışamaz. İyileştirme yönü olarak öğrenciler, öğretmenin nöron / katman çıktısını taklit etmek yerine öğretmen modelinin nöron aktivasyon dizisini öğrenebilir, bu da öğrencilerin ve öğretmenlerin yapısı üzerindeki kısıtlamaları ortadan kaldırabilir (genelleme yeteneğini geliştirebilir) ve softmax çıktı katmanını azaltabilir. Bağımlılık.
Beş, tartışma
Aslında, hiçbir teknoloji en etkili DNN modelini oluşturamaz Yukarıda bahsedilen teknolojilerin çoğu birbirini tamamlayıcı niteliktedir ve aynı zamanda enerji tüketimini azaltmak, modelleri azaltmak ve doğruluğu artırmak için kullanılabilir. Yazar, yukarıdaki içeriğin analizine dayanarak makalenin sonunda 5 sonuca varır:
1) Parametre doğruluğunun ölçülmesi ve azaltılması, modelin boyutunu ve aritmetik işlemlerin karmaşıklığını önemli ölçüde azaltabilir, ancak çoğu makine öğrenimi kitaplığının manuel olarak ölçülmesi zordur. Nvidia'nın TensorRT kütüphanesi bu optimizasyon için bir arayüz sağlar.
2) Önceden eğitilmiş büyük bir DNN'yi optimize ederken, budama ve model sıkıştırma etkili seçeneklerdir.
3) Sıfırdan yeni bir DNN modeli eğitirken, modelin boyutunu ve hesaplama karmaşıklığını azaltmak için sıkıştırılmış evrişim filtreleri ve matris ayrıştırması kullanılmalıdır.
4) NAS, tek bir cihaz için en uygun DNN modelini bulmak için kullanılabilir. Birden çok şubeye sahip DNN'ler (Proxyless-NAS, MNasNet, vb.) Genellikle pahalı çekirdek başlatma ve GPU ve CPU senkronizasyonu gerektirir.
5) Bilgi damıtma, küçük ve orta ölçekli veri setlerine uygulanabilir, çünkü öğrencilerin ve öğretmenlerin DNN mimarisi hakkında daha az varsayım gerektirir ve daha yüksek doğruluğa sahip olabilir.