Today Paper | Yüksek boyutlu duyusal uzay robotu; aktif insan pozu tahmini; derin video süper çözünürlüğü; yaya yeniden tanıma vb.
Akademik gençlerin en yeni araştırma sonuçlarını ve teknolojilerini daha iyi öğrenmelerine yardımcı olmak için, AI Technology Review ve Paper Research Institute (paper.yanxishe.com) [Paper.yanxishe.com) [Paper Today] sütununu başlattı ve her gün sizin için yapay zekanın sınırlarını seçeceğiz. Akademik belgeler, çalışma referansınız içindir. Aşağıdakiler bugünün seçili içeriğidir
içindekiler
-
Nedensel Mozaik: Doğrusal Olmayan ICA ve Topluluk Yöntemi ile Neden-Sonuç Çıkarımı
-
Yüksek Boyutlu Duyusal Uzayların Robot Keşfi için İçsel Motivasyon ve Epizodik Anılar
-
Aktif İnsan Duruşu Tahmini için Derin Güçlendirmeli Öğrenme
-
Kervolutional Sinir Ağları
-
İK Optik Akış Tahminini kullanarak Derin Video Süper Çözünürlüğü
-
Derin Kişilerin Yeniden Tanımlanması için Güçlü Bir Temel ve Toplu Normalleştirme Boynu
-
FACLSTM: Sahne Metin Tanıma için Odaklanmış Dikkatli ConvLSTM
-
Örtülü Hareket Tahmini ve Telafisi için Yeni Bir Mekanizmaya Dayalı Uçtan Uca Eğitilebilir Video Süper Çözünürlük
-
TableNet: Uçtan uca Tablo algılama ve Taranan Belge Görüntülerinden Tablo veri çıkarma için Derin Öğrenme modeli
-
Karşılıklı Ortalama Öğretim: Kişi Yeniden Tanımlamada Denetimsiz Alan Uyarlaması için Sözde Etiket Rafineri
Nedensel Mozaik: Doğrusal olmayan ICA ve entegre yöntemlerle nedensel çıkarım
Kağıt adı: Nedensel Mozaik: Doğrusal Olmayan ICA ve Topluluk Yöntemi ile Neden-Sonuç Çıkarımı
Yazar: Wu Pengzhou / Fukumizu Kenji
Gönderme süresi: 2020/1/7
Kağıt bağlantısı: https://paper.yanxishe.com/review/8418
Önerilen neden: Yazar, iki değişkenli bir ortamda nedenselliği ayırt etme sorununu çözdü. Yazar, doğrusal olmayan bağımsız bileşen analizinin (ICA) en son geliştirmesine dayanarak, eklemeli olmayan gürültüye izin veren parametrik olmayan genel doğrusal olmayan bir nedensel model eğitmiştir. Ek olarak, yazar, doğrusal olmayan hibrit modeller aracılığıyla nedensel çiftleri simüle eden genel bir çerçeve, nedensel mozaik oluşturmuştur.
Yazar, bu yöntemi manuel ve gerçek dünya kıyaslama veri kümelerindeki diğer yeni yöntemlerle karşılaştırır ve yöntemi en son performansı gösterir.


Yüksek boyutlu duyusal uzay robot keşiflerinin içsel motivasyonu ve olaysal hafızası
Bildiri Başlığı: Intrinsic Motivation and Episodik Memories for Robot Exploration of High-Dimensional Sensory Spaces
Yazar: Schillaci Guido / Villalpando Antonio Pico / Hafner Verena Vanessa / Hanappe Peter / Colliaux David / Wintz Timothée
Gönderme süresi: 2020/1/7
Kağıt bağlantısı: https://paper.yanxishe.com/review/8419
Öneri nedeni: Bu makaledeki çalışma, mikro tarım robotlarının görüntü sensörleri için merak odaklı, hedefe yönelik keşif davranışları oluşturabilen bir mimari önermektedir. Derin sinir ağlarının bir kombinasyonu, düşük boyutlu özellikleri öğrenmek için görüntülerden denetimsiz çevrimdışı öğrenme için ve sistemin ters ve ileri hareketlerini temsil etmek için sığ sinir ağları için çevrimiçi öğrenme için kullanılmıştır. öğrenin. Yapay merak sistemi, bir dizi önceden tanımlanmış hedefe ilgi değerleri atar ve öğrenmenin ilerlemesini en üst düzeye çıkarması beklenenlere keşfi yönlendirir.
Yazar, genellikle yapay sinir ağlarının çevrimiçi güncellemelerini gerçekleştirirken karşılaşılan yıkıcı unutma problemleriyle başa çıkmak için epizodik belleğin içsel motivasyon sistemine entegre edilmesini önermektedir. Sonuçlarımız, bağlam depolama sisteminin kullanımının yalnızca hesaplama modelinin önceden edinilen bilgileri hızlıca unutmasını engellemekle kalmayıp, aynı zamanda modelin esnekliği ve kararlılığı arasındaki dengeyi ayarlamak için yeni bir yol sağladığını göstermektedir.




Aktif insan pozu tahmini için derin pekiştirmeli öğrenme
Kağıt adı: Aktif İnsan Duruşu Tahmini için Derin Güçlendirmeli Öğrenme
Yazar: Gärtner Erik / Pirinen Aleksis / Sminchisescu Cristian
Gönderme süresi: 2020/1/7
Kağıda bağlantı: https://paper.yanxishe.com/review/8416
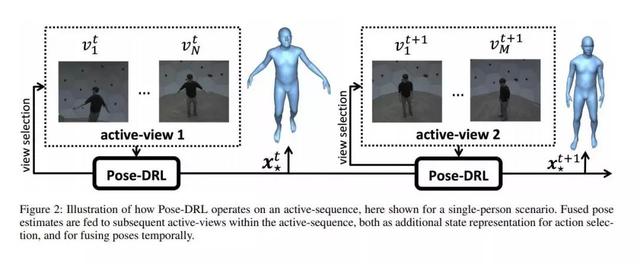
Önerinin nedeni: Mevcut 3B insan pozu tahmin yöntemlerinin tümü, bir videodan veya birden çok perspektiften toplanan sahne görüntülerinin mevcut olduğunu varsayar, bu nedenle mekansal veya zamansal bilgileri birleştirerek önceki bilgileri ve ölçüm bilgilerini kullanmaya odaklanırlar. Bu makale, aktif gözlemcinin serbestçe hareket edebileceği ve sahneyi keşfedebileceği 3B insan pozu tahmin problemini inceler ve pekiştirmeli öğrenmeye dayalı Pose-DRL adlı bir insan pozu tahmin modeli önerir. Pose-DRL, poz tahmini için uzay ve zaman boyutlarında en iyi perspektifi seçebilir. Panoptic çoklu görünüm veri setindeki deneyler, kıyaslama modeliyle karşılaştırıldığında, Pose-DRL'nin daha doğru bir poz tahmini üretebilen bir görünümü nasıl seçeceğini öğrendiğini göstermektedir.



Çekirdek evrişimli sinir ağı
Kağıt adı: Kervolutional Neural Networks
Yazar: Wang Chen / Yang Jianfei / Xie Lihua / Yuan Junsong
Gönderme süresi: 2019/4/8
Kağıda bağlantı: https://paper.yanxishe.com/review/8415
Öneri nedeni: Evrişimli sinir ağları ile ilgili mevcut araştırmaların çoğu, aktivasyon katmanına dayanır ve mevcut aktivasyon katmanı, yalnızca noktadan noktaya doğrusal olmama sağlayabilir. Bu sorunu çözmek için, bu makale, insan algılama sisteminin karmaşık davranışına yaklaşmak için çekirdek tekniklerini kullanan yeni bir çekirdek evrişimi (Kervolution) işlemi önermektedir. Çekirdek evrişim işlemi model kapasitesini geliştirir ve diğer parametreleri tanıtmadan blok-blok çekirdek işlevi aracılığıyla öğelerin yüksek sıralı etkileşimini yakalar. Çok sayıda deney, temel CNN ile karşılaştırıldığında, çekirdek evrişimine dayalı sinir ağının daha yüksek doğruluğa ve daha hızlı yakınsama hızına sahip olduğunu göstermektedir.



Optik akış rekonstrüksiyonunu kullanarak derinlik video süper çözünürlük tahmini
Kağıt adı: İK Optik Akış Tahminini kullanan Derin Video Süper Çözünürlük
Yazar: Wang Longguang / Guo Yulan / Liu Li / Lin Zaiping / Deng Xinpu / An Wei
Gönderme süresi: 2020/1/6
Kağıt bağlantısı: https://paper.yanxishe.com/review/8414
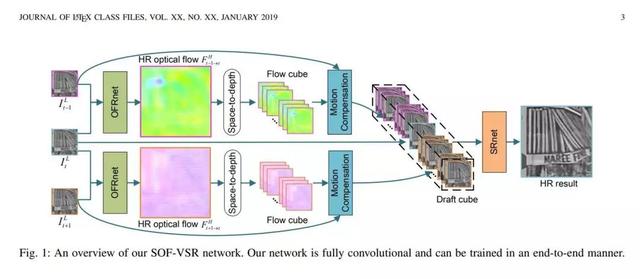
Önerilen neden: Mevcut derin öğrenmeye dayalı yöntemler genellikle zaman bağımlılığı sağlamak için düşük çözünürlüklü çerçeveler arasındaki optik akışı tahmin eder, ancak düşük çözünürlüklü optik akış ile yüksek çözünürlüklü çıktı arasındaki çözünürlük çakışması çerçeveyi engelleyecektir. Detaylar geri yüklendi. Bu sorunu çözmek için, bu makale, düşük çözünürlüklü çerçevelerden gelen optik akışın doğru zaman bağımlılığı sağladığı Optik Akış Yeniden Yapılandırma Ağı (OFRnet) adı verilen uçtan uca bir optik akış yeniden yapılandırma ağı önermektedir ve son olarak Video süper çözünürlük görevlerinin performansı iyileştirildi. Makale, zaman bağımlılığını kodlamak için hareket telafisi gerçekleştirmek için yüksek çözünürlüklü optik akış kullanır ve son düşük çözünürlüklü giriş, süper çözünürlüklü sonuçlar oluşturmak için bir süper çözünürlüklü ağın girdisi olarak kullanılacaktır. Bu makaledeki deneyler, süper çözünürlük performansını iyileştirmek için yüksek çözünürlüklü optik akışın etkinliğini kanıtlamaktadır.Vid4 ve DAVIS-10 veri setleri üzerinde yapılan deneyler de OFRnet'in SOTA performansına ulaştığını kanıtlamaktadır.




-
Derin yaya yeniden tanımlama için güçlü temel ve toplu normalleştirme yapısı
Bildiri Başlığı: Derin Kişilerin Yeniden Tanımlanması için Güçlü Bir Temel ve Toplu Normalleştirme Boynu
-
FACLSTM: Sahne metni tanımaya odaklanan ConvLSTM
Bildiri Başlığı: FACLSTM: Sahne Metin Tanıma için Odaklanmış Dikkatli ConvLSTM
-
Yeni bir örtük hareket tahmini ve telafi mekanizmasına dayalı uçtan uca eğitilebilir video süper çözünürlüğü
Bildiri Başlığı: Örtülü Hareket Tahmini ve Telafisi için Yeni Bir Mekanizmaya Dayalı Uçtan Uca Eğitilebilir Video Süper Çözünürlük
-
TableNet: Uçtan uca tablo algılama ve taranmış belge görüntülerinden tablo verilerinin çıkarılması için derin öğrenme modeli
Kağıt adı: TableNet: Uçtan uca Tablo algılama ve Taranan Belge Görüntülerinden Tablo veri çıkarma için Derin Öğrenme modeli
-
Karşılıklı ortalama öğretim: yaya yeniden tanımlamayı hassaslaştırmak için kullanılan denetimsiz alan adaptasyonu sözde etiketleri
Bildiri Başlığı: Karşılıklı Ortalama Öğretim: Kişinin Yeniden Tanımlanmasında Denetimsiz Alan Uyarlaması için Sözde Etiket Rafineri