Haberler | Google AI en son blog yayını: Video modellerinde simülasyon stratejisi öğrenimi
AI Technology Review Press Derin Güçlendirmeli Öğrenme (RL) teknolojisi, görsel girdiden karmaşık görevler için stratejiler öğrenmek için kullanılabilir ve klasik Atari2600 oyununa başarıyla uygulanmıştır. Bu alandaki son araştırmalar, Montezuma's Revenge gibi oyunların gösterdiği zorlu keşif mekanizmalarında bile insanüstü performansa ulaşabileceğini göstermiştir. Bununla birlikte, mevcut son teknoloji yöntemlerin birçoğunun sınırlamalarından biri, oyun ortamıyla çok fazla etkileşim gerektirmeleridir ve bu etkileşimler genellikle insanların nasıl oynanacağını öğrenmekten çok daha iyidir.
Son zamanlarda, Google AI, video modelinde simülasyon stratejisi öğrenme modelini tartışan bir blog yazısı yayınladı.Leifeng.com AI teknolojisi incelemesi aşağıdaki gibi derlenmiş ve düzenlenmiştir.
İnsanların bu görevleri neden daha etkili öğrenebildiklerini açıklayan bir hipotez, eylemlerinin etkilerini tahmin edebilmeleri ve böylece eylem dizisi istenen sonuca yol açacak bir modeli örtük olarak öğrenebilmeleridir. Genel fikir, sözde bir oyun modeli oluşturmak ve onu model tabanlı pekiştirmeli öğrenmenin (MBRL) ana öncülü olan seçim davranışı için iyi bir strateji öğrenmek için kullanmaktır.
"Model Tabanlı Atari Güçlendirmeli Öğrenimde", Atari oyun konsolu aracılarını eğitmek için bir MBRL çerçevesi olan SimPLe algoritmasını tanıttık ve verimliliği mevcut en son teknolojiden önemli ölçüde daha yüksek. Oyun ortamıyla yaklaşık 100 bin etkileşim kullanmak (gerçek bir kişi için 2 saatlik oyun süresine eşdeğer) rekabetçi sonuçlar gösterebilir. Ayrıca, Tensor2Tensor açık kaynak kod tabanının bir parçası olarak ilgili kodu açık kaynaklı hale getirdik. Bu sürüm, basit bir komut satırı ile çalıştırılabilen veya Atari'ye benzer bir arayüz kullanılarak oynatılabilen önceden eğitilmiş bir dünya modeli içerir.
SimPLe dünya modelini öğrenin
Genel olarak, SimPLe'nin arkasındaki fikir, dönüşümlü olarak dünya oyun davranış modelini öğrenmek ve bu modeli simüle edilmiş bir oyun ortamında stratejileri optimize etmek için kullanmaktır (modelsiz pekiştirmeli öğrenmeyi kullanarak). Algoritmanın temel ilkeleri iyi oluşturulmuş ve birçok model tabanlı pekiştirmeli öğrenme yöntemlerinde uygulanmıştır.

SimPLe'nin ana döngüsü: 1) Aracı gerçek ortamla etkileşime girmeye başlar. 2) Toplanan gözlem verileri mevcut dünya modelini güncellemek için kullanılır. 3) Temsilci, dünya modelini öğrenerek stratejiyi günceller.
Bir Atari oyun modelini eğitmek için öncelikle piksel alanında makul bir gelecek dünyası oluşturmamız gerekiyor. Başka bir deyişle, oyuna verilen bir dizi gözlemlenen çerçeve ve komut ("sol", "sağ" vb.) Girerek sonraki karenin nasıl görüneceğini tahmin etmeye çalışırız. Dünya modelini gözlem uzayında eğitmenin önemli bir nedeni, aslında bizim örneğimizde gözlem piksellerinin yoğun ve zengin bir izleme sinyali oluşturduğu bir öz denetim biçimi olmasıdır.
Böyle bir model (video tahmin aracı gibi) başarılı bir şekilde eğitilirse, kişi temelde öğrenilmiş bir oyun ortamı simülatörüne sahip olur ve oyun aracısının uzun vadeli getirisini en üst düzeye çıkarmak için bir dizi eylem seçebilir. Başka bir deyişle, stratejiyi gerçek oyundaki sıra ile eğitmek yerine, stratejiyi dünya modeli / öğrenme simülatöründen gelen sıra ile eğitiyoruz, çünkü ikincisi zaman ve hesaplama açısından çok pahalı.
Dünya modelimiz, dört veri çerçevesini kabul eden, sonraki çerçeveyi ve geri bildirimi tahmin eden ileri beslemeli bir evrişimli ağdır (yukarıya bakın). Ancak Atari'de gelecek belirsizdir çünkü yalnızca ilk dört veri çerçevesi bilinmektedir. Bazı durumlarda, örneğin oyunda dörtten fazla kareyi duraklatmak veya ping pong topu kareden kaybolduğunda, modelin sonraki kareleri başarıyla tahmin edememesine neden olabilir. Rastgelelik sorunlarıyla başa çıkmak için yeni bir video modeli mimarisi kullanıyoruz, bu mimari önceki çalışmalardan esinlenerek bu ortamda daha iyi bir iş çıkarıyor.

SimPle modeli bir Kung Fu ustasına uygulandığında, rastlantısallığın neden olduğu bir problem örneği göreceksiniz. Animasyonda sol taraf modelin çıktısı, orta kısım gerçekler ve sağ panel ikisi arasındaki piksel farkıdır.
Her bir yinelemede, dünya modeli eğitildikten sonra, bu öğrenilmiş modeli, örnek eylem dizileri, gözlemler ve sonuçlar oluşturmak için kullanırız ve oyun stratejilerini iyileştirmek için Proksimal Politika Optimizasyonu (PPO) algoritmalarını kullanırız. Önemli detaylardan biri, veri örneklemesinin gerçek veri seti çerçevesinden başlamasıdır. SimPle yalnızca orta uzunlukta veri kümeleri kullanır, çünkü tahmin hataları genellikle zamanla birikir ve bu da uzun vadeli tahminleri çok zorlaştırır. Neyse ki, PPO algoritması eylem ve geri bildirim arasındaki uzun vadeli ilişkiyi dahili sayısal işlevlerinden öğrenebilir, bu nedenle seyrek geri bildirimli oyunlar (otoyollar gibi) için sınırlı uzunlukta veri yeterlidir.
SimPLe verimliliği
Başarının bir ölçüsü, modelin verimli olduğunu kanıtlamaktır. Bu amaçla, model ve çevre arasındaki 100.000 etkileşimden sonra strateji çıktısını değerlendirdik.Bu 100.000 etkileşim, yaklaşık iki saat boyunca gerçek zamanlı bir oyun oynayan bir kişiye eşdeğerdir. SimPLe yöntemimizi ve en gelişmiş modelsiz RL yöntemlerinden ikisini 26 farklı oyunda - Rainbow ve PPO - karşılaştırdık. Çoğu durumda, SimPLe yönteminin örnekleme etkinliği diğer yöntemlerden 2 kat daha fazladır.

İki model içermeyen algoritmanın gerektirdiği etkileşim sayısı (sol: Rainbow, sağ: PPO) ve SimPLe eğitim yöntemimiz kullanılarak elde edilen puan. Kırmızı çizgi, yöntemimiz tarafından kullanılan etkileşimlerin sayısını temsil eder.
SimPLe'nin başarısı
SimPLe yönteminin sonuçları heyecan verici: Oyunlardan ikisi, Pong ve Freeway için, simüle edilmiş bir ortamda eğitilmiş temsilciler en yüksek puanları alabilir.
Freeway, Pong ve Breakout için SimPLe, aşağıdaki şekilde gösterildiği gibi piksel düzeyinde mükemmel tahmine yakın 50 adıma kadar üretebilir.
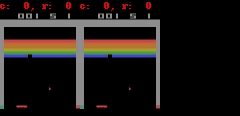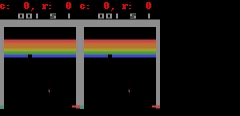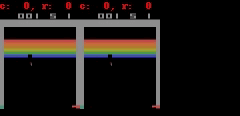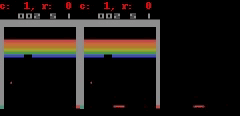

SimPLe, piksellere yakın mükemmel tahminler yapabilir. Her animasyonda sol, modelin çıktısı, orta kısım temel gerçekler ve sağdaki bölme iki animasyon arasındaki piksel farkıdır.
SimPLe sürpriz
Ancak SimPLe her zaman doğru tahminlerde bulunmaz. En yaygın başarısızlık, dünya modelinin küçük ancak birbiriyle oldukça ilişkili nesneleri doğru bir şekilde yakalayamaması veya tahmin edememesidir. Örneğin, Atlantis tiyatrosunda mermiler o kadar küçüktür ki yok olma eğilimindedirler.

Savaş alanında, modelin mermiler gibi küçük ilgili parçaları tahmin etmesini zor bulduk.
sonuç olarak
Model tabanlı pekiştirmeli öğrenme yöntemleri, esas olarak, çoklu robot görevleri gibi yüksek etkileşim maliyetleri, yavaş hız veya manuel etiketleme olan ortamlarda kullanılır. Böyle bir ortamda, öğrenilen simülatör, temsilcinin ortamını daha iyi anlayabilir ve çok görevli pekiştirmeli öğrenme için daha yeni, daha iyi ve daha hızlı yöntemler sağlayabilir. SimPLe, standart model içermeyen RL yönteminin performans gereksinimlerini karşılamasa da, aslında daha etkilidir ve gelecekte model tabanlı teknolojinin performansını daha da iyileştirmeyi umuyoruz.
Kendi modellerinizi ve deneylerinizi geliştirmek istiyorsanız, lütfen çalışmamızı birlikte yeniden üretmek için önceden eğitilmiş dünya modelini nasıl kullanacağınıza dair talimatları bulabileceğiniz bilgi tabanımıza ve çalışma grubumuza gidin.
İlgili kağıt adresi:
https://arxiv.org/abs/1903.00374
üzerinden:
https://ai.googleblog.com/2019/03/simulated-policy-learning-in-video.html

Tıklamak Orijinali okuyun , Görünüm Google açık kaynak pekiştirme öğrenme derin planlama ağı PlaNet