AAAI 2020 | Çin Bilimler Akademisi Bulut Teknolojisi: Sınıflandırma performansını iyileştirmek için birden çok zayıf etiket kullanan çift görünümlü sınıflandırma

Yazar | Yuncong Technology Editör | Camel Bu makale, Çin Bilimler Akademisi Bilgi Teknolojisi Enstitüsü ve Yuncong Teknolojisi tarafından ortaklaşa tamamlanan ve AAAI2020 tarafından kabul edilen "Çoklu Gürültülü Açıklayıcılardan Öğrenen Çift Görünümlü Derin Sınıflandırıcı" makalesinin bir yorumudur.

Son yıllarda, derin öğrenme çeşitli sınıflandırma görevlerinde etkinliğini kanıtlamıştır.Örneğin, derin sinir ağları (DNN), iyi sonuçlarla etiketli veriler üzerinde risk kontrol modellerini eğitmek için kullanılmaktadır. Ancak video gözetimi ve gerçek sahnelerin tıbbi görüntü teşhisi gibi birçok gerçek durumda, net ve doğru ek açıklamalar toplamak zordur.
Yuncong Technology ve Çin Bilimler Akademisi Bilgi Teknolojileri Enstitüsü, derin öğrenme sınıflandırması için birden çok zayıf etiketin bilgilerini etkili bir şekilde kullanabilen bir yöntemi araştıran ve birden çok kişiden gürültülü bir açıklama öneren "Çift Görünümlü Derin Sınıflandırıcı Çoklu Gürültülü Açıklayıcılardan Öğrenme" adlı yayını yayınladı. Etiketlerde derin sınıflandırıcı öğrenmenin yeni bir yöntemi.
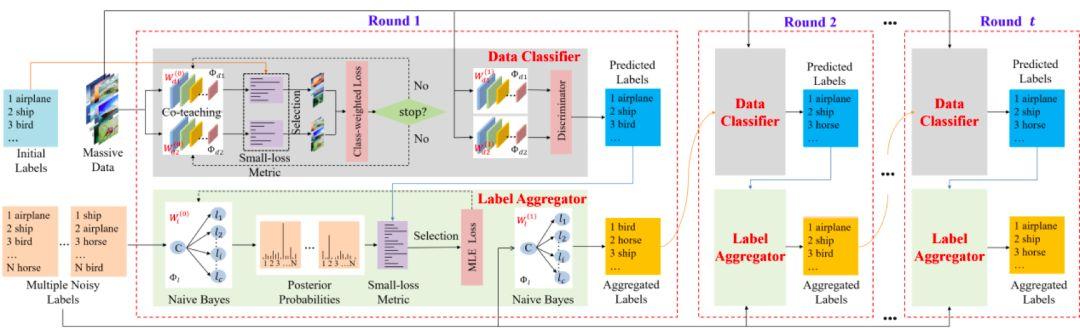
Bu yazıda, birden fazla kişi tarafından etiketlenen gürültülü etiketlerden öğrenilen derin sinir ağı sınıflandırması problemini incelemeye odaklanıyoruz ve beklenti maksimizasyonu algoritmasının yinelemeli tahmin sürecini etiket görünümleri ile veri görünümleri arasında karşılıklı bir öğrenme problemi olarak görüyoruz (Şekil 1). İki görünümün sırasıyla diğer görünüm tarafından oluşturulan sözde etiketleri öğrenmesine izin vererek bu sorunu denetimli bir öğrenme problemine dönüştürüyoruz ve sözde etiketleri ve model parametrelerini yinelemeli olarak güncelleyerek iki görünümün birbirinden öğrenmesini sağlıyoruz. Önerdiğimiz yöntem (CVL olarak adlandırılır) yanlış etiketlerin fazla takılmasını azaltır ve daha istikrarlı bir yakınsama performansına sahiptir.
Yeni yöntem, derin öğrenmenin ikili görünüm sınıflandırma algoritmasına dayanmaktadır ve modelleme için birden çok zayıf etiketin bilgisinden tam olarak yararlanmaktadır.Güvenlik dağıtımı ve kontrolü, iş riski kontrolü, finansal güvenlik ve diğer alanlarda uygulanabilir, bu da güvenlik seviyesini ve risk kontrol işini etkili bir şekilde geliştirebilir. Güvenlik alanındaki yenilikçi uygulamalara karşılık gelir Birleştirmek , Güvenlik denetimi sisteminin güçlendirilmesini önemli ölçüde geliştirmek, güvenlik savaş yeteneklerini daha verimli bir şekilde geliştirmek ve güvenlik çalışmalarının verimliliğini artırmak. Aynı zamanda finansal risk kontrolü, yenilikçilik ve güvenlik alanlarında da teknik olarak istikrarlı etkilere sahiptir.
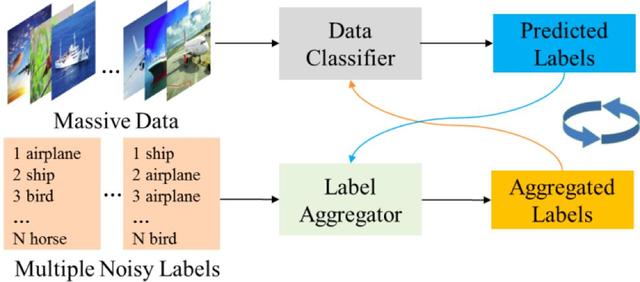
Şekil 1: Yeni yöntem araştırma mantık modeli
Yeni algoritmaya genel bakış
Yeni algoritma, sırasıyla özellik alanında ve etiket alanında sınıflandırıcılar oluşturmaya çalışır.Eğitim süreci sırasında, iki sınıflandırıcının sonuçları birbirini yönlendirir ve denetler ve alternatif yinelemeli güncellemeler yoluyla, kararlı performansa sahip bir sınıflandırıcı nihayet eğitilir.
Deneyler, iki sentetik veri seti (MNIST ve CIFAR10) ve bir gerçek veri seti (LabelMe-AMT) üzerinde gerçekleştirildi.Son karşılaştırma sonuçları, CVL yönteminin etkinlik, sağlamlık ve kararlılık açısından diğer algoritmalardan üstün olduğunu göstermektedir.
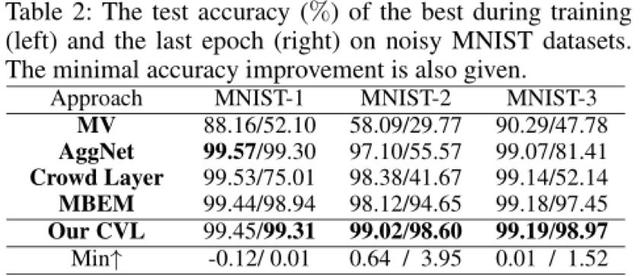
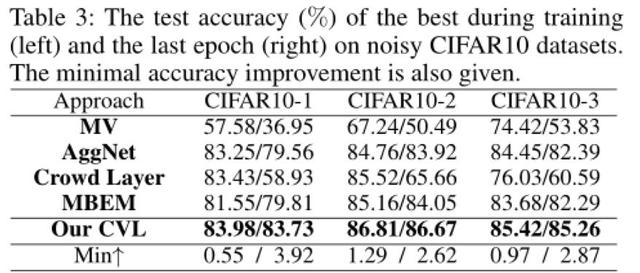
Şekil 2. Şekil 3: Sentetik veri kümeleri mnist ve cifar10 üzerinde yapılan deneyler, yöntemimiz etkinlik ve sağlamlık açısından diğer mevcut teknoloji örneklerinden daha iyi performans gösteriyor

Şekil 4: Yöntemimiz yakınsamanın kararlılığı açısından diğer algoritmalardan daha üstündür
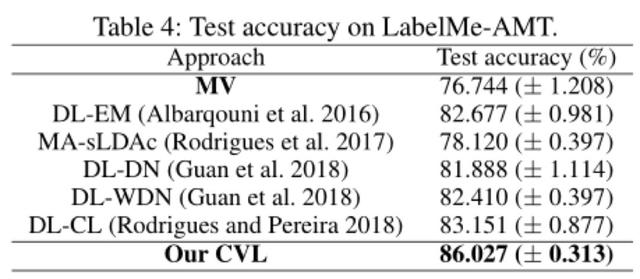
Şekil 5: Gerçek veri seti LabelMe-AMT'de, sonuçlarımız diğer mevcut algoritmalardan önemli ölçüde öndedir
Yöntem yorumlama
Öncelikle, üzerinde çalıştığımız zayıf denetim problemini iki görüşün karşılıklı öğrenme problemine dönüştürebiliriz:
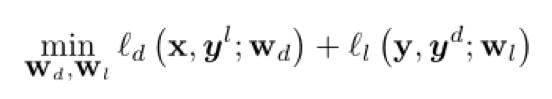
Başlatma ve ön eğitimden sonra, bu sorun, dönüşümlü olarak güncellenen tahmini etiketlerin ve birleştirilmiş etiketlerin gözetimi altında alternatif optimizasyonla çözülebilir. Bu ikili bakış açısı, etiket toplayıcıların ve veri sınıflandırıcıların birbirleriyle bilgi alışverişi yapmaları için basit ve çok yönlü bir yol sağlar.
Daha sonra, karşılıklı öğrenmenin iyi ve istikrarlı sonuçlara yakınlaşmasını sağlamak için iki öğrenme görüşünde birkaç strateji benimsedik.
1. Sekme görünümü Temel model. Her açıklayıcının etiket gürültüsünün rastgele ve bağımsız olduğunu varsayarsak, öğrenme parametresi olarak gürültü karışıklık matrisine sahip saf bir Bayes sınıflandırıcı kullanırız. Gürültü karışıklık matrisi ve önceki dağıtım kategorisi q değişmediğinde, i'inci numunenin k'inci kategorisinin son olasılığı aşağıdaki formülle hesaplanabilir:
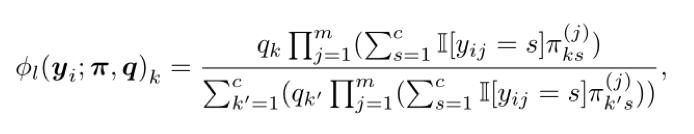
Modeli eğitin. İki görünümün eğitimi, görüş yetersizliği sorunuyla karşılaşacaktır, bu da görünümün sağladığı bilgilerin tüm örnekleri tam ve mükemmel bir şekilde tahmin etmek için yeterli olmadığı ve kaçınılmaz olarak tahmin hataları oluşacağı anlamına gelir. Bu faktörün etkisini azaltmak için, ölçüm etiketinin güven düzeyi olarak küçük kayıp metriğini kullanırız ve örneği seçeriz.
Etiket görünümünde, küçük kayıp metriğini kullanarak etiketi seçtikten sonra maksimum olasılık tahmini kaybı aşağıdaki gibidir:
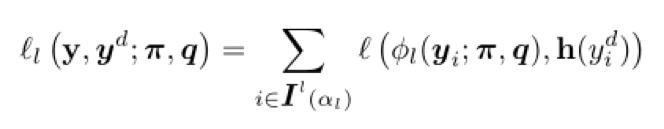
Kayıp fonksiyonuna göre, parametresi aşağıdaki formülle tahmin edilebilir:
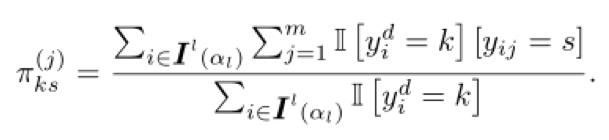
Ayrıca bilinen sınıf dengesi durumunda ayarlayın.
Toplama etiketini güncelleyin. Her turda, etiket görünümü sözde etiketini bir kez günceller:
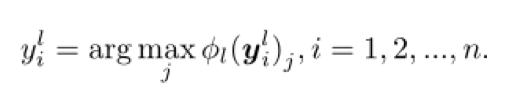
2. Veri görünümü Temel model. Derin ağların yüksek öğrenme yeteneği nedeniyle, veri sınıflandırıcı olarak sinir ağlarını seçiyoruz.
Sınıflandırıcıyı eğitin. Aynı küçük zarar metriğini kullanmanın yanı sıra, iki strateji de öneriyoruz. Her şeyden önce, derin ağ yüksek bir kapasiteye sahip olduğundan ve keyfi verilere uyabildiğinden, küçük bir kayıp ölçüsü kullandıktan sonra, farklı şekilde başlatılacak ve farklı yanlış seçim önyargılarına neden olacaktır. Bu etkiyi azaltmak için işbirliğine dayalı bir öğretim stratejisi benimsedik. Bunun anlamı
Aynı yapıya sahip ancak farklı başlatmalara sahip iki ağ kullanın ve her grupta, her ağ, seçilmiş küçük kayıp örneklerini yararlı bilgi olarak görür ve bu tür örnekleri eşler arası ağına gerçekleştirmeyi öğretir Parametreleri güncelleyin. İki ağın farklı öğrenme yetenekleri olduğundan, gürültülü etiketlerin neden olduğu farklı türdeki hatalar filtrelenebilir. İkinci olarak, seçilen örnekler genellikle dengesiz olduğundan, sınıf dengesi kısıtı eklenmelidir. Derin sınıflandırıcılar için, yöntemimiz her partide numuneler seçtiğinden, ağın belirli kategorileri fazla tercih etmesini önlemek için her partide dinamik kategori ağırlık kaybı gerçekleştiriyoruz.
Eğitim sürecinde, her çağda, önce karıştırıp p partilere ayırıyoruz ,, (k = 1, 2, ..., p). Daha sonra iki ağ, eşler arası ağdan öğrenmek için her partide kendi küçük kayıp numune setlerini seçer. K'inci partinin kayıp fonksiyonu aşağıdaki gibidir:
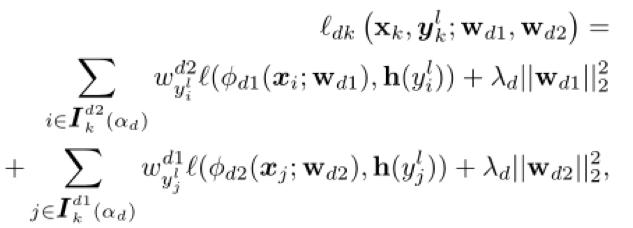
Tahmin etiketini güncelleyin. Her turda, iki ağın çıktı sınıflandırma sonuçları ve sırasıyla olduğunda, veri görünümü etiketi aşağıdaki formülle günceller.
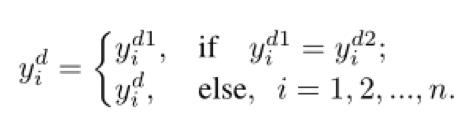
AAAI 2020 Bildirileri: AAAI 2020 Kağıt Yorumlama Toplantısı @ (PPT ile indir )